Cluster Administration Storage Tools (CAST)¶
CAST is comprised of several open source components:
Cluster System Management (CSM)
Cluster System Management (CSM) is a cognitive self learning system for managing and overseeing a HPC cluster. CSM interacts with a variety of open source IBM tools for supporting and maintaining a cluster, such as:
- Discovery and management of system resources
- Database integration (PostgreSQL)
- Job launch support (workload management, cluster, and allocation APIs)
- Node diagnostics (diag APIs and scripts)
- RAS events and actions
- Infrastructure Health checks
- Python Bindings for C APIs
Burst Buffer
The Burst Buffer is an I/O data caching technology which can improve I/O performance for a large class of high-performance computing applications without requirement of intermediary hardware.
Burst Buffer provides:
- A fast storage tier between compute nodes and the traditional parallel file system
- Overlapping job stage-in and stage-out of data for checkpoint and restart
- Scratch volumes
- Extended memory I/O workloads
- Usage and SSD endurance monitoring
Table of Contents¶
Cluster System Management (CSM)¶

CSM is a cognitive self learning system for managing and overseeing a HPC cluster. CSM interacts with a variety of open source IBM tools for supporting and maintaining a cluster, such as:
- Discovery and management of system resources
- Database integration (PostgreSQL)
- Job launch support (workload management, cluster, and allocation APIs)
- Node diagnostics (diag APIs and scripts)
- RAS events and actions
- Infrastructure Health checks
- Python Bindings for C APIs
Table of Contents
User Guide¶
This is a user guide. READ THIS FIRST
Introduction¶
The purpose of this document is to familiarize the system administrator with Cluster System Management (CSM), and act as a reference for when CSM Developers can not be reached.
CSM is developed for use on POWER systems to provide a test bed for the CORAL specific software on non-production systems. This will allow the national laboratories to provide early feedback on the software. This feedback will be used to guide further software development. These POWER systems consist of:
- Witherspoon as compute and utility (Login, Launch and Workload manager) nodes
- Boston as management node and Big Data Store
This document assumes POWER systems are fully operational and running Red Hat Pegas 1.0 or higher.
Functions and Features¶
CSM includes support for the following functions and features:
- CSM API support for Burst Buffer, diagnostics and health check, job launch, node inventory, and RAS.
- CSM DB support for CSM APIs, diagnostics and health check, job launch, node inventory, and RAS.
- CSM Infrastructure support for CSM APIs, job launch, node inventory, and RAS.
- RAS event generation, actions, and query.
- Diagnostics and Health Check framework support for CSM prolog/epilog, HTX exercisers.
Restrictions, Limitations, and Known Issues¶
CSM does not include support for the following items:
- Shared allocation
Known Issues:
- Whenever CSM is upgraded to a new version, all software that is dependent on CSM must be restarted. LSF and Burst Buffer have daemon processes that must be restarted. JSM is also dependent on CSM, but does not include any daemon processes that need to be explicitly restarted.
- CSM does not support rpm upgrade (rpm –U), uninstall and re-install is required.
- CSM API responses failing with the error: “recvmsg timed out. rc=-1” when the response message to the API grows beyond the maximum supported message size. To work around this issue reduce the number of returned records adding addition filters and/or using the limit option on the API.
- There are several daemons that all start during system boot when enabled via systemd (xcatd, nvidia-persistenced, dcgm, csmd-master, csmd-aggregator, csmd-utility, csmd-compute, csmrestd, ibmpowerhwmon). Currently the startup of these daemons does not occur in controlled fashion. As a temporary workaround, it may be required to start these services using a script that inserts appropriate wait times between dependent daemons.
- Chance of CSM daemon ID of collision
- There’s a
1:3.4*10^36chance that generated daemonIDs collide. The csm_infrastructure_health_check performs a uniqueness-test to confirm that this didn’t happen.Reporting issues with CSM¶
To obtain support and report issues with CSM, please contact IBM Support Service.
CSM Installation and configuration¶
When you are ready to install CSM, please see the Installation and Configuration, which can be found on Box site. At this point in time we suggest installing CSM. The following chapters of this user guide provide additional knowledge and reference for sub systems of CSM.
CSM Database¶
Sorry! This section has moved, but this page has been kept for external link references. For more details please visit: Database.
CSM Infrastructure¶
Note
This page is under re-work and moving to: Infrastructure.
Overview¶
The Cluster System Management (CSM) infrastructure consists of master, aggregator, utility, and compute daemons.
The CSM master daemon runs on the management node. Aggregators run on the service nodes (optional: run on management node too). The CSM utility daemon runs on the login and launch node. The CSM compute daemon runs on the compute node. This is illustrated below:

As shown above, all daemons communicate directly point to point. The compute daemon communicates directly to one aggregator daemon (the primary) and can be configured to connect to a secondary aggregator for fault tolerance however, almost all communication will go through the primary. The aggregator communicates directly to the master daemon. The utility daemon communicates directly to the master daemon. Only the master daemon is allowed to communicate to the CSM database.
Configuration¶
Each type of daemon has its own configuration file. Default configuration files can be found here:
/opt/ibm/csm/share/etcCSM Daemons and Corresponding Configuration Files
Master Daemon Aggregator Daemon Utility Daemon Compute Daemon If edits are made to a configuration file, then a daemon must be killed and started again.
A detailed explanation of configuration settings can also be found at: Infrastructure and also at: CSMD Configuration.
Daemon Functionality¶
Master daemon¶
CSM master daemon runs on the management node and supports the following activities:
- CSM DB access
- CSM API support
- CSM RAS master functions
Aggregator daemon¶
The CSM aggregator daemon runs on the management node and facilitates communication between the master daemon and the compute daemons. The aggregator daemon supports the following activities:
- Forwarding all the messages from the compute daemons on compute nodes to the master daemon on the management node without any aggregation functionally.
- Supporting the fan-out of internal CSM multicast messages from the master daemon to a list of compute nodes.
- Keep track of active and inactive compute nodes during its livetime. (This data is not persisted. Therefore, if an aggregator is restarted, this info is only partially recaptured based on the current active set of compute nodes.)
- Allow CSM clients to call APIs similar to the utility daemon functionality.
- Allows to connect to Logstash and send environmental data.
A new connection from compute nodes is considered a secondary connection until the compute node tells the aggregator otherwise. This assures that any messages along the secondary path between compute nodes and master get filtered.
Utility daemon¶
The CSM utility daemon runs on the login and launch nodes and supports the following activities:
- Node discovery
- Node inventory
- Steps
- CSM API support
- Environmental data collection
Compute daemon¶
The CSM compute daemon run on the compute node and support the following activities:
- Node discovery
- Node inventory
- Allocation create and delete
- Environmental data bucket execution
- Preliminary environmental data collection (only GPU data)
- Aggregator failover
The CSM compute, aggregator and utility daemons collect the node inventory and send it to the CSM master daemon where it is stored in the CSM DB. This collection process takes place every time the CSM daemon starts or reconnects after a complete disconnect.
The daemons support authentication and encryption via SSL/TLS. To enable, the administrator has to configure the daemons to use SSL. The CA and certificate files have to be the same for use with point-to-point connections between all daemons.
All daemons are enabled to schedule predefined environmental data collection items. Each of the items can be part of buckets where each bucket can be configured with an execution interval. Currently, CSM only has only one predefined bucket for GPU data collection on the compute and utility daemons.
Compute nodes are able to connect to two aggregators if configured. The compute daemon will try to connect to the first configured aggregator. If this succeeds it will also establish the connection to the secondary aggregator and will then be fully connected. If a secondary aggregator fails, the compute will keep the regular operation with the primary and try to reconnect to the secondary in a preset interval (~10s). If and only if a primary aggregator fails, the compute daemon will perform an automatic failover by telling its current secondary aggregator to take over the role as the primary for this compute node. If the initial primary aggregator restarts, the compute node will connect to it as a secondary. It will only switch to the other aggregator if the currently active primary connection fails. This behavior has an important system level consequence: once a primary aggregator fails and gets restarted there’s currently no other way to restore the configured aggregator-compute relation without restarting the compute daemon.
API Timeout Configuration¶
This section has been moved to: API Configuration
Daemon-to-Daemon Heartbeat¶
This section has been moved to: The Network[net] Block
Compute node states¶
CSM Daemon States¶ State Ready Comments DISCOVERED No First time CSM sees the node. IN_SERVICE Yes Node is healthy for scheduler to use. This is the only state scheduler consider the node for scheduling. ADMIN_RESERVE No Reserved for system administrator activities. Processes RAS events. MAINTENANCE No Reserved for system administrator activities. Does NOT process RAS events. SOFT_FAILURE No CSM reserved. HARD_FAILURE No CSM reserved. OUT_OF_SERVICE No Hardware / Software problem. Does NOT process RAS events.
CSM Daemon State Transitions¶ Number Start State End State Comments 1 DISCOVERED By CSM inventory 2 DISCOVERED IN_SERVICE By system admin action 3 IN_SERVICE ADMIN_RESERVE By system admin action 4 ADMIN_RESERVE IN_SERVICE By system admin action 5 IN_SERVICE MAINTENANCE By system admin action 6 MAINTENANCE IN_SERVICE By system admin action 7 IN_SERVICE OUT_OF_SERVICE By system admin action 8 OUT_OF_SERVICE IN_SERVICE By system admin action 9 HARD_FAILURE OUT_OF_SERVICE By system admin action 10 HARD_FAILURE IN_SERVICE By system admin action 11 IN_SERVICE SOFT_FAILURE By CSM RAS subsystem 12 DISCOVERED HARD_FAILURE By CSM RAS subsystem 13 IN_SERVICE HARD_FAILURE By CSM RAS subsystem 14 DISCOVERED SOFT_FAILURE By CSM RAS subsystem 15 SOFT_FAILURE IN_SERVICE CSM soft recovery Below is a visual graph of daemon state transitions. The numbers in this graph correspond to the number in column 1 of the CSM Daemon State Transitions table shown above.

Job Launch¶
Any jobs submitted to LSF queues will use the integrated support between LSF and Cluster System Management (CSM). Depending on the user specifications this integration may also include JSM and Burst Buffer.
There are few steps required before a job can be launched:
- The CSM Infrastructure needs to be operational. CSM master, aggregator, utility, and compute daemons need to be up and operational.
- The CSM compute daemons must collect inventory on the compute nodes and update the CSM Database.
- The system administrator must change the state of the compute node to
IN_SERVICE, using the command line interface of the CSM API csm_node_attributes_update.$ /opt/ibm/csm/bin/csm_node_attributes_update –s IN_SERVICE -n c650f02p09CSM REST Daemon¶
Overview¶
The CSM REST daemon (csmrestd) is optional and is not required for normal cluster operation. Csmrestd is used to enable RAS events to be created from servers that do not run CSM infrastructure daemons. The CSM REST daemon can be installed on the service nodes to allow BMC RAS events to be reported by the IBM POWER LC Cluster RAS Service (ibm-crassd).
Packaging and Installation¶
All required binaries, configuration files, and example scripts are packaged in
ibm-csm-restd-1.8.2-*.ppc64le.rpm. To install and configure csmrestd, please refer to Installation and Configuration.Creating a CSM RAS event via the REST API¶
Once csmrestd is installed and configured on the management node, an example RAS event can be created from any server that can reach the csmrestd server ip address. This test can be run locally on the management node or from any other node.
By default the CSM RAS msg type settings for the event created by the create_node_leave_event.sh example script will not impact the cluster. However, this event may be fatal in future releases. In future releases, this test may cause a node to be removed from the list of nodes ready to run jobs.
On a service node:
Copy the sample script from
/opt/ibm/csm/share/rest_scripts/spectrum_scaleto some other location for editing.$ cp /opt/ibm/csm/share/rest_scripts/spectrum_scale/create_node_leave_event.sh ~/Edit the copy of create_node_leave_event.sh and replace
__CSMRESTD_IP__with the IP address that was configured for csmrestd to listen on in /etc/ibm/csm/csmrestd.cfg. Optionally, theLOCATION_NAMEcan also be modified to refer to a real node_name in the csm_node table. Start the local CSM daemon, then csmrestd if either of them are not currently running.$ systemctl start csmd-aggregator $ systemctl start csmrestdRun the example script and observe a new event get created in /var/log/ibm/csm/csm_ras_events.log:
$ ~/create_node_leave_event.sh $ cat /var/log/ibm/csm/csm_ras_events.log | grep spectrumscale.node.nodeLeaveExample output:
{"time_stamp":"2017-04-25 09:48:37.829407","msg_id":"spectrumscale.node.nodeLeave", "location_name":"c931f04p08vm03","raw_data":"","ctxid":"9","min_time_in_pool":"1", "suppress_ids":"","severity":"WARNING","message":"c931f04p08-vm03 has left the cluster.","decoder":"none","control_action":"NONE","description":"The specified node has left the cluster.","relevant_diags":"NONE","threshold_count":"1","threshold_period":"0"}Stop csmrestd:
$ systemctl stop csmrestdInstallation and Configuration¶
This is how to install and configure Cluster System Management (CSM).
This is a guide. READ THIS SECOND
Introduction¶
The purpose of this document is to guide the system administrator through the installation and configuration of Cluster System Management (CSM).
CSM is developed for use on POWER systems only. These POWER systems consist of:
- Witherspoon as compute and utility (Login, Launch and Workload manager) nodes
- Boston as management nodes and Big Data Store
This document assumes POWER systems are fully operational and running Red Hat Pegas 1.0 or higher.
To obtain support for CSM, please contact IBM Support Service.
Pre-Requisites¶
All nodes participating in Cluster System Management (CSM) must be running Red Hat Enterprise Linux for PPC64LE.
Software Dependencies¶
CSM has software dependencies. Verify that the following packages are installed:
Hard dependencies¶
Without these dependencies CSM cannot run.
Hard Dependencies¶ Software Version Comments xCAT 2.16.1 Postgres SQL 10.6 xCAT document for migration openssl-libs 1.1.1c-15 perl-YAML 1.24-3 Required by the Diagnostic’s tests. perl-JSON 2.97.001-2 Required by the Diagnostic’s tests that get information from the UFM. cast-boost 1.66.0-7 Found on Box Already bumped up on rhels 8 CSM uses the version of boost RPMS included with the OS instead of the custom built cast-boost RPMS used of rhels 7 P9 Witherspoon firmware level
- BMC: ibm-v2.3-476-g2d622cb-r33-coral-cfm-0-gb2c03c9
- Host: IBM-witherspoon-OP9_v2.0.14_1.2
Found on Box Note
this seems wrong. ( P9 Witherspoon firmware level) What is BMC? what is host? should those be 2 seperate software values and not a ‘version’?
Soft Dependencies¶
These dependencies are highly suggested.
Soft Dependencies¶ Software Version Comments NVIDIA DCGM datacenter-gpu-manager-2.0.10-1.ppc64le Needed by:
- Diagnostics and health check
- CSM GPU inventory
- All nodes with GPUs.
NVIDIA Cuda Toolkit cuda-toolkit-11-0-11.0.3-1.ppc64le Needed by:
- All nodes with GPUs.
NVIDIA Driver cuda-drivers-450.80.02-1.ppc64le Needed by:
- Needed by NVIDIA Data Center GPU Manager (DCGM).
- All nodes with GPUs.
IBM HTX htxrhel8-574-LE.ppc64le.rpm Needed by:
- Diagnostics and health check
- All nodes.
HTX requires:
- net-tools package (ifconfig command)
- mesa-libGLU-devel and mesa-libGLU packages
Spectrum MPI 10.4.0.2 Needed by the Diagnostic tests:
- dgemm
- dgemm-gpu
- jlink
- daxpy tests
Spectrum MPI requires:
- IBM ESSL (IBM Engineering and Scientific Subroutine Libray)
- IBM XL Fortran
sudo sudo-1.8.29-5.el8.ppc64le Required by the Diagnostic’s tests that needs to run as root lm-sensors 3.4.0 Required by the Diagnostic’s temperature tests. Software with dependencies on CSM¶
Dependencies on CSM¶ Software Version Comments Spectrum LSF 10.1 (With SP 4.0 Update) Burst Buffer 1.8.2 IBM POWER HW Monitor ibm-crassd-0.8-15 or higher If installed on the service nodes, ibm-crassd can be configured to create CSM RAS events from BMC sources via csmrestd. IBM Spectrum LSF (LSF), Burst Buffer (BB), and Job Step Manager (JSM) all have dependencies on CSM. Whenever a new version of CSM is installed, all dependent software must be restarted to reload the updated version of the CSM API library.
If any of these packages are not already installed or for more information about these packages, please refer to CORAL Software Overview (CORAL_Readme_v1.0.dox) located in Box. In this document you will find where these packages are located and how to install them.
Updating from a previous version¶
CSM 1.5.0 does support incremental upgrades, fixes, and patches from prerelease versions (for example, from CSM 1.4.0 to CSM 1.5.0). System administrator should follow CSM database schema migration steps describe at:
https://cast.readthedocs.io/en/latest/csmdb/csm_db_schema_version_upgrade_19_0_sh.html
Installation¶
List of CSM RPMs¶
The following RPMs are all of the required RPMs for Cluster System Management (CSM). These RPMs can be found on Box in the same folder as this document. Please verify that you have all required RPMs.
For CSM, all CSM rpms have a version of ibm-csm-component-1.8.2-commit_sequence.ppc64le.rpm, for example, ibm-csm-core-1.8.2-3566.ppc64le.rpm. The commit_sequence portion is an increasing value that changes every time a new commit is added to the repository. Because the commit_sequence changes so frequently, this document makes use of a wildcard for this portion of the rpm name.
ibm-csm-core holds CSM infrastructure daemon and configuration file examples.
ibm-csm-api holds all CSM APIs and the corresponding command line interfaces.
ibm-csm-hcdiag holds the diagnostics and health check framework with all available tests interface.
ibm-csm-db holds CSM DB configuration files and scripts.
ibm-csm-bds holds BDS configuration files, scripts, and documentation.
ibm-csm-bds-logstash holds logstash plugins, configuration files and scripts.
ibm-csm-bds-kibana holds kibana plugins, configuration files and scripts.
ibm-csm-restd holds the CSM REST daemon, configuration file example, and a sample script.
Below is a chart indicating where each of these RPMs must be installed.
Install guide for RPMs¶ Management Node Service Node Login Node Launch Node Compute Node ESS Servers UFM Servers BDS Servers ibm-csm-core x x x x x ibm-csm-api x x x x x ibm-csm-hcdiag x x x x x ibm-csm-db x ibm-csm-bds x ibm-csm-bds-logstash x x ibm-csm-bds-kibana x ibm-csm-restd x x Installing CSM onto the Management Node¶
On the management node:
Install the cast-boost RPMs, which can be found on Box
$ rpm -ivh cast-boost-*.rpmInstall the flightlog RPM and the following CSM RPMs, which can be found on Box.
- ibm-flightlog
- ibm-csm-core
- ibm-csm-api
- ibm-csm-db
- ibm-csm-bds
- ibm-csm-hcdiag
- ibm-csm-restd
$ rpm -ivh ibm-flightlog-1.8.2-*.ppc64le.rpm \ ibm-csm-core-1.8.2-*.ppc64le.rpm \ ibm-csm-api-1.8.2-*.ppc64le.rpm \ ibm-csm-db-1.8.2-*.noarch.rpm \ ibm-csm-bds-1.8.2-*.noarch.rpm \ ibm-csm-hcdiag-1.8.2-*.noarch.rpm \ ibm-csm-restd-1.8.2-*.ppc64le.rpmInstalling CSM onto the Service Nodes¶
For service nodes, CSM supports diskless and full disk install:
Diskless¶
Clone existing images, add the following packages to the “otherpkgs” directory and list, then run genimage. See Appendix 7.1 for more details.
cast-boost-* ibm-flightlog-1.8.2-*.ppc64le ibm-csm-core-1.8.2-*.ppc64le ibm-csm-api-1.8.2-*.ppc64le ibm-csm-bds-1.8.2-*.noarch ibm-csm-bds-logstash-1.8.2-*.noarch ibm-csm-hcdiag-1.8.2-*.noarch ibm-csm-restd-1.8.2-*.ppc64leFull Disk¶
Install the cast-boost RPMs, which can be found on Box
$ rpm -ivh cast-boost-*.rpmInstall the flightlog RPM and the following CSM RPMs, which can be found on Box.
- ibm-flightlog
- ibm-csm-core
- ibm-csm-api
- ibm-csm-bds
- ibm-csm-bds-logstash
- ibm-csm-hcdiag
- ibm-csm-restd
$ rpm -ivh ibm-flightlog-1.8.2-*.ppc64le.rpm \ ibm-csm-core-1.8.2-*.ppc64le.rpm \ ibm-csm-api-1.8.2-*.ppc64le.rpm \ ibm-csm-bds-1.8.2-*.noarch.rpm \ ibm-csm-bds-logstash-1.8.2-*.noarch.rpm \ ibm-csm-hcdiag-1.8.2-*.noarch.rpm \ ibm-csm-restd-1.8.2-*.ppc64le.rpmInstalling CSM onto the Login, Launch, and Workload manager Nodes¶
For login, launch and workload manager nodes, CSM supports diskless and full disk install:
Diskless¶
Clone existing images, add the following packages to the “otherpkgs” directory and list, then run genimage. See Appendix 7.1 for more details.
cast-boost-* ibm-flightlog-1.8.2-*.ppc64le ibm-csm-core-1.8.2-*.ppc64le ibm-csm-api-1.8.2-*.ppc64le ibm-csm-hcdiag-1.8.2-*.noarchFull Disk¶
Install the cast-boost RPMs, which can be found on Box
$ rpm -ivh cast-boost-*.rpm
- ibm-flightlog
- ibm-csm-core
- ibm-csm-api
- ibm-csm-hcdiag
$ rpm -ivh ibm-flightlog-1.8.2-*.ppc64le.rpm \ ibm-csm-core-1.8.2-*.ppc64le.rpm \ ibm-csm-api-1.8.2-*.ppc64le.rpm \ ibm-csm-hcdiag-1.8.2-*.noarch.rpmInstalling CSM onto the Compute Nodes¶
For compute nodes, CSM supports diskless and full disk install:
Diskless¶
Clone existing images, add the following packages to the “otherpkgs” directory and list, then run genimage. See Appendix 7.1 for more details.
cast-boost-* ibm-flightlog-1.8.2-*.ppc64le ibm-csm-core-1.8.2-*.ppc64le ibm-csm-api-1.8.2-*.ppc64le ibm-csm-hcdiag-1.8.2-*.noarchFull disk¶
Install the cast-boost RPMs, which can be found on Box.
Note: replace “/path/to/rpms” with the appropriate location for your system.
$ xdsh compute "cd /path/to/rpms; rpm -ivh cast-boost-*.rpm"Install the flightlog RPM and the following CSM RPMs, can be found on Box.
Note: replace
/path/to/rpmswith the appropriate location for your system.
- ibm-flightlog
- ibm-csm-core
- ibm-csm-api
- ibm-csm-hcdiag
$ xdsh compute "cd /path/to/rpms; \ rpm -ivh ibm-flightlog-1.8.2-*.ppc64le.rpm \ ibm-csm-core-1.8.2-*.ppc64le.rpm \ ibm-csm-api-1.8.2-*.ppc64le.rpm \ ibm-csm-hcdiag-1.8.2-*.noarch"Configuration¶
Now that everything needed for Cluster System Management (CSM) has been installed, CSM needs to be configured.
General Configuration¶
Suggested general configuration to verify:
Open files limit:
$ ulimit –n 500000CSM DB Configuration¶
On the management node create the csmdb schema by running the csm_db_script.sh. This script assumes that xCAT has migrated to postgresql. Details on this migration process can be found in the xCAT read the docs .
# /opt/ibm/csm/db/csm_db_script.sh -------------------------------------------------------------------------------------------- [Start ] Welcome to CSM database automation script. [Info ] Log Dir: /var/log/ibm/csm/db/csm_db_script.log [Info ] PostgreSQL is installed [Info ] csmdb database user: csmdb already exists [Complete] csmdb database created. [Complete] csmdb database tables created. [Complete] csmdb database functions and triggers created. [Complete] csmdb table data loaded successfully into csm_db_schema_version [Complete] csmdb table data loaded successfully into csm_ras_type [Info ] csmdb DB schema version (19.0) -------------------------------------------------------------------------------------------- #This will create csmdb database and configure it with default settings.
Default Configuration Files¶
A detailed description of CSM daemon configuration options can be found at: Infrastructure
On the management node copy default configuration and ACL (Access Control List) files from
/opt/ibm/csm/share/etcto/etc/ibm/csm.$ cp /opt/ibm/csm/share/etc/*.cfg /etc/ibm/csm/ $ cp /opt/ibm/csm/share/etc/csm_api.acl /etc/ibm/csm/Review the configuration and ACL files. Make the following suggested updates (note that hostnames can also be IP addresses, especially if a particular network interface is desired for CSM communication):
- Substitute all
__MASTER__occurrences in the configuration files with the management node hostname.- On aggregator configurations, substitute
__AGGREGATOR__with the corresponding service node hostname.- On compute configurations, substitute
__AGGREGATOR_A__with the assigned primary aggregator.- On compute configurations, substitute
__AGGREGATOR_B__with the secondary aggregator or leave it untouched if you set up a system without failover.- If an aggregator is run on the management node too, make sure to provide a unique entry for csm.net.local_client_listen.socket in order to avoid name collision and strange behavior.
- Create a new Linux group for privileged access.
- Add users to this group.
- Make this group privileged in the ACL file. (For more information see Section “6.3.1 Configuring user control, security, and access level” of the “CSM User Guide”)
Review all configuration and ACL files.
Copy the configuration files to the proper nodes:
On management node:
$ xdcp compute /etc/ibm/csm/csm_compute.cfg /etc/ibm/csm/csm_compute.cfg $ xdcp login,launch /etc/ibm/csm/csm_utility.cfg /etc/ibm/csm/csm_utility.cfg $ xdcp compute,login,launch /etc/ibm/csm/csm_api.acl /etc/ibm/csm/csm_api.acl $ xdcp compute,login,launch /etc/ibm/csm/csm_api.cfg /etc/ibm/csm/csm_api.cfgSSL Configuration¶
If an SSL setup is desired, the csm.net.ssl section of the config file(s) needs to be set up.
{ "ssl": { "ca_file" : "<full path to CA file>", "cred_pem" : "<full path to credentials in pem format>" } }If the strings are non-empty, the daemon assumes that SSL is requested. This means if the SSL setup fails, it will not fall back to non-SSL communication.
Heartbeat interval¶
CSM daemons heartbeat interval can be configure on csm.net section of the config file(s).
{ "net" : { "heartbeat_interval" : 15, "local_client_listen" : { "socket" : "/run/csmd.sock", "permissions" : 777, "group" : "" } } }The heartbeat interval setting defines the time between 2 subsequent unidirectional heartbeat messages in case there’s no other network traffic on a connection. The default is 15 Seconds. If two daemons are configured with a different interval, they will use the minimum of the two settings for the heartbeat on the connection. This allows to configure a short interval between Aggregator and Master and a longer interval between Aggregator and Compute to reduce network interference on compute nodes.
It might take up to 3 intervals to detect a dead connection because of the following heartbeat process: After receiving a message the daemon waits one interval to send its heartbeat one way. If it doesn’t get any heartbeat after one more interval, it will retry and wait for another interval before declaring the connection broken. This setting needs to balance the requirements between fast detection of dead connections and network traffic overhead. Note that if a daemon fails or is shut down, the closed socket will be detected immediately in many cases. The heartbeat-based detection is mostly only needed for errors in the network hardware itself (e.g. broken or disconnected cable, switch, port).
Environmental Buckets¶
The daemons are enabled to execute predefined environmental data collection. The execution is controlled in the configuration files in section csm.data_collection with can list a number of buckets each with a list of the predefined items. Currently CSM supports three types of data collection items: “gpu”, “environmental” and “ssd”.
Prolog/Epilog Scripts Compute¶
In order to create allocations both a privileged_prolog and privileged_epilog script must be present in
/opt/ibm/csm/prologs/on the compute nodes.Review the sample scripts and make any customization required.
To use the packaged sample scripts
/opt/ibm/csm/share/prologs/run the following on the management node:$ xdcp compute /opt/ibm/csm/share/prologs/* /opt/ibm/csm/prologs/This will copy the following files to the compute nodes:
- privileged_prolog ( access: 700 )
- privileged_prolog ( access: 700 )
- privileged.ini ( access: 600 )
The privileged_prolog and privileged_epilog files are python scripts that have command line arguments for type, user flags and system flags. The type is either allocation or step, and the flags are space delimited alpha-numeric strings of flags. If a new version of one of these scripts are written it must implement the options as below:
--type [allocation|step] --user_flags "[string of flags, spaces allowed]" --sys_flags "[string of flags, spaces allowed]"The privileged.ini file configures the logging levels for the script. It is only needed if extending or using the packaged scripts. For more details see the comments in the bundled scripts, the packaged POST_README.md file or the Configuring allocation prolog and epilog scripts section in the CSM User Guide.
CSM PAM Module¶
The ibm-csm-core rpm does install a PAM module that may be enabled by a system administrator. This module performs two operations: prevent unauthorized users from obtaining access to a compute node and placing users who have active allocations into the correct cgroup.
To enable the CSM PAM Module for ssh sessions:
- Add always authorized users to /etc/pam.d/csm/whitelist (newline delimited).
- Uncomment the following line from /etc/pam.d/sshd:
account required libcsmpam.so session required libcsmpam.so
- Restart the ssh daemon:
$ systemctl restart sshd.serviceNon root users who do not have an active allocation on the node and are not whitelisted will now be prevented from logging into the node via ssh. Users who have an active allocation will be placed into the appropriate cgroup when logging in via ssh.
For more details on the behavior and configuration of this module please refer to
/etc/pam.d/csm/README.md, CSM Pam Daemon Module, or the Configuring the CSM PAM module section in the CSM User Guide.WARNING: The CSM PAM module should only be enabled on nodes that will run the CSM compute daemon, as ssh logins will be restricted to root and users specified in whitelist.
Start CSM Daemons¶
Before we start CSM daemon we need to start CSM daemons dependency:
Login, Launch and Compute node
Start NVIDIA persistence and DCGM
$ xdsh compute,service,utility "systemctl start nvidia-persistenced" $ xdsh compute,service,utility "systemctl start dcgm"Management node
Start the master daemon
$ systemctl start csmd-masterStart the aggregator daemon
$ systemctl start csmd-aggregatorLogin and Launch node
Start the utility daemon
$ xdsh login,launch "systemctl start csmd-utility"Compute node
Start the compute daemon
$ xdsh compute "systemctl start csmd-compute"Run the Infrastructure Health Check¶
Run CSM infrastructure health check on the login / launch node to verify the infrastructure status:
# /opt/ibm/csm/bin/csm_infrastructure_health_check -v Starting. Contacting local daemon... Connected. Checking infrastructure... (this may take a moment. Please be patient...) ###### RESPONSE FROM THE LOCAL DAEMON ####### MASTER: c650f99p06 (bounced=0; version=1.8.2) DB_free_conn_size: 10 DB_locked_conn_pool_size: 0 Timer_test: success DB_sql_query_test: success Multicast_test: success Network_vchannel_test: success User_permission_test: success UniqueID_test: success Aggregators:2 AGGREGATOR: c650f99p06 (bounced=1; version=1.8.2) Active_primary: 2 Unresponsive_primary: 0 Active_secondary: 2 Unresponsive_secondary: 0 Primary Nodes: Active: 2 COMPUTE: c650f99p18 (bounced=1; version=1.8.2; link=PRIMARY) COMPUTE: c650f99p26 (bounced=1; version=1.8.2; link=SECONDARY) Unresponsive: 0 Secondary Nodes: Active: 2 COMPUTE: c650f99p36 (bounced=1; version=1.8.2; link=SECONDARY) COMPUTE: c650f99p28 (bounced=1; version=1.8.2; link=SECONDARY) Unresponsive: 0 AGGREGATOR: c650f99p30 (bounced=1; version=1.8.2) Active_primary: 2 Unresponsive_primary: 0 Active_secondary: 2 Unresponsive_secondary: 0 Primary Nodes: Active: 2 COMPUTE: c650f99p36 (bounced=1; version=1.8.2; link=PRIMARY) COMPUTE: c650f99p28 (bounced=1; version=1.8.2; link=PRIMARY) Unresponsive: 0 Secondary Nodes: Active: 2 COMPUTE: c650f99p18 (bounced=1; version=1.8.2; link=SECONDARY) COMPUTE: c650f99p26 (bounced=1; version=1.8.2; link=PRIMARY) Unresponsive: 0 Unresponsive Aggregators: 0 Utility Nodes:1 UTILITY: c650f99p16 (bounced=1; version=1.8.2) Unresponsive Utility Nodes: 0 Local_daemon: MASTER: c650f99p06 (bounced=0; version=1.8.2) Status: ############################################# Finished. Cleaning up... Test complete: rc=0 #Note that is some cases the list and status of nodes might not be 100% accurate if there were infrastructure changes immediately before or during the test. This usually results in timeout warnings and a rerun of the test should return an updated status.
Another important thing to note happens if there are any unresponsive compute nodes. First, unresponsive nodes will not show a daemon build version and will also not list the connection type as primary or secondary. Additionally, the unresponsive nodes are unable to provide info about their configured primary or secondary aggregator. Instead the aggregators report the last known connection status of those compute nodes. For example, if the compute node did use a connection as the primary link even if the compute configuration defines the connection as secondary, the aggregator will show this compute as an unresponsive primary node.
Environment Setup for Job Launch¶
Use CSM API command line
csm_node_attributes_updateto update the compute nodes state toIN_SERVICE.$ /opt/ibm/csm/bin/csm_node_attributes_update –s IN_SERVICE -n c650f99p28CSM REST Daemon Installation and Configuration¶
The CSM REST daemon should be installed and configured on the management node and service nodes. CSM REST daemon enables CSM RAS events to be created by IBM crassd for events detected from compute node BMCs. It also enables CSM RAS events to be created via the CSM Event Correlator from console logs. For example, GPU XID errors are monitored via the CSM Event Correlator mechanism.
On the service nodes:
Install the ibm-csm-restd rpm if it is not already installed:
$ rpm -ivh ibm-csm-restd-1.8.2-*.ppc64le.rpmCopy the default configuration file from /opt/ibm/csm/share/etc to /etc/ibm/csm:
$ cp /opt/ibm/csm/share/etc/csmrestd.cfg /etc/ibm/csm/Edit /etc/ibm/csm/csmrestd.cfg and replace
__CSMRESTD_IP__with127.0.0.1. The CSM REST daemon requires that the local CSM daemon is running before it is started.Start csmrestd using systemctl:
$ systemctl start csmrestdOn the management node (optional):
If the CSM DB on your management node was not re-created as part of the CSM installation and you intend to enable IBM POWER HW Monitor collection of BMC RAS events from your service nodes, you can manually update the CSM RAS types in the CSM DB using the following process: With all daemons stopped:
$ /opt/ibm/csm/db/csm_db_ras_type_script.sh -l csmdb csm_ras_type_data.csvThis will import any CSM RAS types into the CSM DB that were added on later releases, and it is a no-op for any events that already exist in the CSM DB.
Uninstallation¶
Stop all CSM daemons
$ xdsh compute "systemctl stop csmd-compute" $ xdsh utility "systemctl stop csmd-utility" $ systemctl stop csmd-aggregator $ systemctl stop csmd-masterDelete CSMDB
$ /opt/ibm/csm/db/csm_db_script.sh -d csmdbRemove rpms
$ xdsh compute,utility "rpm -e ibm-csm-core-1.8.2-*.ppc64le ibm-csm-api-1.8.2-*.ppc64le ibm-flightlog-1.8.2-*.ppc64le ibm-csm-hcdiag-1.8.2-*.noarch" $ rpm -e ibm-csm-core-1.8.2-*.ppc64le ibm-csm-hcdiag-1.8.2-*.noarch ibm-csm-db-1.8.2-*.noarch ibm-csm-api-1.8.2-*.ppc64le ibm-csm-restd-1.8.2-*.ppc64le ibm-flightlog-1.8.2-*.ppc64leClean up log and configuration files
$ xdsh compute,utility "rm -rf /etc/ibm /var/log/ibm" $ rm -rf /etc/ibm/csm /var/log/ibm/csmStop NVIDIA host engine (DCGM)
$ xdsh compute,service,utility "systemctl start nvidia-persistenced" $ xdsh compute,utility /usr/bin/nv-hostengine –tAppendices¶
Diskless images¶
Please ensure the following steps have been completed on the xCAT Management node:
- xCAT has been installed and the basic configuration has been completed.
- Section 2.2 has been completed and the cast-boost rpms are currently accessible at
${HOME}/rpmbuild/RPMS/ppc64le.- The
ibm-flightlog-1.8.2-*.ppc64leis present on the xCAT Management node.- Install
createrepofor building the other packages directory.After verifying the above steps have been completed do the following:
- Generate the osimages for your version of red hat:
$ copycds RHEL-7.5-Server-ppc64le-dvd1.iso $ lsdef –t osimage
- Copy the “netboot” image of the osimages created in the previous step and rename it:
$ image_input="rhels7.5-ppc64le-netboot-compute" $ image_output="rhels7.5-ppc64le-diskless-compute" $ lsdef -t osimage -z $image_input | sed -e "s/$image_input/$image_output/g" | mkdef -z
- Move the cast-boost rpms to the otherpkgdir directory for the generation of the diskless image:
$ lsdef -t osimage rhels7.5-ppc64le-diskless-compute $ cp cast-boost* /install/post/otherpkgs/rhels7.5/ppc64le/cast-boost $ createrepo /install/post/otherpkgs/rhels7.5/ppc64le/cast-boost
- Move the CSM rpms to the otherpkgdir directory:
$ cp csm_rpms/* /install/post/otherpkgs/rhels7.5/ppc64le/csm $ createrepo /install/post/otherpkgs/rhels7.5/ppc64le/csm
- Run creatrepo one last time:
$ createrepo /install/post/otherpkgs/rhels7.5/ppc64le
- Add the following to a package list in the otherpkgdir, then add the package list to the osimage:
$ vi /install/post/otherpkgs/rhels7.5/ppc64le/csm.pkglist cast-boost/cast-boost-* csm/ibm-flightlog-1.8.2-*.ppc64le csm/ibm-csm-core-1.8.2-*.ppc64le csm/ibm-csm-api-1.8.2-*.ppc64le $ chdef -t osimage rhels7.5-ppc64le-diskless-compute otherpkglist=/install/post/otherpkgs/rhels7.5/ppc64le/csm.pkglist
- Generate and package the diskless image:
$ genimage rhels7.5-ppc64le-diskless-compute $ packimage rhels7.5-ppc64le-diskless-computeAPIs¶
Cluster System Management (CSM) uses Application Programming Interfaces (APIs) to communicate between its sub systems and to external programs. This section is a general purpose guide for interacting with CSM APIs.
This section is divided into the following subsections:
Installation¶
The three installation rpms essential to CSM APIs are
csm-core-*.rpm,csm-api-*.rpmandcsm-db-*.rpm. These three rpms must be installed to use CSM APIs.
csm-core-*.rpmmust be installed on the following components:
- management node
- login node
- launch node
- compute node
csm-api-*.rpmmust be installed on the following components:
- management node
- login node
- launch node
- compute node
csm-db-*.rpmmust be installed on the following components:
- management node
Configuration¶
Overview¶
CSM APIs have the ability to be configured in various ways. There are default configurations provided for CSM APIs to function, but these settings can be changed and set to a user’s preference.
The configurable features of CSM APIs are:
Table of Contents¶
CSM Pam Daemon Module¶
The
libcsmpam.somodule is installed by thecsm-core-*.rpmrpm to/usr/lib64/security/libcsmpam.so.To enable the this module for sshd perform the following steps:
Uncomment the following lines in
/etc/pam.d/sshd#account required libcsmpam.so #session required libcsmpam.soNote
The session
libcsmpam.somodule is deliberately configured to be the last session in this file.If the configuration changes this make sure the
libcsmpam.sois loaded after the default session modules. It is recommended thatlibcsmpam.sobe immediately after the defaultpostloginline in the sshd config if the admin is adding additional session modules.The account
libcsmpam.somodule should be configured before the accountpassword-auth.Run systemctl restart sshd.service to restart the sshd daemon with the new config.
After the daemon has been restarted the modified pam sshd configuration should now be used.
Contents¶ Module Behavior¶ This module is designed for account authentication and cgroup session assignment in the pam sshd utility. The following checks are performed to verify that the user is allowed to access the system:
The user is root.
- Allow entry.
- Place the user in the default cgroup (session only).
- Exit module with success.
The user is defined in /etc/pam.d/csm/activelist.
- Allow entry.
- Place the session in the cgroup that the user is associated with in the activelist (session only).
- note: The activelist is modified by csm, admins should not modify.
- Exit module with success.
The user is defined in /etc/pam.d/csm/whitelist.
- Allow entry.
- Place the user in the default cgroup (session only).
- note: The whitelist is modified by the admin.
- Exit module with success.
The user was not found.
- Exit the module, rejecting the user.
Module Configuration¶ Configuration may occur in either a pam configuration file (e.g.
/etc/pam.d/sshd) or the csm pam whitelist.libcsmpam.so¶
File Location: /usr/lib64/security/libcsmpam.soConfigurable: Through pam configuration file. The
libcsmpam.sois a session pam module. For details on configuring this module and other pam modules please consult the linux man page (man pam.conf).When
csm-core-*.rpmis uninstalled, this library is always removed.Warning
The
libcsmpam.somodule is recommended be the last session line in the default pam configuration file. The module requires the session to be established to move the session to the correct cgroup. If the module is invoked too early in the configuration, users will not be placed in the correct cgroup. Depending on your configuration this advice may or man not be useful.whitelist¶
File location: /etc/pam.d/csm/whitelistConfigurable: Yes The whitelist is a newline delimited list of user names. If a user is specified they will always be allowed to login to the node.
If the user has an active allocation on the node an attempt will be made to place them in the correct allocation cgroup. Otherwise, the use will be placed in the default cgroup.
When
csm-core-*.rpmis uninstalled, if this file has been modified it will NOT be deleted.The following configuration will add three users who will always be allowed to start a session. If the user has an active allocation they will be placed into the appropriate cgroup as described above.
jdunham pmix csm_adminactivelist¶
File location: /etc/pam.d/csm/activelistConfigurable: No The activelist file should not be modified by the admin or user. CSM will modify this file when an allocation is created or deleted.
The file contains a newline delimited list of entries with the following format:
[user_name];[allocation_id]. This format is parsed bylibcsmpam.soto determine whether or not a user can begin the session (username) and which cgroup it belongs to (allocation_id).When
csm-core-*.rpmis uninstalled, this file is always removed.Module Compilation¶ Attention
Ignore this section if the csm pam module is being installed by rpm.
In order to compile this module the
pam-develpackage is required to compile.Troubleshooting¶ Core Isolation¶ If users are having problems with core isolation, unable to log onto the node, or not being placed into the correct cgroup, first perform the following steps.
Manually create an allocation on a node that has the PAM module configured.
This should be executed from the launch node as a non root user.
$ csm_allocation_create -j 1 -n <node_name> --cgroup_type 2 --- allocation_id: <allocation_id> num_nodes: 1 - compute_nodes: <node_name> user_name: root user_id: 0 state: running type: user managed job_submit_time: 2018-01-04 09:01:17 ...POSSIBLE FAILURES
- The allocation create fails, ensure the node is in service:
$ csm_node_attributes_update -s "IN_SERVICE" -n <node_name>After the allocation has been created with core isolation ssh to the node
<node_name>as the user who created the allocation:$ ssh <node_name>POSSIBLE FAILURES
The /etc/pam.d/csm/activelist was not populated with <user_name>.
- Verify the allocation is currently active:
csm_allocation_query_active_all | grep "allocation_id.* <allocation_id>$"If the allocation is not currently active attempt to recreate the allocation.
Login to <node_name> as root and check to see if the user is on the activelist:
$ ssh <node_name> -l root "grep <user_name> /etc/pam.d/csm/activelist"If the user is not present and the allocation create is functioning this may be a CSM bug, open a defect to the CSM team.
Check the cgroup of the user’s ssh session.
$ cat /proc/self/cgroup 11:blkio:/ 10:memory:/allocation_<allocation_id> 9:hugetlb:/ 8:devices:/allocation_<allocation_id> 7:freezer:/ 6:cpuset:/allocation_<allocation_id> 5:net_prio,net_cls:/ 4:perf_event:/ 3:cpuacct,cpu:/allocation_<allocation_id> 2:pids:/ 1:name=systemd:/user.slice/user-9999137.slice/session-3957.scopeAbove is an example of a properly configured cgroup. The user should be in an allocation cgroup for the memory, devices, cpuacct and cpuset groups.
POSSIBLE FAILURES
The user is only in the cpuset:/csm_system cgroup This generally indicates that the libcsmpam.so module was not added in the correct location or is disabled.
Refer to the quick start at the top of this document for more details.
The user is in the cpuset:/ cgroup. Indicates that core isolation was not performed, verify core isolation is enabled in the allocation create step.
Any further issues are beyond the scope of this troubleshooting document, contacting the CSM team or opening a new issue is the recommended course of action.
Users Without Access Being Given Access¶ If a user who doesn’t have access is capable of logging into a node configured with the pam library perform the following steps:
Verify that the following lines are uncommented in
/etc/pam.d/sshdaccount required libcsmpam.so session required libcsmpam.soVerify that
account required libcsmpam.sois located aboveaccount include password-authVerify that
session required libcsmpam.sois located after the othersessionmodules.Verify that a “csm_cgroup_login[.*]; User not authorized” entry is present in
/var/log/ibm/csm/csm_compute.logAny further issues are beyond the scope of this troubleshooting document, contacting the CSM team or opening a new issue is the recommended course of action.
Configuring allocation prolog and epilog scripts¶
A privileged_prolog and privileged_epilog script (with those exact names) must be placed in
/opt/ibm/csm/prologson a compute node in order to use the csm_allocation_create, csm_allocation_delete, and csm_allocation_update APIs. These scripts must be executable and take three command line parameters: –type, –user_flags, and –sys_flags.To add output from this script to the Big Data Store (BDS) it is recommended that the system administrator producing these scripts make use of their language of choice’s logging function.
A sample privileged_prolog and privileged_epilog written in python is shipped in
csm-core-*.rpmat/opt/ibm/csm/share/prologs. These sample scripts demonstrate the use of the python logging module to produce logs consumable for the BDS.Mandatory prolog/epilog Features¶
Feature Description –type –sys_flags –user_flags Returns 0 on success Optional prolog/epilog Features¶
Feature Description logging Prolog/epilog Environment Variables¶
CSM_ALLOCATION_ID:
Allocation: Yes Step: Yes The Allocation ID of the invoking CSM handler.
CSM_SECONDARY_JOB_ID:
Allocation: Yes Step: No The Primary Job (Batch) ID of the invoking CSM handler.
CSM_SECONDARY_JOB_ID:
Allocation: Yes Step: No The Secondary Job (Batch) ID of the invoking CSM handler.
CSM_USER_NAME:
Allocation: Yes Step: No The user associated with the job.
Note
A step prolog or step epilog differs in two ways: the –type flag is set to step and certain environment variables will not be present.
Configuring CSM API Logging Levels¶
CSM has lots of things that print out to the logs. Some things are printed at different log levels. You can configure CSM APIs to switch between these log levels. Logging is handled through the CSM infrastructure and divided into two parts, “Front end” and “back end”.
“Front end” is supposed to represent the part of the API a user would interface with and before an API connects and goes into the CSM infrastructure. “Back end” refers to the part of an API that the user would not interact with and after an API connects and goes into the CSM infrastructure.
Front end logging¶ Front end logging is done through the csm logging utility. You will need to include the header file to call the function.
#include "csmutil/include/csmutil_logging.h"Set the log level with this function:
csmutil_logging_level_set(my_level);Where my_level is either: - off - trace - debug - info - warning - error - critical - always - disable
After this function is called, the logging level will change. For example, below we set the logging level to error. So none of these logging calls will print. When we call the API at the end, then only prints that are at level error and above will print.
csmutil_logging_level_set(“error”); // This will print out the contents of the struct that we will pass to the api csmutil_logging(debug, "%s-%d:", __FILE__, __LINE__); csmutil_logging(debug, " Preparing to call the CSM API..."); csmutil_logging(debug, " value of input: %p", input); csmutil_logging(debug, " address of input: %p", &input); csmutil_logging(debug, " input contains the following:"); csmutil_logging(debug, " comment: %s", input->comment); csmutil_logging(debug, " limit: %i", input->limit); csmutil_logging(debug, " node_names_count: %i", input->node_names_count); csmutil_logging(debug, " node_names: %p", input->node_names); for(i = 0; i < input->node_names_count; i++){ csmutil_logging(debug, " node_names[%i]: %s", i, input->node_names[i]); } csmutil_logging(debug, " offset: %i", input->offset); csmutil_logging(debug, " type: %s", csm_get_string_from_enum(csmi_node_type_t, input->type) ); /* Call the C API. */ return_value = csm_node_attributes_query(&csm_obj, input, &output);If we called the same function, but instead passed in debug, then all those logging calls would print, and when we call the API at the end, all prints inside the API that were set to level debug and above would print. CSM API wrappers such as the CMD Line interfaces include access to this function via the –v, –verbose field on the cmd line parameters.
Back end logging¶ APIs incorporate the CSM daemon logging system, under the sub channel of csmapi. If you want to change the level of default API logging, then you must configure the field in the appropriate csm daemon config file. csmapi is the field you would need to change. It is found in all the CSM daemon config files, under the csm level, then under sub level log.
An excerpt of the csm_master.cfg is reproduced below as an example.
"csm" : { "log" : { "format" : "%TimeStamp% %SubComponent%::%Severity% | %Message%", "consoleLog" : false, "fileLog" : "/var/log/ibm/csm/csm_master.log", "__rotationSize_comment_1" : "Maximum size (in bytes) of the log file, 10000000000 bytes is ~10GB", "rotationSize" : 10000000000, "default_sev" : "warning", "csmdb" : "info", "csmnet" : "info", "csmd" : "info", "csmras" : "info", "csmapi" : "info", "csmenv" : "info" } }An example of editing this field from info to debug is shown below.
"csm" : { "log" : { "format" : "%TimeStamp% %SubComponent%::%Severity% | %Message%", "consoleLog" : false, "fileLog" : "/var/log/ibm/csm/csm_master.log", "__rotationSize_comment_1" : "Maximum size (in bytes) of the log file, 10000000000 bytes is ~10GB", "rotationSize" : 10000000000, "default_sev" : "warning", "csmdb" : "info", "csmnet" : "info", "csmd" : "info", "csmras" : "info", "csmapi" : "debug", "csmenv" : "info" } }If you have trouble finding the config files, then daemon config files are located: - source repo: “csmconf/” - ship to: “/opt/ibm/csm/share/” - run from: “etc/ibm/csm/”
Note: You may need to restart the daemon for the logging level to change.
If you want to make a run time change to logging, but don’t want to change the configuration file. You can use this tool found it here: opt/ibm/csm/sbin/csm_ctrl_cmd
You must run this command on the node with the CSM Daemon that you would like to change the logging level of.
List of CSM APIs¶
Full List¶
- csm_allocation_create
- csm_allocation_delete
- csm_allocation_query
- csm_allocation_query_active_all
- csm_allocation_query_details
- csm_allocation_resources_query
- csm_allocation_step_begin
- csm_allocation_step_cgroup_create
- csm_allocation_step_cgroup_delete
- csm_allocation_step_end
- csm_allocation_step_query
- csm_allocation_step_query_active_all
- csm_allocation_step_query_details
- csm_allocation_update_state
- csm_allocation_update_history
- csm_api_object_clear
- csm_api_object_destroy
- csm_api_object_errcode_get
- csm_api_object_errmsg_get
- csm_api_object_traceid_get
- csm_bb_cmd
- csm_bb_lv_create
- csm_bb_lv_delete
- csm_bb_lv_query
- csm_bb_lv_update
- csm_bb_vg_create
- csm_bb_vg_delete
- csm_bb_vg_query
- csm_cgroup_login
- csm_cluster_query_state
- csm_diag_result_create
- csm_diag_run_begin
- csm_diag_run_end
- csm_diag_run_query
- csm_diag_run_query_details
- csm_enum_from_string
- csm_infrastructure_health_check
- csm_ib_cable_inventory_collection
- csm_ib_cable_query
- csm_ib_cable_query_history
- csm_ib_cable_update
- csm_init_lib
- csm_init_lib_vers
- csm_node_attributes_query
- csm_node_attributes_query_details
- csm_node_attributes_query_history
- csm_node_attributes_update
- csm_node_delete
- csm_node_find_job
- csm_node_query_state_history
- csm_node_resources_query
- csm_node_resources_query_all
- csm_ras_event_create
- csm_ras_event_query
- csm_ras_event_query_allocation
- csm_ras_msg_type_create
- csm_ras_msg_type_delete
- csm_ras_msg_type_query
- csm_ras_msg_type_update
- csm_term_lib
- csm_smt
- csm_switch_attributes_query
- csm_switch_attributes_query_details
- csm_switch_attributes_query_history
- csm_switch_attributes_update
- csm_switch_inventory_collection
- csm_switch_children_inventory_collection
New in CSM 1.3.0¶
- csm_cluster_query_state
- csm_node_find_job
New in CSM 1.1.0¶
- csm_jsrun_cmd
Implementing New CSM APIs¶
CSM is an open source project that can be contributed to by the community. This section is a guide on how to contribute a new CSM API to this project.
Contributors should visit the GitHub and follow the instructions in the How to Contribute section of the repository readme.
Front-end¶
This is the API an end user would interact with. The front end interacts with the Infrastructure through network connections to varying results.
Follow these steps to create/edit an api. The diagram below shows where to find the appropriate files in the GitHub repository.
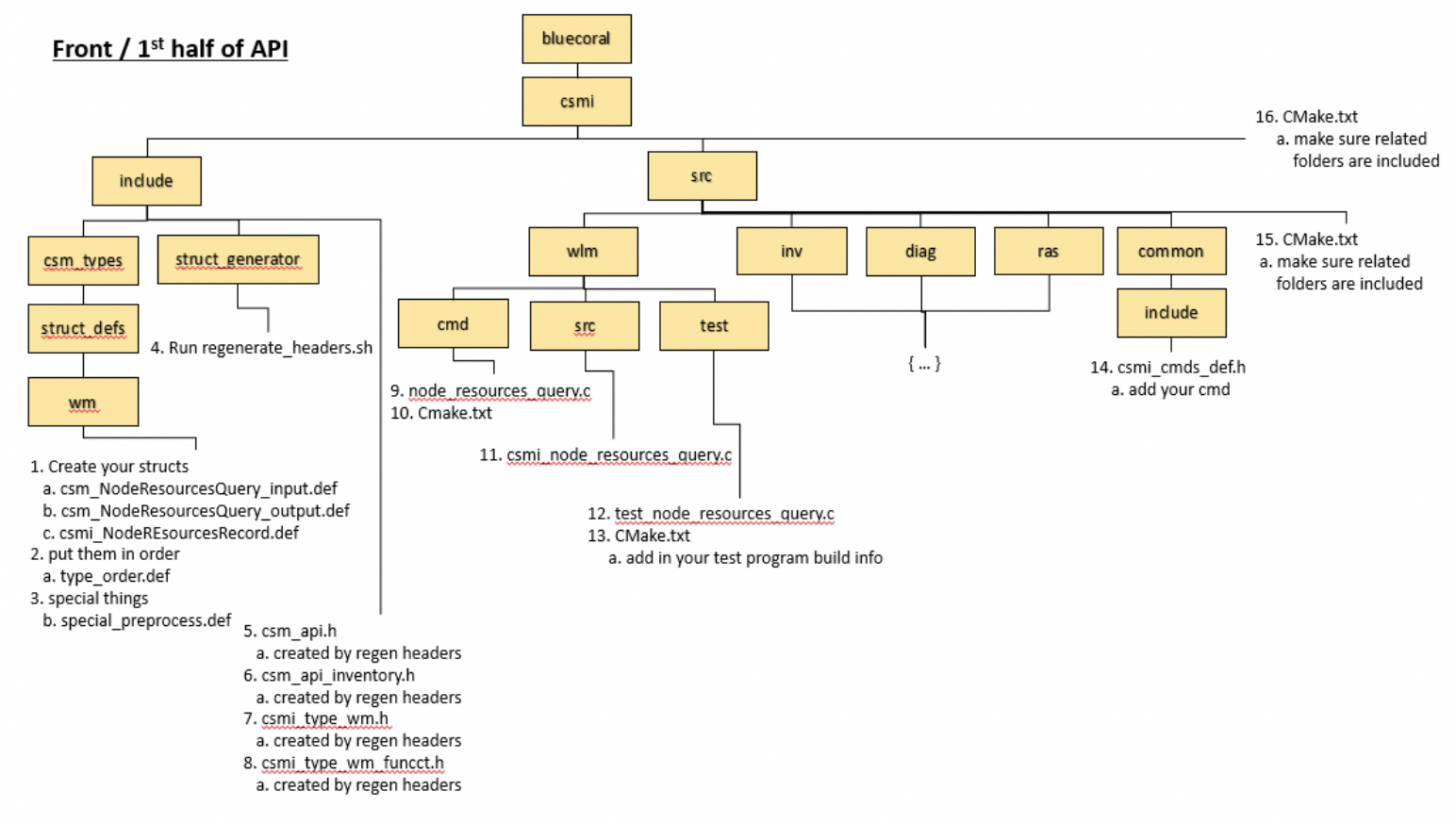
The following numbers reference the chart above.
1: When creating an API it should be determined whether it accepts input and produces output. The CSM design follows the pattern of <API_Name>_input_t for input structs and <API_Name>_output_t for output structs. These structs should be defined through use of an x-macro in the appropriate folder for the API type under the
csmi/include/csm_types/struct_defsdirectory.A struct README is provided in this directory with an in-depth description of the struct definition process.
/*================================================================================*/ /** * CSMI_COMMENT * @brief An input wrapper for @ref csm_example_api. */ #ifndef CSMI_STRUCT_NAME // ! The name of the struct to be generated ! #define CSMI_STRUCT_NAME csm_example_api_input_t #undef CSMI_BASIC #undef CSMI_STRING #undef CSMI_STRING_FIXED #undef CSMI_ARRAY #undef CSMI_ARRAY_FIXED #undef CSMI_ARRAY_STR #undef CSMI_ARRAY_STR_FIXED #undef CSMI_STRUCT #undef CSMI_ARRAY_STRUCT #undef CSMI_ARRAY_STRUCT_FIXED #undef CSMI_NONE // ! Set to 1 (true) when a field matching the type is present ! #define CSMI_BASIC 1 #define CSMI_STRING 1 #define CSMI_STRING_FIXED 0 #define CSMI_ARRAY 0 #define CSMI_ARRAY_FIXED 0 #define CSMI_ARRAY_STR 1 #define CSMI_ARRAY_STR_FIXED 0 #define CSMI_STRUCT 0 #define CSMI_ARRAY_STRUCT 0 #define CSMI_ARRAY_STRUCT_FIXED 0 #define CSMI_NONE 0 #endif // CSMI_STRUCT_MEMBER(type, name, serial_type, length_member, init_value, extra ) /**< comment */ CSMI_VERSION_START(CSM_VERSION_1_0_0) CSMI_STRUCT_MEMBER(int32_t , my_first_int , BASIC , , -1 , ) /**< Example int32_t value. API will ignore values less than 1.*/ CSMI_STRUCT_MEMBER(uint32_t, my_string_array_count, BASIC , , 0 , ) /**< Number of elements in the 'my_string_array' array. Must be greater than zero. Size of @ref my_string_array.*/ CSMI_STRUCT_MEMBER(char** , my_string_array , ARRAY_STR, my_string_array_count, NULL, ) /**< comment for my_string_array*/ CSMI_VERSION_END(fc57b7dafbe3060895b8d4b2113cbbf0) CSMI_VERSION_START(CSM_DEVELOPMENT) CSMI_STRUCT_MEMBER(int32_t, another_int, BASIC, , -1, ) /**< Another int.*/ CSMI_VERSION_END(0) #undef CSMI_VERSION_START #undef CSMI_VERSION_END #undef CSMI_STRUCT_MEMBER .. attention:: Follow the existing `struct README`_ in the code source for supplemental details.
2: The X-Macro definition files will be collated by their ordering in the local
type_order.deffile. New files added to this ordering should just be the file name.Specific details for this file are in the struct README.
3: The
special_preprocess.deffile is prepended to the generated header. This file should only be modified if your struct uses a special header or requires some preprocessor directive. Please note that this will apply globally to the generated header file.4: After defining the X-Macro files the developer should run the
regenerate_headers.shscript located atbluecoral/csmi/include/struct_generator/. This script will prepare the structs and enumerated types for use in the CSM APIs and infrastructure. Serialization functions and python bindings will also be generated.The files modified by this script include:
Common:
Type Header csmi_type_common.h Function Header csmi_type_common_funct.h Serialization Code csmi_common_serial.c Workload Manager:
Type Header csmi_type_wm.h Function Header csmi_type_wm_funct.h Serialization Code csmi_wm_serialization.c Inventory:
Type Header csmi_type_inv.h Function Header csmi_type_inv_funct.h Serialization Code csmi_inv_serialization.c Burst Buffer:
Type Header csmi_type_bb.h Function Header csmi_type_bb_funct.h Serialization Code csmi_bb_serialization.c RAS:
Type Header csmi_type_ras.h Function Header csmi_type_ras_funct.h Serialization Code csmi_ras_serialization.c Diagnostic:
Type Header csmi_type_diag.h Function Header csmi_type_diag_funct.h Serialization Code csmi_diag_serialization.c Launch:
Type Header csmi_type_launch.h Function Header csmi_type_launch_funct.h Serialization Code csmi_launch_serialization.c 5: Add the API function declaration to the appropriate API file, consult the table below for the correct file to add your API to (in the
bluecoral/csmi/includedirectory):
API Type API File Common csm_api_common.h Workload Manager csm_api_workload_manager.h Inventory csm_api_inventory.h Burst Buffer csm_api_burst_buffer.h RAS csm_api_ras.h Diagnostic csm_api_diagnostic.h 6: Add a command to the
csmi/src/common/include/csmi_cmds_def.hX-Macro. This will generate an enumerated type in the format of CSM_CMD_<csm-contents> [cmd(<csm-contents>)] on compilation and used in the front and backend API.7: The implementation of the C API should be placed in the appropriate src directory:
API Type Source Directory Common csmi/src/common/src Workload Manager csmi/src/wm/src Inventory csmi/src/inv/src Burst Buffer csmi/src/bb/src RAS csmi/src/ras/src Diagnostic csmi/src/diag/src Generally speaking the frontend C API implementation should follow a mostly standard pattern as outlined below:
#include "csmutil/include/csmutil_logging.h" #include "csmutil/include/timing.h" #include "csmi/src/common/include/csmi_api_internal.h" #include "csmi/src/common/include/csmi_common_utils.h" #include "csmi/include/“<API_HEADER> // The expected command, defined in “csmi/src/common/include/csmi_cmds_def.h” const static csmi_cmd_t expected_cmd = <CSM_CMD>; // This function must be definedand supplied to the create_csm_api_object // function if the API specifies an output. void csmi_<api>_destroy(csm_api_object *handle); // The actual implementation of the API. int csm_<api>( csm_api_object **handle, <input_type> *input, <output_type> ** output) { START_TIMING() char *buffer = NULL; // A buffer to store the serialized input struct. uint32_t buffer_length = 0; // The length of the buffer. char *return_buffer = NULL; // A return buffer for output from the backend. uint32_t return_buffer_len = 0; // The length of the return buffer. Int. error_code = CSMI_SUCCESS; // The error code, should be of type // csmi_cmd_err_t. // EARLY RETURN // Create a csm_api_object and sets its csmi cmd and the destroy function. create_csm_api_object(handle, expected_cmd, csmi_<api>_destroy); // Test the input to the API, expand this to test input contents. if (!input) { csmutil_logging(error, "The supplied input was null."); // The error codes are listed in “csmi/include/csmi_type_common.h”. csm_api_object_errcode_set(*handle, CSMERR_INVALID_PARAM); csm_api_object_errmsg_set(*handle, strdup(csm_get_string_from_enum(csmi_cmd_err_t, CSMERR_INVALID_PARAM))); } // EARLY RETURN // Serialize the input struct and then test the serialization. csm_serialize_struct(<input_type>, input, &buffer, &buffer_length); test_serialization(handle, buffer); // Execute the send receive command (this is blocking). error_code = csmi_sendrecv_cmd(*handle, expected_cmd, buffer, buffer_length, &return_buffer, &return_buffer_len); // Based on the error code unpack the results or set the error code. if ( error_code == CSMI_SUCCESS ) { if ( return_buffer && csm_deserialize_struct(<output_type>, output, (const char *)return_buffer, return_buffer_len) == 0 ) { // ATTENTION: This is key, the CSM API makes a promise that the // output of the API will be stored in the csm_api_object! csm_api_object_set_retdata(*handle, 1, *output); } else { csmutil_logging(error, "Deserialization failed"); csm_api_object_errcode_set(*handle, CSMERR_MSG_UNPACK_ERROR); csm_api_object_errmsg_set(*handle, strdup(csm_get_string_from_enum(csmi_cmd_err_t, CSMERR_MSG_UNPACK_ERROR))); error_code = CSMERR_MSG_UNPACK_ERROR; } } else { csmutil_logging(error, "csmi_sendrecv_cmd failed: %d - %s", error_code, csm_api_object_errmsg_get(*handle)); } // Free the buffers. if(return_buffer)free(return_buffer); free(buffer); END_TIMING( csmapi, trace, csm_api_object_traceid_get(*handle), expected_cmd, api ) return error_code; } // This function should destroy any data stored in the csm_api_object by the API call. void csmi_<api>_destroy(csm_api_object *handle) { csmi_api_internal *csmi_hdl; <output_type> *output; // free the CSMI dependent data csmi_hdl = (csmi_api_internal *) handle->hdl; if (csmi_hdl->cmd != expected_cmd) { csmutil_logging(error, "%s-%d: Unmatched CSMI cmd\n", __FILE__, __LINE__); return; } // free the returned data specific to this csmi cmd output = (<output_type> *) csmi_hdl->ret_cdata; csm_free_struct_ptr( <output_type>, output); csmutil_logging(info, "csmi_<api>_destroy called"); }
8: Optionally, the developer may implement command line interface to the C API. For implementing an API please refer to existing API implementations. Back-end¶
The he part of the API that the user will not interact with directly. The back end will be invoked by the Infrastructure after receiving user requests.
This diagram below shows where to find the appropriate files in the GitHub repository.
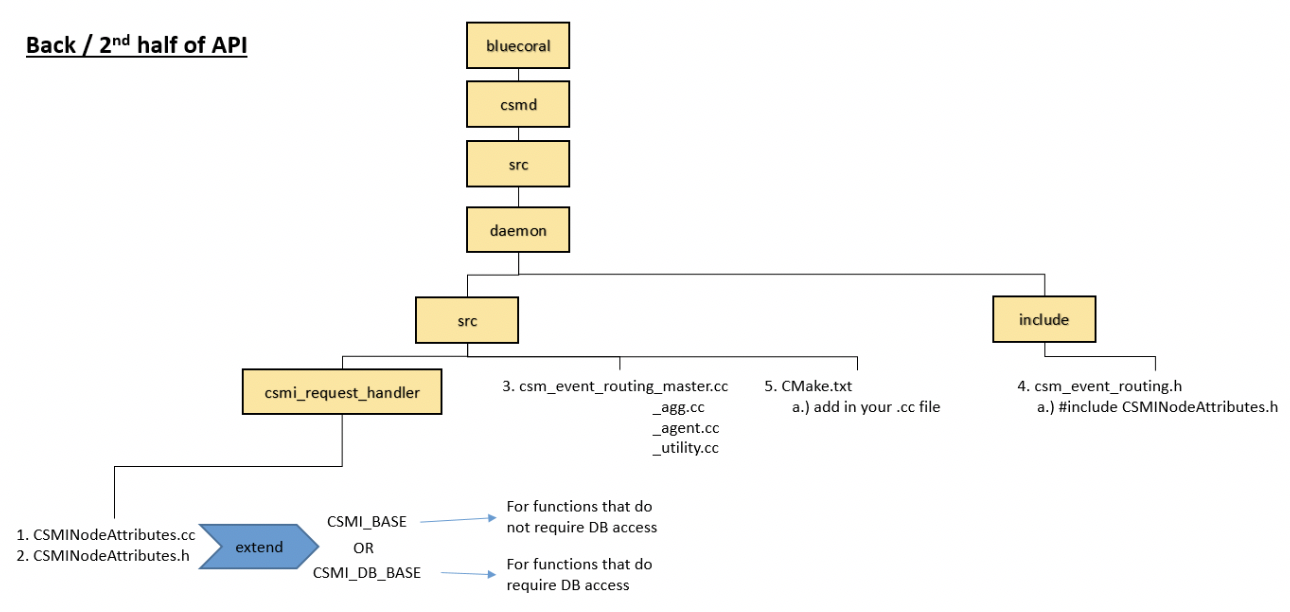
When implementing a backend API the developer must determine several key details:
- Does the API handler access the database? How many times?
- What daemon will the API handler operate on?
- Does the API need a privilege mode?
- Will the API perform a multicast?
These questions will drive the development process, which in the case of most database APIs is boiler plate as shown in the following sections.
Determining the Base Handler Class¶
In the Infrastructure the back-end API is implemented as an API Handler. This handler may be considered a static object which maintains no volatile state. The state of API execution is managed by a context object initialized when a request is first received by a back-end handler.
CSM has defined several implementations of handler class to best facilitate the rapid creation of back-end handlers. Unless otherwise specified these handlers are located in
csmd/src/daemon/src/csmi_request_handlerand handler implementations should be placed in the same directory.CSMIStatefulDB (csmi_stateful_db.h)¶ If an API needs to access the database, it is generally recommended to use this handler as a base class. This class provides four virtual functions:
CreatePayload: Parses the incoming API request, then generates the SQL query. CreateByteArray: Parses the response from the database, then generates the serialized response. RetrieveDataForPrivateCheck: Generates a query to the database to check the user’s privilege level (optional). CompareDataForPrivateCheck: Checks the results of the query in RetrieveDataForPrivateCheckreturning true or false based on the results (optional).In the simplest Database APIs, the developer needs to only implement two functions:
CreatePayloadandCreateByteArray. In the case of privileged APIs, theRetrieveDataForPrivateCheckandCompareDataForPrivateCheckmust be implemented.This handler actually represents a state machine consisting of three states which generalize the most commonly used database access path. If your application requires multiple database accesses or multicasts this state machine may be extended by overriding the constructor.
To facilitate multiple database accesses in a single API call CSM has implemented
StatefulDBRecvSend.StatefulDBRecvSendtakes a static function as a template parameter which defines the processing logic for the SQL executed byCreatePayload. The constructor forStatefulDBRecvSendthen takes an assortment of state transitions for the state machine which will depend on the state machine used for the API.An example of this API implementation style can be found in
CSMIAllocationQuery.cc. The pertinent section showing expansion of the state machine with the constructor is reproduced and annotated below:#define EXTRA_STATES 1 // There’s one additional state being used over the normal StatefulDB. // Note: CSM_CMD_allocation_query matches the version on the front-end. CSMIAllocationQuery::CSMIAllocationQuery(csm::daemon::HandlerOptions& options) : CSMIStatefulDB(CSM_CMD_allocation_query, options, STATEFUL_DB_DONE + EXTRA_STATES) // Send the total number of states to super. { const uint32_t final_state = STATEFUL_DB_DONE + EXTRA_STATES; uint32_t current_state = STATEFUL_DB_RECV_DB; uint32_t next_state = current_state + 1; SetState( current_state++, new StatefulDBRecvSend<CreateResponsePayload>( next_state++, // Successful state. final_state, // Failure state. final_state ) ); // Final state. } #undef EXTRA_STATES bool CSMIAllocationQuery::CreateResponsePayload( const std::vector<csm::db::DBTuple *>&tuples, csm::db::DBReqContent **dbPayload, csm::daemon::EventContextHandlerState_sptr ctx ) { // …. }Multicast operations will follow a largely similar behavior, however they exceed the scope of this document, for more details refer to
csmd/src/daemon/src/csmi_request_handler/csmi_mcast.CSMIStateful (csmi_stateful.h)¶ This handler should be used as a base class in handlers where no database operations are required (see CSMIAllocationStepCGROUPDelete.h). Generally, most API implementations will not use this as a base class. If an API is being implemented as CSMIStateful it is recommended to refer the source of CSMIAllocationStepCGROUPDelete.h and CSMIAllocationStepCGROUPCreate.h.
Adding Handler to Compliation¶
To add the handler to the compilation path for the daemon add it to the
csmd/src/daemon/src/CMakeLists.txtfile’s CSM_DAEMON_SRC file GLOB.Registering with a Daemon¶
After implementing the back-end API the user must then register the API with the daemon routing. Most APIs will only need to be registered on the Master Daemon, however, if the API performs multicasts it will need to be registered on the Agent and Aggregator Daemons as well. The routing tables are defined in
csmd/src/daemon/src:
Daemon Routing File Agent csm_event_routing_agent.cc Aggregator csm_event_routing_agg.cc Master csm_event_routing_master.cc Utility csm_event_routing_utility.cc Generally speaking registering a handler to a router is as simple as adding the following line to the RegisterHandlers function: Register < Handler_Class > (CSM_CMD_<api>) ;
Return Codes¶
As with all data types that will exist in both the C front-end and C++ back-end return codes are defined with an X-Macro solution. The return code X-Macro file can be located at: csmi/include/csm_types/enum_defs/common/csmi_errors.def
To protect backwards compatibility this file is guarded by with versioning blocks, for details on how to add error codes please consult the README: csmi/include/csm_types/enum_defs/README.md
The generated error codes may be included from the
csmi/include/csmi_type_common.hheader. Generally, theCSMI_SUCCESSerror code should be used in cases of successful execution. Errors should be more granular to make error determination easier for users of the API, consult the list of errors before adding a new one to prevent duplicate error codes.CSM API Wrappers¶
There exist two documented methodologies for wrapping a CSM API to reduce the barrier of usage for system administrators: python bindings and command line interfaces. Generally speaking python bindings are preferred, as they provide more flexibility to system administrators and end users.
Command line interfaces are generally written in C and are used to expose basic functionality to an API.
Command Line Interfaces¶
Command line interfaces in CSM are generally written using native C and expose basic functionality to the API, generally simplifying inputs or control over the output. When properly compiled a native C command line interface will be placed in
/csm/bin/relative to the root of the compiled output. Please consult csmi/src/wm/cmd/CMakeLists.txt for examples of compilation settings.Naming¶ The name of the CSM command line interface should be matched one to one to the name of the API, especially in cases where the command line interface simply exposes the function of the API with no special modifications. For example, the
csm_allocation_createAPI is literallycsm_allocation_createon the command line.Parameters¶ CSM command line interfaces must provide long options for all command line parameters. Short options are optional but preferred for more frequently used fields. A sample pairing of short and long options would be in the case of the help flag:
-h, --help. iThe
-h, --helpand-v, --verboseflag pairings are reserved, always correspond to help and verbose. These flags should be supported in all CSM command line interfaces.All options should use the
getoptsutility, no options should be position dependent.Good:
csm_command --node_name node1 --state "some string" csm_command --state "some string" –node_name node1Bad:
csm_command node1 --state "some string"Output¶ CSM command line requires that the YAML format is a supported output option. This is to facilitate command line parsers. In cases where YAML output is not ideal for command line readability the format may be changed as in the case of
csm_node_query_state_history.In the following sample output the output is still considered valid YAML (note the open and close tokens). Data that is not YAML formatted will be commented out with the # character.
[root@c650f03p41 bin]# ./csm_node_query_state_history -n c650f03p41 --- node_name: c650f03p41 # history_time | state | alteration | RAS_rec_id, RAS_msg_id # ----------------------------+----------------+----------------------+------------------------ # 2018-03-26 14:28:25.032879 | DISCOVERED | CSM INVENTORY | # 2018-03-28 19:34:14.037409 | SOFT_FAILURE | RAS EVENT | 7, csm.status.down ...By default, YAML is not presented on the command line. It is supported through a flag.
GENERAL OPTIONS: [-h, --help] | Help. [-v, --verbose verbose_level] | Set verbose level. Valid verbose levels: {off, trace, debug, info, warning, error, critical, always, disable} [-Y, --YAML] | Set output to YAML. By default for this API, we have a custom output for ease of reading the long transaction history.By setting the
–Yflag, the command line will then display in YAML.[root@c650f03p41 bin]# ./csm_node_query_state_history -n c650f03p41 -Y --- Total_Records: 2 Record_1: history_time: 2018-03-26 14:28:25.032879 node_name: c650f03p41 state: DISCOVERED alteration: CSM INVENTORY RAS_rec_id: RAS_msg_id: Record_2: history_time: 2018-03-28 19:34:14.037409 node_name: c650f03p41 state: SOFT_FAILURE alteration: RAS EVENT RAS_rec_id: 7 RAS_msg_id: csm.status.down ...Python Interfaces¶
CSM uses Boost.Python to generate the Python interfaces. Struct bindings occur automatically when running the
csmi/include/struct_generator/regenerate_headers.shscript. Each API type has its own file to which the struct bindings will be placed by the automated script and function bindings will be placed by the developer.The following documentation assumes the python bindings are being added to one of the following files:
API Type Python Binding File Python Library Burst Buffer csmi/src/bb/src/csmi_bb_python.cc lib_csm_bb_py Common csmi/src/common/src/csmi_python.cc lib_csm_py Diagnostics csmi/src/diag/src/csmi_diag_python.cc lib_csm_diag_py Inventory csmi/src/inv/src/csmi_inv_python.cc lib_csm_inv_py Launch csmi/src/launch/src/csmi_launch_python.cc lib_csm_launch_py RAS csmi/src/ras/src/csmi_ras_python.cc lib_csm_ras_py Workload Management csmi/src/wm/src/csmi_wm_python.cc lib_csm_wm_py Function Binding¶ Function binding with the Boost.Python library is boilerplate:
tuple wrap_<api>(<input-struct> input) { // Always sets the metadata. // Ensures that the python binding always matches what it was designed for. input._metadata=CSM_VERSION_ID; // Output objects. csm_api_object * updated_handle; <output-struct> * output= nullptr; // Run the API int return_code = <api>( (csm_api_object**)&updated_handle, &input, &output); // A singleton is used to track CSM object handles. int64_t oid = CSMIObj::GetInstance().StoreCSMObj(updated_handle); // Returned tuples should always follow the pattern: // <return code, handler id, output values (optional)> return make_tuple(return_code, oid, *output); } BOOST_PYTHON_MODULE(lib_csm_<api-type>_py) { def("<api-no-csm>", wrap_<api>, CSM_GEN_DOCSTRING("docstring", ",<output_type>")); }Python Binding Limitations¶ As CSM was designed predominantly around its use of pointers, and is a C native API, certain operations using the python bindings are not currently Pythonic.
1: The output of the apis must be destroyed using csm.api_object_destroy(handler_id).2: Array access/creation must be performed through get and set functions. Once an array is set it is currently immutable from python. These limitations are subject to change.
CSM API Python Bindings Guide¶
Tables of Contents:¶
About¶
The CSM API Python Bindings library works similar to other C Python binding libraries. CSM APIs can be accessed in Python because they are bound to C via Boost. More technical details can be found here: https://wiki.python.org/moin/boost.python/GettingStarted but understanding all of this is not required to use CSM APIs in Python. This guide provides a central location for users looking to utilize CSM APIs via Python. If you believe this guide to be incomplete, then please make a pull request with your additional content.
User Notes¶
Accessing CSM APIs in Python is very similar to accessing them in C. If you are familiar with the process, then you are already in a good position. If not, then the CSM API team suggest reading up on some CSM API documentation and guides.
Importing¶
Before writing your script and accessing CSM APIs, you must first import the CSM library into your script.
import sys #add the python library to the path sys.path.append('/opt/ibm/csm/lib') import lib_csm_py as csm import lib_csm_inv_py as invFirst you should say where the library is located. Which is what we did above in the first section.
import sys #add the python library to the path sys.path.append('/opt/ibm/csm/lib')Second, you should import the main CSM library
lib_csm_py. We did this and then nicknamed itcsmfor ease of use later in our script.import lib_csm_py as csmThen, you should import any appropriate sub libraries for the CSM APIs that you will be using. If you want workload manager APIs such as
csm_allocation_querythen import the workload manager librarylib_csm_wm_py. If you want inventory APIs, such ascsm_node_attributes_update, then import the inventory librarylib_csm_inv_py. Look at CSM API documentation for a full list of all CSM API libraries.For my example, I have imported the inventory library and nicknamed it
invfor ease of use later.import lib_csm_inv_py as invConnection to CSM¶
At this point, a Python script can connect to CSM the same way a user would connect to CSM in the C language. You must connect to CSM by running the CSM init function before calling any CSM APIs. This init function is located in the main CSM library we imported earlier.
In Python, we do this below:
csm.init_lib()Just like in C, this function takes care of connecting to CSM.
Accessing the CSM API¶
Below I have some code from an example script of setting a node to
IN_SERVICEviacsm_node_attributes_updateinput = inv.node_attributes_update_input_t() nodes=["allie","node_01","bobby"] input.set_node_names(nodes) input.state = csm.csmi_node_state_t.CSM_NODE_IN_SERVICE rc,handler,output = inv.node_attributes_update(input) print rc if rc == csm.csmi_cmd_err_t.CSMERR_UPDATE_MISMATCH: print output.failure_count for i in range(0, output.failure_count): print output.get_failure_node_names(i)Let’s break down some important lines here for first time users of the CSM Python library.
input = inv.node_attributes_update_input_t()Here we are doing a few things. Just like in C, before we call the API we need to set up the input for the API. We do this on this line. Because this is an inventory API, we can find its input struct in the inventory library we imported earlier via
inv, and we create this asinput.We now fill
input.When using the CSM Python library arrays must be
setandget.nodes=["allie","node_01","bobby"] input.set_node_names(nodes) input.state = csm.csmi_node_state_t.CSM_NODE_IN_SERVICEFirst we create an array in Python.
nodes=["allie","node_01","bobby"]Then we use the CSM Python library functionset_ARRAYNAME(array)to set thenode_namesfield ofinput. We do not need to setnode_names_countlike we do in C. theset_function will take care of that for you. Finally, we callinput.state = csm.csmi_node_state_t.CSM_NODE_IN_SERVICEto set the state field of input toIN_SERVICE. This will tell CSM to set these 3 nodes toIN_SERVICE.In the next line of code we call the csm API passing in the input we just populated.
rc,handler,output = inv.node_attributes_update(input)Our CSM library returns 3 values.
- A return code - Here defined as
rc. This is the same as the return code found in the C version of the API.- A handler - An identifier used in the
csm.api_object_destroyfunction.- The API output - Here defined as output. This is the same as the output prarmeter found in the C version of the API. We will use this to access any output from the API. Similar to how you woul duse it in the C version.
If you noticed before I set
nodes=["allie","node_01","bobby"].allieandbobbyare not real nodes. So, the API will have some output data for us to check.print rc if rc == csm.csmi_cmd_err_t.CSMERR_UPDATE_MISMATCH: print output.failure_count for i in range(0, output.failure_count): print output.get_failure_node_names(i)The end of our sample script here first prints the return code, then if it matches the
CSMERR_UPDATE_MISMATCHprints additional information. Checking error codes and return codes from an API can be useful. The values are the same as the C APIs. Look at CSM API documentation for a full list of all CSM API return codes. Just like in the C version of APIs, error codes are found in the common API folder, which was included earlier ascsm.Next we print out all the names of the nodes that could not be updated in the CSM database. To do this, we must access an array.
Arrays in the CSM Python library must be accessed using this
get_function. Following the pattern ofget_ARRAYNAME. The array names and fields of a CSM struct are the same as the C versions. Please look at CSM API documentation for a list of your struct and struct field names.So in our example here, our struct has an array named
failure_node_names. To access it, we must callget_failure_node_names(i).ihere represents the element we want to access. Just like in the C version,output.failure_counttells us how many elements are in our array.This example keeps it simple and doesn’t do anything too crazy. We just loop through the array and print all the node names that did not update.
Cleaning Up and Closing Connection to CSM¶
Just like in C, when you are done communicating with CSM you must clean up and close connection. You call the same functions you would in C.
api_object_destroyandterm_lib. This will clean up memory and terminate connection to CSM.csm.api_object_destroy(handler) csm.term_lib()Conclusion¶
This concludes the walkthrough of using the CSM Python library. If you have further question, then you can contact: https://github.com/NickyDaB . If you want more samples to analyze, then explore:
CAST/csmi/python_samples.FAQ - Frequently Asked Questions¶
How do I access and set arrays in the CSM Python library.¶
When using the CSM Python library arrays must be
setandget.Get¶ Example:
if(result.dimms_count > 0): print(" dimms:") for j in range (0, result.dimms_count): dimm = result.get_dimms(j) print(" - serial_number: " + str(dimm.serial_number))Here let’s assume that the dimms_count is > 0. Let’s say 3. The code will loop through each dimm, printing its serial number. The important line here is:
dimm = result.get_dimms(j)here we are accessing an array.Arrays in the CSM Python library must be accessed using this
get_function. Following the pattern ofget_ARRAYNAME. The array names and fields of a CSM struct are the same as the C versions. Please look at CSM API documentation for a list of your struct and struct field names.So in our example here, our struct has an array named
dimms. To access it, we must callget_dimms(j).jhere represents the element we want to access.dimmrepresents how we will store this element.Once stored,
dimmcan be accessed like any other struct.print(" - serial_number: " + str(dimm.serial_number))Set¶ Example:
input = inv.node_attributes_update_input_t() nodes=["node_01","node_02","node_03"] input.set_node_names(nodes) input.state = csm.csmi_node_state_t.CSM_NODE_IN_SERVICEHere we want to use
csm_node_attributes_updateto set a few nodes toIN_SERVICE. The API’s input takes in a list of nodes. So in Python we will need to set this array of node names. The important line here is:input.set_node_names(nodes)here we are setting the array of the struct to an array we previously created.Before we can call
set_node_names(nodes)we need to populatenodes.nodes=["node_01","node_02","node_03"]Once
nodeshas been defined, we can call:set_node_names(nodes).Arrays in the CSM Python library must be set using this
set_function. Following the pattern ofset_ARRAYNAME. Theset_function requires a single parameter of a populated array. (Here that isnodes.) The array names and fields of a CSM struct are the same as the C versions. Please look at CSM API documentation for a list of your struct and struct field names.So in our example here, our struct has an array named
node_names. To set it, we must callinput.set_node_names(nodes).nodeshere represents the Python array we already created in the previous line.inputrepresents the parent struct that contains this array.Why am I getting an error when I use “set_ARRAY()” with my python list?¶
Common errors:
TypeError: No registered converter was able to produce a C++ rvalue of type std::string from this Python object of type unicodeTraceback (most recent call last): File "node_attributes_query_with_xcat.py", line 95, in <module> input.set_node_names(nodes_j) Boost.Python.ArgumentError: Python argument types in node_attributes_query_input_t.set_node_names(node_attributes_query_input_t, dict) did not match C++ signature: set_node_names(csm_node_attributes_query_input_t {lvalue}, boost::python::list {lvalue} e)When using the
set_function to set astringarray for CSM. The python list should be encoded viautf8. A list encoded viaunicodecan not be properly set.Example:
nodes_j1 = [x.encode('utf8') for x in nodes_j]Soft Failure Recovery¶
CSM defines a set of mechanisms for recovering from Soft Failure events.
A Soft Failure is an event which is considered to be largely intermittent. Generally, a soft failure may be caused by a networking issue or a failure in the Prolog/Epilog. CSM has a set of conditions for which it will trigger a Soft Failure to prevent scheduling until the intermitten failure is complete. It is also expected that system administrators will define Soft Failure events in their Prolog/Epilog.
When a node is placed into Soft Failure it must be returned to In Service before the scheduler will be allowed to select the node for further allocations. If the node exceeds a user specified retry count (either via recurring task or commandline) the node will be moved from Soft Failure to Hard Failure.
Success for moving from Soft Failure to In Service is determined by three metrics:
- CSM is able to clear all CGroups (soft failure means the node should host no allocations).
- The admin defined Recovery Script executed and returned zero.
- The recovery process didn’t timeout.
The following diagram is a high level abstraction of the state machine interacted with by the soft failure recovery mechanism:
Recurring Task Configuration¶
To configure the Soft Failure recovery mechanism, please refer to the soft_fail_recovery documentation.
Additionally, depending on the complexity of the Recovery Script, the admin should modify the API Configuration timeout time of csm_soft_failure_recovery to account for at least twice the projected runtime of the recovery script.
Command Line Interface¶
CSM provides a command line script to trigger a Soft Failure recovery. Invocation is as follows:
/opt/ibm/csm/bin/csm_soft_failure_recovery -r <retry_threshold>The -r or –retry option sets a retry threshold if this threshold is exceeded or met by any nodes that failed to be placed into In Service the node will be moved to Hard Failure.
Attention
Nodes that are in Soft Failure and owned by an allocation will NOT be processed by this utility!
Recovery Script¶
Attention
A recovery script must be located at /opt/ibm/csm/recovery/soft_failure_recovery to use the Soft Failure recovery mechanism!
A sample of the recovery script is placed in /opt/ibm/csm/share/recovery when installing the ibm-csm-core rpm. The sample script is extremely basic and is expected to be modified by the end user.
A recovery script must fit the following criteria:
- Be located at /opt/ibm/csm/recovery/soft_failure_recovery.
- Return 0 if the recovery was a success.
- Return > 0 in the event the recovery failed.
The recovery script takes no input parameters at this time.
Change Log¶
- 1.6.0
- 1.4.0
- Enum Types
- Struct Types
- Workload Management
- csmi_allocation_gpu_metrics_t
- csmi_allocation_mcast_context_t
- csmi_allocation_mcast_payload_request_t
- csmi_allocation_mcast_payload_response_t
- csmi_jsrun_cmd_payload_t
- csmi_soft_failure_recovery_payload_t
- csm_soft_failure_recovery_node_t
- csm_soft_failure_recovery_input_t
- csm_soft_failure_recovery_output_t
- Inventory
- Common
1.6.0¶
The following document has been automatically generated to act as a change log for CSM version 1.6.0.
Struct Types¶
Burst Buffer¶ csm_bb_lv_delete_input_t¶ New Data Type
- int64_t allocation_id
- int64_t num_bytes_read
- int64_t num_bytes_written
- char* logical_volume_name
- char* node_name
- int64_t num_reads
- int64_t num_writes
Inventory¶ csmi_switch_inventory_record_t¶ New Data Type
- char* name
- char* host_system_guid
- char* discovery_time
- char* collection_time
- char* comment
- char* description
- char* device_name
- char* device_type
- char* hw_version
- int32_t max_ib_ports
- int32_t module_index
- int32_t number_of_chips
- char* path
- char* serial_number
- char* severity
- char* status
- char* type
- char* fw_version
csm_ib_cable_query_input_t¶ New Data Type
- int32_t limit
- int32_t offset
- uint32_t serial_numbers_count
- char** serial_numbers
- uint32_t comments_count
- char** comments
- uint32_t guids_count
- char** guids
- uint32_t identifiers_count
- char** identifiers
- uint32_t lengths_count
- char** lengths
- uint32_t names_count
- char** names
- uint32_t part_numbers_count
- char** part_numbers
- uint32_t ports_count
- char** ports
- uint32_t revisions_count
- char** revisions
- uint32_t severities_count
- char** severities
- uint32_t types_count
- char** types
- uint32_t widths_count
- char** widths
- char order_by
1.4.0¶
The following document has been automatically generated to act as a change log for CSM version 1.4.0.
Enum Types¶
Common¶ csmi_cmd_err_t¶
- Added 10
- CSMERR_ALLOC_INVALID_NODES=46
- CSMERR_ALLOC_OCCUPIED_NODES=47
- CSMERR_ALLOC_UNAVAIL_NODES=48
- CSMERR_ALLOC_BAD_FLAGS=49
- CSMERR_ALLOC_MISSING=50
- CSMERR_EPILOG_EPILOG_COLLISION=51
- CSMERR_EPILOG_PROLOG_COLLISION=52
- CSMERR_PROLOG_EPILOG_COLLISION=53
- CSMERR_PROLOG_PROLOG_COLLISION=54
- CSMERR_SOFT_FAIL_RECOVERY_AGENT=55
csmi_node_state_t¶
- New Data Type
- CSM_NODE_NO_DEF=0
- CSM_NODE_DISCOVERED=1
- CSM_NODE_IN_SERVICE=2
- CSM_NODE_OUT_OF_SERVICE=3
- CSM_NODE_SYS_ADMIN_RESERVED=4
- CSM_NODE_SOFT_FAILURE=5
- CSM_NODE_MAINTENANCE=6
- CSM_NODE_DATABASE_NULL=7
- CSM_NODE_HARD_FAILURE=8
Struct Types¶
Workload Management¶ csmi_allocation_gpu_metrics_t¶
- New Data Type
- int64_t num_gpus
- int32_t* gpu_id
- int64_t* gpu_usage
- int64_t* max_gpu_memory
- int64_t num_cpus
- int64_t* cpu_usage
csmi_allocation_mcast_context_t¶
- New Data Type
- int64_t allocation_id
- int64_t primary_job_id
- int32_t num_processors
- int32_t num_gpus
- int32_t projected_memory
- int32_t secondary_job_id
- int32_t isolated_cores
- uint32_t num_nodes
- csmi_state_t state
- csmi_allocation_type_t type
- int64_t* ib_rx
- int64_t* ib_tx
- int64_t* gpfs_read
- int64_t* gpfs_write
- int64_t* energy
- int64_t* gpu_usage
- int64_t* cpu_usage
- int64_t* memory_max
- int64_t* power_cap_hit
- int32_t* power_cap
- int32_t* ps_ratio
- csm_bool shared
- char save_allocation
- char** compute_nodes
- char* user_flags
- char* system_flags
- char* user_name
- int64_t* gpu_energy
- char* timestamp
- csmi_state_t start_state
- int64_t runtime
- csmi_allocation_gpu_metrics_t** gpu_metrics
csmi_allocation_mcast_payload_request_t¶
- Added 1
- int64_t runtime
csmi_allocation_mcast_payload_response_t¶ New Data Type
- int64_t energy
- int64_t pc_hit
- int64_t gpu_usage
- int64_t ib_rx
- int64_t ib_tx
- int64_t gpfs_read
- int64_t gpfs_write
- int64_t cpu_usage
- int64_t memory_max
- int32_t power_cap
- int32_t ps_ratio
- char create
- char* hostname
- int64_t gpu_energy
- csmi_cmd_err_t error_code
- char* error_message
- csmi_allocation_gpu_metrics_t* gpu_metrics
csmi_jsrun_cmd_payload_t¶ Added 4
- uint32_t num_nodes
- char** compute_nodes
- char* launch_node
- csmi_allocation_type_t type
csmi_soft_failure_recovery_payload_t¶ New Data Type
- char* hostname
- csmi_cmd_err_t error_code
- char* error_message
csm_soft_failure_recovery_output_t¶ New Data Type
- uint32_t error_count
- csm_soft_failure_recovery_node_t** node_errors
Inventory¶ csm_ib_cable_inventory_collection_output_t¶ New Data Type
- int32_t insert_count
- int32_t update_count
- int32_t delete_count
csm_switch_attributes_query_input_t¶ New Data Type
- int32_t limit
- int32_t offset
- uint32_t switch_names_count
- char* state
- char** switch_names
- char* serial_number
- char order_by
- uint32_t roles_count
- char** roles
csm_switch_inventory_collection_output_t¶ New Data Type
- char TBD
- int32_t insert_count
- int32_t update_count
- int32_t delete_count
- int32_t delete_module_count
csm_switch_children_inventory_collection_output_t¶ New Data Type
- int32_t insert_count
- int32_t update_count
- int32_t delete_count
Common¶ csmi_err_t¶ New Data Type
- int errcode
- char* errmsg
- uint32_t error_count
- csm_node_error_t** node_errors
Database¶
CSM Database (CSM DB) holds information about systems hardware configuration, hardware inventory, RAS, diagnostics, job steps, job allocations, and CSM configuration. This information is essential for the CORAL system to run properly and for resources accounting.
CSM DB uses PostgreSQL.
CSM Database Appendix¶
Naming conventions¶
CSM Database Overview
Table Primary Key Unique Key Foreign key Index Functions Triggers History Tables¶
CSM DB keeps track of data as it change over time. History tables will be used to store these records and a history time stamp is generated to indicate the transaction has completed. The information will remain in this table until further action is taken.Usage and Size¶
The usage and size of each table will vary depending on system size and system activity. This document tries to estimate the usage and size of the tables. Usage is defined as how often a table is accessed and is recorded asLow,Medium, orHigh. Size indicates how many rows are within the database tables and is recorded as total number of rows.Table Categories¶
The CSM database tables are grouped and color coordinated to demonstrate which category they belong to within the schema. These categories include,
Tables¶
Node attributes tables¶
csm_node¶ Description
This table contains the attributes of all the nodes in the CORAL system including: management node, service node, login node, work load manager, launch node, and compute node.
Table Overview Action On: Usage Size Key(s) Index Functions Triggers
Referenced by table Constraint Fields Key csm_allocation_node csm_allocation_node_node_name_fkey node_name (FK) csm_dimm csm_dimm_node_name_fkey node_name (FK) csm_gpu csm_gpu_node_name_fkey node_name (FK) csm_hca csm_hca_node_name_fkey node_name (FK) csm_processor csm_processor_node_name_fkey node_name (FK) csm_ssd csm_ssd_node_name_fkey node_name (FK) csm_node (DB table overview)¶
Table "public.csm_node" Column | Type | Modifiers | Storage | Stats target | Description -------------------------+-----------------------------+-----------+----------+--------------+--------------------------------------------------------------------------------------------------------------------- node_name | text | not null | extended | | identifies which node this information is for machine_model | text | | extended | | machine type model information for this node serial_number | text | | extended | | witherspoon boards serial number collection_time | timestamp without time zone | | plain | | the time the node was collected at inventory update_time | timestamp without time zone | | plain | | the time the node was updated state | compute_node_states | | plain | | state of the node - DISCOVERED, IN_SERVICE, ADMIN_RESERVED, MAINTENANCE, SOFT_FAILURE, OUT_OF_SERVICE, HARD_FAILURE type | text | | extended | | management, service, login, workload manager, launch, compute primary_agg | text | | extended | | primary aggregate secondary_agg | text | | extended | | secondary aggregate hard_power_cap | integer | | plain | | hard power cap for this node installed_memory | bigint | | plain | | amount of installed memory on this node (in kB) installed_swap | bigint | | plain | | amount of available swap space on this node (in kB) discovered_sockets | integer | | plain | | number of processors on this node (processor sockets, non-uniform memory access (NUMA) nodes) discovered_cores | integer | | plain | | number of physical cores on this node from all processors discovered_gpus | integer | | plain | | number of gpus available discovered_hcas | integer | | plain | | number of IB HCAs discovered in this node during the most recent inventory collection discovered_dimms | integer | | plain | | number of dimms discovered in this node during the most recent inventory collection discovered_ssds | integer | | plain | | number of ssds discovered in this node during the most recent inventory collection os_image_name | text | | extended | | xCAT os image name being run on this node, diskless images only os_image_uuid | text | | extended | | xCAT os image uuid being run on this node, diskless images only kernel_release | text | | extended | | kernel release being run on this node kernel_version | text | | extended | | linux kernel version being run on this node physical_frame_location | text | | extended | | physical frame number where the node is located physical_u_location | text | | extended | | physical u location (position in the frame) where the node is located feature_1 | text | | extended | | reserved fields for future use feature_2 | text | | extended | | reserved fields for future use feature_3 | text | | extended | | reserved fields for future use feature_4 | text | | extended | | reserved fields for future use comment | text | | extended | | comment field for system administrators Indexes: "csm_node_pkey" PRIMARY KEY, btree (node_name) "ix_csm_node_a" btree (node_name, state) Check constraints: "csm_not_blank" CHECK (btrim(node_name, ' '::text) <> ''::text) "csm_not_null_string" CHECK (node_name <> ''::text) Referenced by: TABLE "csm_allocation_node" CONSTRAINT "csm_allocation_node_node_name_fkey" FOREIGN KEY (node_name) REFERENCES csm_node(node_name) TABLE "csm_dimm" CONSTRAINT "csm_dimm_node_name_fkey" FOREIGN KEY (node_name) REFERENCES csm_node(node_name) TABLE "csm_gpu" CONSTRAINT "csm_gpu_node_name_fkey" FOREIGN KEY (node_name) REFERENCES csm_node(node_name) TABLE "csm_hca" CONSTRAINT "csm_hca_node_name_fkey" FOREIGN KEY (node_name) REFERENCES csm_node(node_name) TABLE "csm_processor_socket" CONSTRAINT "csm_processor_socket_node_name_fkey" FOREIGN KEY (node_name) REFERENCES csm_node(node_name) TABLE "csm_ssd" CONSTRAINT "csm_ssd_node_name_fkey" FOREIGN KEY (node_name) REFERENCES csm_node(node_name) Triggers: tr_csm_node_state BEFORE INSERT OR UPDATE OF state ON csm_node FOR EACH ROW EXECUTE PROCEDURE fn_csm_node_state() tr_csm_node_update BEFORE INSERT OR DELETE OR UPDATE OF node_name, machine_model, serial_number, collection_time, type, primary_agg, secondary_agg, hard_power_cap, installed_memory, installed_swap, discovered_sockets, discovered_cores, discovered_gpus, discovered_hcas, discovered_dimms, discovered_ssds, os_image_name, os_image_uuid, kernel_release, kernel_version, physical_frame_location, physical_u_location, feature_1, feature_2, feature_3, feature_4, comment ON csm_node FOR EACH ROW EXECUTE PROCEDURE fn_csm_node_update() Has OIDs: nocsm_node_history¶
- Description
- This table contains the historical information related to node attributes.
Table Overview Action On: Usage Size Index csm_node_history (DB table overview)¶
Table "public.csm_node_history" Column | Type | Modifiers | Storage | Stats target | Description -------------------------+-----------------------------+-----------+----------+--------------+--------------------------------------------------------------------------------------------------------------------- history_time | timestamp without time zone | | plain | | time when the node is entered into the history table node_name | text | | extended | | identifies which node this information is for machine_model | text | | extended | | machine type model information for this node serial_number | text | | extended | | witherspoon boards serial number collection_time | timestamp without time zone | | plain | | the time the node was collected at inventory update_time | timestamp without time zone | | plain | | the time the node was updated state | compute_node_states | | plain | | state of the node - DISCOVERED, IN_SERVICE, ADMIN_RESERVED, MAINTENANCE, SOFT_FAILURE, OUT_OF_SERVICE, HARD_FAILURE type | text | | extended | | management, service, login, workload manager, launch, compute primary_agg | text | | extended | | primary aggregate secondary_agg | text | | extended | | secondary aggregate hard_power_cap | integer | | plain | | hard power cap for this node installed_memory | bigint | | plain | | amount of installed memory on this node (in kB) installed_swap | bigint | | plain | | amount of available swap space on this node (in kB) discovered_sockets | integer | | plain | | number of processors on this node (processor sockets, non-uniform memory access (NUMA) nodes) discovered_cores | integer | | plain | | number of physical cores on this node from all processors discovered_gpus | integer | | plain | | number of gpus available discovered_hcas | integer | | plain | | number of IB HCAs discovered in this node during inventory collection discovered_dimms | integer | | plain | | number of dimms discovered in this node during inventory collection discovered_ssds | integer | | plain | | number of ssds discovered in this node during inventory collection os_image_name | text | | extended | | xCAT os image name being run on this node, diskless images only os_image_uuid | text | | extended | | xCAT os image uuid being run on this node, diskless images only kernel_release | text | | extended | | linux kernel release being run on this node kernel_version | text | | extended | | linux kernel version being run on this node physical_frame_location | text | | extended | | physical frame number where the node is located physical_u_location | text | | extended | | physical u location (position in the frame) where the node is located feature_1 | text | | extended | | reserved fields for future use feature_2 | text | | extended | | reserved fields for future use feature_3 | text | | extended | | reserved fields for future use feature_4 | text | | extended | | reserved fields for future use comment | text | | extended | | comment field for system administrators operation | character(1) | not null | extended | | operation of transaction (I - INSERT), (U - UPDATE), (D - DELETE) archive_history_time | timestamp without time zone | | plain | | timestamp when the history data has been archived and sent to: BDS, archive file, and or other Indexes: "ix_csm_node_history_a" btree (history_time) "ix_csm_node_history_b" btree (node_name) "ix_csm_node_history_d" btree (archive_history_time) Has OIDs: nocsm_node_state_history¶
- Description
- This table contains historical information related to the node state status. This table will be updated each time the node status status changes.
Table Overview Action On: Usage Size Index csm_node_state_history (DB table overview)¶
Table "public.csm_node_state_history" Column | Type | Modifiers | Storage | Stats target | Description ----------------------+-----------------------------+-----------+----------+--------------+--------------------------------------------------------------------------------------------------------------------- history_time | timestamp without time zone | | plain | | time when the node ready status is entered into the history table node_name | text | | extended | | identifies which node this information is for state | compute_node_states | | plain | | state of the node - DISCOVERED, IN_SERVICE, ADMIN_RESERVED, MAINTENANCE, SOFT_FAILURE, OUT_OF_SERVICE, HARD_FAILURE operation | character(1) | not null | extended | | operation of transaction (I - INSERT), (U - UPDATE), (D - DELETE) archive_history_time | timestamp without time zone | | plain | | timestamp when the history data has been archived and sent to: BDS, archive file, and or other Indexes: "ix_csm_node_state_history_a" btree (history_time) "ix_csm_node_state_history_b" btree (node_name, state) "ix_csm_node_state_history_d" btree (archive_history_time) Has OIDs: nocsm_processor_socket¶
- Description
- This table contains information on the processors of a node.
Table Overview Action On: Usage Size Key(s) Index Functions Triggers csm_processor_socket (DB table overview)¶
Table "public.csm_processor_socket" Column | Type | Modifiers | Storage | Stats target | Description -------------------+---------+-----------+----------+--------------+-------------------------------------------- serial_number | text | not null | extended | | unique identifier for this processor node_name | text | not null | extended | | where does this processor reside physical_location | text | | extended | | physical location of the processor discovered_cores | integer | | plain | | number of physical cores on this processor Indexes: "csm_processor_socket_pkey" PRIMARY KEY, btree (serial_number, node_name) Foreign-key constraints: "csm_processor_socket_node_name_fkey" FOREIGN KEY (node_name) REFERENCES csm_node(node_name) Triggers: tr_csm_processor_socket_history_dump BEFORE INSERT OR DELETE OR UPDATE ON csm_processor_socket FOR EACH ROW EXECUTE PROCEDURE fn_csm_processor_socket_history_dump() Has OIDs: nocsm_processor_socket_history¶
- Description
- This table contains historical information associated with individual processors.
Table Overview Action On: Usage Size Index csm_processor_socket_history (DB table overview)¶
Table "public.csm_processor_socket_history" Column | Type | Modifiers | Storage | Stats target | Description ----------------------+-----------------------------+-----------+----------+--------------+------------------------------------------------------------------------------------------------ history_time | timestamp without time zone | not null | plain | | the time when the processor is entering the history table serial_number | text | not null | extended | | unique identifier for this processor node_name | text | | extended | | where does this processor reside physical_location | text | | extended | | physical location of the processor discovered_cores | integer | | plain | | number of physical cores on this processor operation | character(1) | not null | extended | | operation of transaction (I - INSERT), (U - UPDATE), (D - DELETE) archive_history_time | timestamp without time zone | | plain | | timestamp when the history data has been archived and sent to: BDS, archive file, and or other Indexes: "ix_csm_processor_socket_history_a" btree (history_time) "ix_csm_processor_socket_history_b" btree (serial_number, node_name) "ix_csm_processor_socket_history_d" btree (archive_history_time) Has OIDs: nocsm_gpu¶
- Description
- This table contains information on the GPUs on the node.
Table Overview Action On: Usage Size Key(s) Index Functions Triggers csm_gpu (DB table overview)¶
Table "public.csm_gpu" Column | Type | Modifiers | Storage | Stats target | Description -----------------------+---------+-----------+----------+--------------+----------------------------------------------------------------------- serial_number | text | not null | extended | | unique identifier for this gpu node_name | text | not null | extended | | where does this gpu reside gpu_id | integer | not null | plain | | gpu identification number device_name | text | not null | extended | | indicates the device name pci_bus_id | text | not null | extended | | Peripheral Component Interconnect bus identifier uuid | text | not null | extended | | universally unique identifier vbios | text | not null | extended | | Video BIOS inforom_image_version | text | not null | extended | | version of the infoROM hbm_memory | bigint | | plain | | high bandwidth memory: amount of available memory on this gpu (in kB) Indexes: "csm_gpu_pkey" PRIMARY KEY, btree (node_name, gpu_id) Foreign-key constraints: "csm_gpu_node_name_fkey" FOREIGN KEY (node_name) REFERENCES csm_node(node_name) Triggers: tr_csm_gpu_history_dump BEFORE INSERT OR DELETE OR UPDATE ON csm_gpu FOR EACH ROW EXECUTE PROCEDURE fn_csm_gpu_history_dump() Has OIDs: nocsm_gpu_history¶
- Description
- This table contains historical information associated with individual GPUs. The GPU will be recorded and also be timestamped.
Table Overview Action On: Usage Size Index csm_gpu_history (DB table overview)¶
Table "public.csm_gpu_history" Column | Type | Modifiers | Storage | Stats target | Description -----------------------+-----------------------------+-----------+----------+--------------+------------------------------------------------------------------------------------------------ history_time | timestamp without time zone | not null | plain | | the time when the gpu is entering the history table serial_number | text | not null | extended | | unique identifier for this gpu node_name | text | | extended | | where does this gpu reside gpu_id | integer | not null | plain | | gpu identification number device_name | text | not null | extended | | indicates the device name pci_bus_id | text | not null | extended | | Peripheral Component Interconnect bus identifier uuid | text | not null | extended | | universally unique identifier vbios | text | not null | extended | | Video BIOS inforom_image_version | text | not null | extended | | version of the infoROM hbm_memory | bigint | | plain | | high bandwidth memory: amount of available memory on this gpu (in kB) operation | character(1) | not null | extended | | operation of transaction (I - INSERT), (U - UPDATE), (D - DELETE) archive_history_time | timestamp without time zone | | plain | | timestamp when the history data has been archived and sent to: BDS, archive file, and or other Indexes: "ix_csm_gpu_history_a" btree (history_time) "ix_csm_gpu_history_b" btree (serial_number) "ix_csm_gpu_history_c" btree (node_name, gpu_id) "ix_csm_gpu_history_e" btree (archive_history_time) Has OIDs: nocsm_ssd¶
- Description
- This table contains information on the SSDs on the system. This table contains the current status of the SSD along with its capacity and wear.
Table Overview Action On: Usage Size Key(s) Index Functions Triggers
Referenced by table Constraint Fields Key csm_vg_ssd csm_vg_ssd_serial_number_fkey serial_number, node_name (FK) csm_ssd (DB table overview)¶
Table "public.csm_ssd" Column | Type | Modifiers | Storage | Stats target | Description -------------------------------+-----------------------------+-----------+----------+--------------+--------------------------------------------------------------------------- serial_number | text | not null | extended | | unique identifier for this ssd node_name | text | not null | extended | | where does this ssd reside update_time | timestamp without time zone | not null | plain | | timestamp when ssd was updated device_name | text | | extended | | product device name pci_bus_id | text | | extended | | PCI bus id fw_ver | text | | extended | | firmware version size | bigint | not null | plain | | total capacity (in bytes) of this ssd, for example, 800 gbs wear_lifespan_used | double precision | | plain | | estimate of the amount of SSD life consumed (w.l.m. will use - 0-255 per) wear_total_bytes_written | bigint | | plain | | number of bytes written to the SSD over the life of the device wear_total_bytes_read | bigint | | plain | | number of bytes read from the SSD over the life of the device wear_percent_spares_remaining | double precision | | plain | | amount of SSD capacity over-provisioning that remains Indexes: "csm_ssd_pkey" PRIMARY KEY, btree (serial_number, node_name) "uk_csm_ssd_a" UNIQUE, btree (serial_number, node_name) Foreign-key constraints: "csm_ssd_node_name_fkey" FOREIGN KEY (node_name) REFERENCES csm_node(node_name) Referenced by: TABLE "csm_vg_ssd" CONSTRAINT "csm_vg_ssd_serial_number_fkey" FOREIGN KEY (serial_number, node_name) REFERENCES csm_ssd(serial_number, node_name) Triggers: tr_csm_ssd_history_dump BEFORE INSERT OR DELETE OR UPDATE OF serial_number, node_name, device_name, pci_bus_id, fw_ver, size ON csm_ssd FOR EACH ROW EXECUTE PROCEDURE fn_csm_ssd_history_dump() tr_csm_ssd_wear BEFORE UPDATE OF wear_lifespan_used, wear_total_bytes_written, wear_total_bytes_read, wear_percent_spares_remaining ON csm_ssd FOR EACH ROW EXECUTE PROCEDURE fn_csm_ssd_wear() Has OIDs: nocsm_ssd_history¶
- Description
- This table contains historical information associated with individual SSDs.
Table Overview Action On: Usage Size Index csm_ssd_history (DB table overview)¶
Table "public.csm_ssd_history" Column | Type | Modifiers | Storage | Stats target | Description -------------------------------+-----------------------------+-----------+----------+--------------+------------------------------------------------------------------------------------------------ history_time | timestamp without time zone | not null | plain | | timestamp serial_number | text | not null | extended | | unique identifier for this ssd node_name | text | | extended | | where does this ssd reside update_time | timestamp without time zone | not null | plain | | timestamp when the ssd was updated device_name | text | | extended | | product device name pci_bus_id | text | | extended | | PCI bus id fw_ver | text | | extended | | firmware version size | bigint | not null | plain | | total capacity (in bytes) of this ssd, for example, 800 gbs wear_lifespan_used | double precision | | plain | | estimate of the amount of SSD life consumed (w.l.m. will use - 0-255 per) wear_total_bytes_written | bigint | | plain | | number of bytes written to the SSD over the life of the device wear_total_bytes_read | bigint | | plain | | number of bytes read from the SSD over the life of the device wear_percent_spares_remaining | double precision | | plain | | amount of SSD capacity over-provisioning that remains operation | character(1) | not null | extended | | operation of transaction (I - INSERT), (U - UPDATE), (D - DELETE) archive_history_time | timestamp without time zone | | plain | | timestamp when the history data has been archived and sent to: BDS, archive file, and or other Indexes: "ix_csm_ssd_history_a" btree (history_time) "ix_csm_ssd_history_b" btree (serial_number, node_name) "ix_csm_ssd_history_d" btree (archive_history_time) Has OIDs: nocsm_ssd_wear_history¶
- Description
- This table contains historical information on the ssds wear known to the system.
Table Overview Action On: Usage Size Index csm_ssd_wear_history (DB table overview)¶
Table "public.csm_ssd_wear_history" Column | Type | Modifiers | Storage | Stats target | Description -------------------------------+-----------------------------+-----------+----------+--------------+------------------------------------------------------------------------------------------------ history_time | timestamp without time zone | not null | plain | | timestamp serial_number | text | not null | extended | | unique identifier for this ssd node_name | text | | extended | | where does this ssd reside wear_lifespan_used | double precision | | plain | | estimate of the amount of SSD life consumed (w.l.m. will use - 0-255 per) wear_total_bytes_written | bigint | | plain | | number of bytes written to the SSD over the life of the device wear_total_bytes_read | bigint | | plain | | number of bytes read from the SSD over the life of the device wear_percent_spares_remaining | double precision | | plain | | amount of SSD capacity over-provisioning that remains operation | character(1) | not null | extended | | operation of transaction (I - INSERT), (U - UPDATE), (D - DELETE) archive_history_time | timestamp without time zone | | plain | | timestamp when the history data has been archived and sent to: BDS, archive file, and or other Indexes: "ix_csm_ssd_wear_history_a" btree (history_time) "ix_csm_ssd_wear_history_b" btree (serial_number, node_name) "ix_csm_ssd_wear_history_d" btree (archive_history_time) Has OIDs: nocsm_hca¶
- Description
- This table contains information about the HCA (Host Channel Adapters). Each HC adapter has a unique identifier (serial number). The table has a status indicator, board ID (for the IB adapter), and Infiniband (globally unique identifier (GUID)).
Table Overview Action On: Usage Size Key(s) Index Functions Triggers csm_hca (DB table overview)¶
Table "public.csm_hca" Column | Type | Modifiers | Storage | Stats target | Description ---------------+------+-----------+----------+--------------+----------------------------------- serial_number | text | not null | extended | | unique serial number for this HCA node_name | text | not null | extended | | node this HCA is installed in device_name | text | | extended | | product device name for this HCA pci_bus_id | text | not null | extended | | PCI bus id for this HCA guid | text | not null | extended | | sys_image_guid for this HCA part_number | text | | extended | | part number for this HCA fw_ver | text | | extended | | firmware version for this HCA hw_rev | text | | extended | | hardware revision for this HCA board_id | text | | extended | | board id for this HCA Indexes: "csm_hca_pkey" PRIMARY KEY, btree (node_name, serial_number) Foreign-key constraints: "csm_hca_node_name_fkey" FOREIGN KEY (node_name) REFERENCES csm_node(node_name) Triggers: tr_csm_hca_history_dump BEFORE INSERT OR DELETE OR UPDATE ON csm_hca FOR EACH ROW EXECUTE PROCEDURE fn_csm_hca_history_dump() Has OIDs: nocsm_hca_history¶
- Description
- This table contains historical information associated with the HCA (Host Channel Adapters).
Table Overview Action On: Usage Size Index csm_hca_history (DB table overview)¶
Table "public.csm_hca_history" Column | Type | Modifiers | Storage | Stats target | Description ----------------------+-----------------------------+-----------+----------+--------------+------------------------------------------------------------------------------------------------ history_time | timestamp without time zone | not null | plain | | the time when the HCA is entering the history table serial_number | text | not null | extended | | unique serial number for this HCA node_name | text | | extended | | node this HCA is installed in device_name | text | | extended | | product device name for this HCA pci_bus_id | text | not null | extended | | PCI bus id for this HCA guid | text | not null | extended | | sys_image_guid for this HCA part_number | text | | extended | | part number for this HCA fw_ver | text | | extended | | firmware version for this HCA hw_rev | text | | extended | | hardware revision for this HCA board_id | text | | extended | | board id for this HCA operation | character(1) | not null | extended | | operation of transaction (I - INSERT), (U - UPDATE), (D - DELETE) archive_history_time | timestamp without time zone | | plain | | timestamp when the history data has been archived and sent to: BDS, archive file, and or other Indexes: "ix_csm_hca_history_a" btree (history_time) "ix_csm_hca_history_b" btree (node_name, serial_number) "ix_csm_hca_history_d" btree (archive_history_time) Has OIDs: nocsm_dimm¶
- Description
- This table contains information related to the DIMM “”Dual In-Line Memory Module” attributes.
Table Overview Action On: Usage Size Key(s) Index Functions Triggers csm_dimm (DB table overview)¶
Table "public.csm_dimm" Column | Type | Modifiers | Storage | Stats target | Description -------------------+---------+-----------+----------+--------------+---------------------------------------------- serial_number | text | not null | extended | | this is the dimm serial number node_name | text | not null | extended | | where does this dimm reside size | integer | not null | plain | | the size can be 4, 8, 16, 32 GB physical_location | text | not null | extended | | phyical location where the dimm is installed Indexes: "csm_dimm_pkey" PRIMARY KEY, btree (serial_number, node_name) Foreign-key constraints: "csm_dimm_node_name_fkey" FOREIGN KEY (node_name) REFERENCES csm_node(node_name) Triggers: tr_csm_dimm_history_dump BEFORE INSERT OR DELETE OR UPDATE ON csm_dimm FOR EACH ROW EXECUTE PROCEDURE fn_csm_dimm_history_dump() Has OIDs: nocsm_dimm_history¶
- Description
- This table contains historical information related to the DIMM “Dual In-Line Memory Module” attributes.
Table Overview Action On: Usage Size Index csm_dimm_history (DB table overview)¶
Table "public.csm_dimm_history" Column | Type | Modifiers | Storage | Stats target | Description ----------------------+-----------------------------+-----------+----------+--------------+------------------------------------------------------------------------------------------------ history_time | timestamp without time zone | not null | plain | | this is when the information is entered into the history table serial_number | text | not null | extended | | this is the dimm serial number node_name | text | | extended | | where does this dimm reside size | integer | not null | plain | | the size can be 4, 8, 16, 32 GB physical_location | text | not null | extended | | physical location where the dimm is installed operation | character(1) | not null | extended | | operation of transaction (I - INSERT), (U - UPDATE), (D - DELETE) archive_history_time | timestamp without time zone | | plain | | timestamp when the history data has been archived and sent to: BDS, archive file, and or other Indexes: "ix_csm_dimm_history_a" btree (history_time) "ix_csm_dimm_history_b" btree (node_name, serial_number) "ix_csm_dimm_history_d" btree (archive_history_time) Has OIDs: noAllocation tables¶
csm_allocation¶
- Description
- This table contains the information about the system’s current allocations. See table below for details.
Table Overview Action On: Usage Size Key(s) Index Functions Triggers
Referenced by table Constraint Fields Key csm_allocation_node csm_allocation_node_allocation_id_fkey allocation_id (FK) csm_step csm_step_allocation_id_fkey allocation_id (FK) csm_allocation (DB table overview)¶
Table "public.csm_allocation" Column | Type | Modifiers | Storage | Stats target | Description ----------------------+-----------------------------+------------------------------------------------------------------------+----------+--------------+-------------------------------------------------------------------------------------------------------------------------- allocation_id | bigint | not null default nextval('csm_allocation_allocation_id_seq'::regclass) | plain | | unique identifier for this allocation primary_job_id | bigint | not null | plain | | primary job id (for lsf this will be the lsf job id) secondary_job_id | integer | | plain | | secondary job id (for lsf this will be the lsf job index for job arrays) ssd_file_system_name | text | | extended | | the filesystem name that the user wants (ssd) launch_node_name | text | not null | extended | | launch node name isolated_cores | integer | default 0 | plain | | cgroup: 0 - No cgroups, 1 - Allocation Cgroup, 2 - Allocation and Core Isolation Cgroup, >2 || <0 unsupported user_flags | text | | extended | | user space prolog/epilog flags system_flags | text | | extended | | system space prolog/epilog flags ssd_min | bigint | | plain | | minimum ssd size (in bytes) for this allocation ssd_max | bigint | | plain | | maximum ssd size (in bytes) for this allocation num_nodes | integer | not null | plain | | number of nodes in this allocation,also see csm_node_allocation num_processors | integer | not null | plain | | total number of processes running in this allocation num_gpus | integer | not null | plain | | the number of gpus that are available projected_memory | integer | not null | plain | | the amount of memory available state | text | not null | extended | | state can be: stage in allocation, running allocation, stage out allocation type | text | not null | extended | | shared allocation, user managed sub-allocation, pmix managed allocation, pmix managed allocation with c groups for steps job_type | text | not null | extended | | the type of job (batch or interactive) user_name | text | not null | extended | | user name user_id | integer | not null | plain | | user identification user_group_id | integer | not null | plain | | user group identification user_group_name | text | | extended | | user group name user_script | text | not null | extended | | user script information begin_time | timestamp without time zone | not null | plain | | timestamp when this allocation was created account | text | not null | extended | | account the job ran under comment | text | | extended | | comments for the allocation job_name | text | | extended | | jobname job_submit_time | timestamp without time zone | not null | plain | | the time and data stamp the job was submitted queue | text | | extended | | identifies the partition (queue) on which the job ran requeue | text | | extended | | identifies (requeue) if the allocation is requeued it will attempt to have the previous allocation id time_limit | bigint | not null | plain | | the time limit requested or imposed on the job wc_key | text | | extended | | arbitrary string for grouping orthogonal accounts together smt_mode | smallint | default 0 | plain | | the smt mode of the allocation core_blink | boolean | not null | plain | | flag indicating whether or not to run a blink operation on allocation cores. Indexes: "csm_allocation_pkey" PRIMARY KEY, btree (allocation_id) Referenced by: TABLE "csm_allocation_node" CONSTRAINT "csm_allocation_node_allocation_id_fkey" FOREIGN KEY (allocation_id) REFERENCES csm_allocation(allocation_id) TABLE "csm_step" CONSTRAINT "csm_step_allocation_id_fkey" FOREIGN KEY (allocation_id) REFERENCES csm_allocation(allocation_id) Triggers: tr_csm_allocation_state_change BEFORE INSERT OR UPDATE OF state ON csm_allocation FOR EACH ROW EXECUTE PROCEDURE fn_csm_allocation_state_history_state_change() tr_csm_allocation_update BEFORE UPDATE OF allocation_id, primary_job_id, secondary_job_id, ssd_file_system_name, launch_node_name, isolated_cores, user_flags, system_flags, ssd_min, ssd_max, num_nodes, num_processors, num_gpus, projected_memory, type, job_type, user_name, user_id, user_group_id, user_group_name, user_script, begin_time, account, comment, job_name, job_submit_time, queue, requeue, time_limit, wc_key, smt_mode, core_blink ON csm_allocation FOR EACH ROW EXECUTE PROCEDURE fn_csm_allocation_update() Has OIDs: nocsm_allocation_history¶
- Description
- This table contains the information about the no longer current allocations on the system. Essentially this is the historical information about allocations. This table will increase in size only based on how many allocations are deployed on the life cycle of the machine/system. This table will also be able to determine the total energy consumed per allocation (filled in during “free of allocation”).
Table Overview Action On: Usage Size Index csm_allocation_history (DB table overview)¶
Table "public.csm_allocation_history" Column | Type | Modifiers | Storage | Stats target | Description ----------------------+-----------------------------+-----------+----------+--------------+--------------------------------------------------------------------------------------------------------------- history_time | timestamp without time zone | | plain | | time when the allocation is entered into the history table allocation_id | bigint | | plain | | unique identifier for this allocation primary_job_id | bigint | not null | plain | | primary job id (for lsf this will be the lsf job id) secondary_job_id | integer | | plain | | secondary job id (for lsf this will be the lsf job index) ssd_file_system_name | text | | extended | | the filesystem name that the user wants (ssd) launch_node_name | text | not null | extended | | launch node name isolated_cores | integer | | plain | | cgroup: 0 - No cgroups, 1 - Allocation Cgroup, 2 - Allocation and Core Isolation Cgroup, >2 || <0 unsupported user_flags | text | | extended | | user space prolog/epilog flags system_flags | text | | extended | | system space prolog/epilog flags ssd_min | bigint | | plain | | minimum ssd size (in bytes) for this allocation ssd_max | bigint | | plain | | maximum ssd size (in bytes) for this allocation num_nodes | integer | not null | plain | | number of nodes in allocation, see csm_node_allocation num_processors | integer | not null | plain | | total number of processes running in this allocation num_gpus | integer | not null | plain | | the number of gpus that are available projected_memory | integer | not null | plain | | the amount of memory available state | text | not null | extended | | state of the node - stage in allocation, running allocation, stage out allocation type | text | not null | extended | | user managed sub-allocation, pmix managed allocation, pmix managed allocation with c groups for steps job_type | text | not null | extended | | the type of job (batch or interactive) user_name | text | not null | extended | | username user_id | integer | not null | plain | | user identification id user_group_id | integer | not null | plain | | user group identification user_group_name | text | | extended | | user group name user_script | text | not null | extended | | user script information begin_time | timestamp without time zone | not null | plain | | timestamp when this allocation was created end_time | timestamp without time zone | | plain | | timestamp when this allocation was freed exit_status | integer | | plain | | allocation exit status account | text | not null | extended | | account the job ran under comment | text | | extended | | comments for the allocation job_name | text | | extended | | job name job_submit_time | timestamp without time zone | not null | plain | | the time and date stamp the job was submitted queue | text | | extended | | identifies the partition (queue) on which the job ran requeue | text | | extended | | identifies (requeue) if the allocation is requeued it will attempt to have the previous allocation id time_limit | bigint | not null | plain | | the time limit requested or imposed on the job wc_key | text | | extended | | arbitrary string for grouping orthogonal accounts together archive_history_time | timestamp without time zone | | plain | | timestamp when the history data has been archived and sent to: BDS, archive file, and or other smt_mode | smallint | default 0 | plain | | the smt mode of the allocation core_blink | boolean | not_null | plain | | flag indicating whether or not to run a blink operation on allocation cores. Indexes: "ix_csm_allocation_history_a" btree (history_time) "ix_csm_allocation_history_b" btree (allocation_id) "ix_csm_allocation_history_d" btree (archive_history_time) Has OIDs: noStep tables¶
csm_step¶
- Description
- This table contains information on active steps within the CSM database. See table below for details.
Table Overview Action On: Usage Size Key(s) Index Functions
Referenced by table Constraint Fields Key csm_step_node csm_step_node_step_id_fkey step_id (FK) csm_step (DB table overview)¶
Table "public.csm_step" Column | Type | Modifiers | Storage | Stats target | Description ----------------------+-----------------------------+-----------+----------+--------------+------------------------------------------------------------ step_id | bigint | not null | plain | | uniquely identify this step allocation_id | bigint | not null | plain | | allocation that this step is part of begin_time | timestamp without time zone | not null | plain | | timestamp when this job step started status | text | not null | extended | | the active status of the step executable | text | not null | extended | | executable / command name / application name working_directory | text | not null | extended | | working directory argument | text | not null | extended | | arguments / parameters environment_variable | text | not null | extended | | environment variables num_nodes | integer | not null | plain | | the specific number of nodes that are involved in the step num_processors | integer | not null | plain | | total number of processes running in this step num_gpus | integer | not null | plain | | the number of gpus that are available projected_memory | integer | not null | plain | | the projected amount of memory available for the step num_tasks | integer | not null | plain | | total number of tasks in a job or step user_flags | text | | extended | | user space prolog/epilog flags Indexes: "csm_step_pkey" PRIMARY KEY, btree (step_id, allocation_id) "uk_csm_step_a" UNIQUE, btree (step_id, allocation_id) Foreign-key constraints: "csm_step_allocation_id_fkey" FOREIGN KEY (allocation_id) REFERENCES csm_allocation(allocation_id) Referenced by: TABLE "csm_step_node" CONSTRAINT "csm_step_node_step_id_fkey" FOREIGN KEY (step_id, allocation_id) REFERENCES csm_step(step_id, allocation_id) Has OIDs: nocsm_step_history¶
- Description
- This table contains the information for steps that have terminated. There is some additional information from the initial step that has been added to the history table. These attributes include: end time, compute nodes, level gpu usage, exit status, error text, network band width, cpu stats, total U time, total S time, total number of threads, gpu stats, memory stats, max memory, max swap, ios stats.
Table Overview Action On: Usage Size Index csm_step_history (DB table overview)¶
Table "public.csm_step_history" Column | Type | Modifiers | Storage | Stats target | Description ----------------------+-----------------------------+-----------+----------+--------------+---------------------------------------------------------------------------------------------------------------------------- history_time | timestamp without time zone | not null | plain | | timestamp when it enters the history table step_id | bigint | not null | plain | | uniquely identify this step allocation_id | bigint | not null | plain | | allocation that this step is part of begin_time | timestamp without time zone | not null | plain | | timestamp when this job step started end_time | timestamp without time zone | | plain | | timestamp when this step ended status | text | not null | extended | | the active operating status of the state executable | text | not null | extended | | executable / command name / application name working_directory | text | not null | extended | | working directory argument | text | not null | extended | | arguments / parameters environment_variable | text | not null | extended | | environment variables num_nodes | integer | not null | plain | | the specific number of nodes that are involved in the step num_processors | integer | not null | plain | | total number of processes running in this step num_gpus | integer | not null | plain | | the number of gpus available projected_memory | integer | not null | plain | | the number of memory available num_tasks | integer | not null | plain | | total number of tasks in a job or step user_flags | text | | extended | | user space prolog/epilog flags exit_status | integer | | plain | | step/s exit status. will be tracked and given to csm by job leader error_message | text | | extended | | step/s error text. will be tracked and given to csm by job leader. the following columns need their proper data types tbd: cpu_stats | text | | extended | | statistics gathered from the CPU for the step. total_u_time | double precision | | plain | | relates to the (us) (aka: user mode) value of %cpu(s) of the (top) linux cmd. todo: design how we get this data total_s_time | double precision | | plain | | relates to the (sy) (aka: system mode) value of %cpu(s) of the (top) linux cmd. todo: design how we get this data omp_thread_limit | text | | extended | | max number of omp threads used by the step. gpu_stats | text | | extended | | statistics gathered from the GPU for the step. memory_stats | text | | extended | | memory statistics for the the step (bytes). max_memory | bigint | | plain | | the maximum memory usage of the step (bytes). io_stats | text | | extended | | general input output statistics for the step. archive_history_time | timestamp without time zone | | plain | | timestamp when the history data has been archived and sent to: BDS, archive file, and or other Indexes: "ix_csm_step_history_a" btree (history_time) "ix_csm_step_history_b" btree (begin_time, end_time) "ix_csm_step_history_c" btree (allocation_id, end_time) "ix_csm_step_history_d" btree (end_time) "ix_csm_step_history_e" btree (step_id) "ix_csm_step_history_g" btree (archive_history_time) Has OIDs: noAllocation node, allocation state history, step node tables¶
csm_allocation_node¶
- Description
- This table maps current allocations to the compute nodes that make up the allocation. This information is later used when populating the csm_allocation_history table.
Table Overview Action On: Usage Size Key(s) Index Functions Triggers
Referenced by table Constraint Fields Key csm_lv csm_lv_allocation_id_fkey allocation_id, node_name (FK) csm_step_node csm_step_node_allocation_id_fkey allocation_id, node_name (FK) csm_allocation_node (DB table overview)¶
Table "public.csm_allocation_node" Column | Type | Modifiers | Storage | Stats target | Description ----------------------+---------+-----------+----------+--------------+-------------------------------------------------------------------------------------------------- allocation_id | bigint | not null | plain | | allocation that node_name is part of node_name | text | not null | extended | | identifies which node this is state | text | not null | extended | | state can be: stage in allocation, running allocation, stage out allocation shared | boolean | not null | plain | | indicates if the node resources are shareable energy | bigint | | plain | | the total energy used by the node in joules during the allocation gpfs_read | bigint | | plain | | bytes read counter (net) at the start of the allocation. gpfs_write | bigint | | plain | | bytes written counter (net) at the start of the allocation. ib_tx | bigint | | plain | | count of data octets transmitted on all port VLs (1/4 of a byte) at the start of the allocation. ib_rx | bigint | | plain | | Count of data octets received on all port VLs (1/4 of a byte) at the start of the allocation. power_cap | integer | | plain | | power cap currently in effect for this node (in watts) power_shifting_ratio | integer | | plain | | power power shifting ratio currently in effect for this node power_cap_hit | bigint | | plain | | total number of windowed ticks the processor frequency was reduced gpu_usage | bigint | | plain | | the total usage aggregated across all GPUs in the node in microseconds during the allocation gpu_energy | bigint | | plain | | the total energy used across all GPUs in the node in joules during the allocation cpu_usage | bigint | | plain | | the cpu usage in nanoseconds memory_usage_max | bigint | | plain | | The high water mark for memory usage (bytes). Indexes: "uk_csm_allocation_node_b" UNIQUE, btree (allocation_id, node_name) "ix_csm_allocation_node_a" btree (allocation_id) Foreign-key constraints: "csm_allocation_node_allocation_id_fkey" FOREIGN KEY (allocation_id) REFERENCES csm_allocation(allocation_id) "csm_allocation_node_node_name_fkey" FOREIGN KEY (node_name) REFERENCES csm_node(node_name) Referenced by: TABLE "csm_lv" CONSTRAINT "csm_lv_allocation_id_fkey" FOREIGN KEY (allocation_id, node_name) REFERENCES csm_allocation_node(allocation_id, node_name) TABLE "csm_step_node" CONSTRAINT "csm_step_node_allocation_id_fkey" FOREIGN KEY (allocation_id, node_name) REFERENCES csm_allocation_node(allocation_id, node_name) Triggers: tr_csm_allocation_node_change BEFORE UPDATE ON csm_allocation_node FOR EACH ROW EXECUTE PROCEDURE fn_csm_allocation_node_change() Has OIDs: nocsm_allocation_node_history¶
- Description
- This table maps history allocations to the compute nodes that make up the allocation.
Table Overview Action On: Usage Size Index csm_allocation_node_history (DB table overview)¶
Table "public.csm_allocation_node_history" Column | Type | Modifiers | Storage | Stats target | Description ----------------------+-----------------------------+-----------+----------+--------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- history_time | timestamp without time zone | not null | plain | | timestamp when it enters the history table allocation_id | bigint | not null | plain | | allocation that node_name is part of node_name | text | not null | extended | | identifies which node this is state | text | not null | extended | | state can be: stage in allocation, running allocation, stage out allocation shared | boolean | | plain | | indicates if the node resources are shareable energy | bigint | | plain | | the total energy used by the node in joules during the allocation gpfs_read | bigint | | plain | | total bytes read counter (net) at the during the allocation. Negative values represent the start reading, indicating the end was never writen to the database. gpfs_write | bigint | | plain | | total bytes written counter (net) at the during the allocation. Negative values represent the start reading, indicating the end was never writen to the database. ib_tx | bigint | | plain | | total count of data octets transmitted on all port VLs (1/4 of a byte) during the allocation. Negative values represent the start reading, indicating the end was never writen to the database. ib_rx | bigint | | plain | | total count of data octets received on all port VLs (1/4 of a byte) during the allocation. Negative values represent the start reading, indicating the end was never writen to the database. power_cap | integer | | plain | | power cap currently in effect for this node (in watts) power_shifting_ratio | integer | | plain | | power power shifting ratio currently in effect for this node power_cap_hit | bigint | | plain | | total number of windowed ticks the processor frequency was reduced gpu_usage | bigint | | plain | | the total usage aggregated across all GPUs in the node in microseconds during the allocation gpu_energy | bigint | | plain | | the total energy used across all GPUs in the node in joules during the allocation cpu_usage | bigint | | plain | | the cpu usage in nanoseconds memory_usage_max | bigint | | plain | | The high water mark for memory usage (bytes). archive_history_time | timestamp without time zone | | plain | | timestamp when the history data has been archived and sent to: BDS, archive file, and or other Indexes: "ix_csm_allocation_node_history_a" btree (history_time) "ix_csm_allocation_node_history_b" btree (allocation_id) "ix_csm_allocation_node_history_d" btree (archive_history_time) Has OIDs: nocsm_allocation_state_history¶
- Description
- This table contains the state of the active allocations history. A timestamp of when the information enters the table along with a state indicator.
Table Overview Action On: Usage Size Index csm_allocation_state_history (DB table overview)¶
Table "public.csm_allocation_state_history" Column | Type | Modifiers | Storage | Stats target | Description ----------------------+-----------------------------+-----------+----------+--------------+------------------------------------------------------------------------------------------------ history_time | timestamp without time zone | not null | plain | | timestamp when this allocation changes state allocation_id | bigint | | plain | | uniquely identify this allocation exit_status | integer | | plain | | the error code returned at the end of the allocation state state | text | not null | extended | | state of this allocation (stage-in, running, stage-out) archive_history_time | timestamp without time zone | | plain | | timestamp when the history data has been archived and sent to: BDS, archive file, and or other Indexes: "ix_csm_allocation_state_history_a" btree (history_time) "ix_csm_allocation_state_history_b" btree (allocation_id) "ix_csm_allocation_state_history_d" btree (archive_history_time) Has OIDs: nocsm_step_node¶
- Description
- This table maps active allocations to jobs steps and nodes.
Table Overview Action On: Usage Size Key(s) Index Functions Triggers csm_step_node (DB table overview)¶
Table "public.csm_step_node" Column | Type | Modifiers | Storage | Stats target | Description ---------------+--------+-----------+----------+--------------+-------------------------------------- step_id | bigint | not null | plain | | uniquely identify this step allocation_id | bigint | not null | plain | | allocation that this step is part of node_name | text | not null | extended | | identifies the node Indexes: "uk_csm_step_node_a" UNIQUE, btree (step_id, allocation_id, node_name) "ix_csm_step_node_b" btree (allocation_id) "ix_csm_step_node_c" btree (allocation_id, step_id) Foreign-key constraints: "csm_step_node_allocation_id_fkey" FOREIGN KEY (allocation_id, node_name) REFERENCES csm_allocation_node(allocation_id, node_name) "csm_step_node_step_id_fkey" FOREIGN KEY (step_id, allocation_id) REFERENCES csm_step(step_id, allocation_id) Triggers: tr_csm_step_node_history_dump BEFORE DELETE ON csm_step_node FOR EACH ROW EXECUTE PROCEDURE fn_csm_step_node_history_dump() Has OIDs: nocsm_step_node_history¶
- Description
- This table maps historical allocations to jobs steps and nodes.
Table Overview Action On: Usage Size Index csm_step_node_history (DB table overview)¶
Table "public.csm_step_node_history" Column | Type | Modifiers | Storage | Stats target | Description ----------------------+-----------------------------+-----------+----------+--------------+------------------------------------------------------------------------------------------------ history_time | timestamp without time zone | | plain | | historical time when information is added to the history table step_id | bigint | | plain | | uniquely identify this step allocation_id | bigint | | plain | | allocation that this step is part of node_name | text | | extended | | identifies the node archive_history_time | timestamp without time zone | | plain | | timestamp when the history data has been archived and sent to: BDS, archive file, and or other Indexes: "ix_csm_step_node_history_a" btree (history_time) "ix_csm_step_node_history_b" btree (allocation_id) "ix_csm_step_node_history_c" btree (allocation_id, step_id) "ix_csm_step_node_history_e" btree (archive_history_time) Has OIDs: noRAS tables¶
csm_ras_type¶
- Description
- This table contains the description and details for each of the possible RAS event types. See table below for details.
Table Overview Action On: Usage Size Key(s) Index Functions Triggers csm_ras_type (DB table overview)¶
Table "public.csm_ras_type" Column | Type | Modifiers | Storage | Stats target | Description ------------------+---------------------+-----------+----------+--------------+------------------------------------------------------------------------------------------------------------------------------------------------ msg_id | text | not null | extended | | the identifier string for this RAS event. It must be unique. typically it consists of three parts separated by periods (system.component.id). severity | ras_event_severity | not null | plain | | severity of the RAS event. INFO/WARNING/FATAL message | text | | extended | | ras message to display to the user (pre-variable substitution) description | text | | extended | | description of the ras event control_action | text | | extended | | name of control action script to invoke for this event. threshold_count | integer | | plain | | number of times this event has to occur during the (threshold_period) before taking action on the RAS event. threshold_period | integer | | plain | | period in seconds over which to compare the number of event occurences to the threshold_count ). enabled | boolean | | plain | | events will be processed if enabled=true and suppressed if enabled=false set_state | compute_node_states | | plain | | setting the state according to the node, DISCOVERED, IN_SERVICE, ADMIN_RESERVED, MAINTENANCE, SOFT_FAILURE, OUT_OF_SERVICE, HARD_FAILURE visible_to_users | boolean | | plain | | when visible_to_users=true, RAS events of this type will be returned in the response to csm_ras_event_query_allocation Indexes: "csm_ras_type_pkey" PRIMARY KEY, btree (msg_id) Triggers: tr_csm_ras_type_update AFTER INSERT OR DELETE OR UPDATE ON csm_ras_type FOR EACH ROW EXECUTE PROCEDURE fn_csm_ras_type_update() Has OIDs: nocsm_ras_type_audit¶
- Description
- This table contains historical descriptions and details for each of the possible RAS event types. See table below for details.
Table Overview Action On: Usage Size Key(s) Index
Referenced by table Constraint Fields Key csm_ras_event_action csm_ras_event_action_msg_id_seq_fkey msg_id_seq (FK) csm_ras_type_audit (DB table overview)¶
Table "public.csm_ras_type_audit" Column | Type | Modifiers | Storage | Stats target | Description ------------------+-----------------------------+-------------------------------------------------------------------------+----------+--------------+------------------------------------------------------------------------------------------------------------------------------------------ msg_id_seq | bigint | not null default nextval('csm_ras_type_audit_msg_id_seq_seq'::regclass) | plain | | a unique sequence number used to index the csm_ras_type_audit table operation | character(1) | not null | extended | | I/D/U indicates whether the change to the csm_ras_type table was an INSERT, DELETE, or UPDATE change_time | timestamp without time zone | not null | plain | | time_stamp indicating when this change occurred msg_id | text | not null | extended | | the identifier string for this RAS event. typically it consists of three parts separated by periods (system.component.id). severity | ras_event_severity | not null | plain | | severity of the RAS event. INFO/WARNING/FATAL message | text | | extended | | ras message to display to the user (pre-variable substitution) description | text | | extended | | description of the ras event control_action | text | | extended | | name of control action script to invoke for this event. threshold_count | integer | | plain | | number of times this event has to occur during the (threshold_period) before taking action on the RAS event. threshold_period | integer | | plain | | period in seconds over which to compare the number of event occurences to the threshold_count ). enabled | boolean | | plain | | events will be processed if enabled=true and suppressed if enabled=false set_state | compute_node_states | | plain | | setting the state according to the node, DISCOVERED, IN_SERVICE, ADMIN_RESERVED, MAINTENANCE, SOFT_FAILURE, OUT_OF_SERVICE, HARD_FAILURE visible_to_users | boolean | | plain | | when visible_to_users=true, RAS events of this type will be returned in the response to csm_ras_event_query_allocation Indexes: "csm_ras_type_audit_pkey" PRIMARY KEY, btree (msg_id_seq) Referenced by: TABLE "csm_ras_event_action" CONSTRAINT "csm_ras_event_action_msg_id_seq_fkey" FOREIGN KEY (msg_id_seq) REFERENCES csm_ras_type_audit(msg_id_seq) Has OIDs: nocsm_ras_event_action¶
- Description
- This table contains all RAS events. This table will populate an enormous amount of records due to continuous event cycle. A solution needs to be in place to accommodate the mass amount of data produced. See table below for details.
Table Overview Action On: Usage Size Key(s) Index csm_ras_event_action (DB table overview)¶
Table "public.csm_ras_event_action" Column | Type | Modifiers | Storage | Stats target | Description ----------------------+-----------------------------+-----------------------------------------------------------------------+----------+--------------+------------------------------------------------------------------------------------------------------------------------------------------------ rec_id | bigint | not null default nextval('csm_ras_event_action_rec_id_seq'::regclass) | plain | | unique identifier for this specific ras event msg_id | text | not null | extended | | type of ras event msg_id_seq | integer | not null | plain | | a unique sequence number used to index the csm_ras_type_audit table time_stamp | timestamp without time zone | not null | plain | | The time supplied by the caller of csm_ras_event_create. Used for correlating between events based on the local time of the event source. master_time_stamp | timestamp without time zone | not null | plain | | The time when the event is process by the CSM master daemon. Used for correlating node state changes with CSM master processing of RAS events. location_name | text | not null | extended | | this field can be a node name or location name count | integer | | plain | | how many times this event reoccurs message | text | | extended | | message text kvcsv | text | | extended | | event specific keys and values in a comma separated list raw_data | text | | extended | | event/s raw data archive_history_time | timestamp without time zone | | plain | | timestamp when the history data has been archived and sent to: BDS, archive file, and or other Indexes: "csm_ras_event_action_pkey" PRIMARY KEY, btree (rec_id) "ix_csm_ras_event_action_a" btree (msg_id) "ix_csm_ras_event_action_b" btree (time_stamp) "ix_csm_ras_event_action_c" btree (location_name) "ix_csm_ras_event_action_d" btree (time_stamp, msg_id) "ix_csm_ras_event_action_e" btree (time_stamp, location_name) "ix_csm_ras_event_action_f" btree (master_time_stamp) "ix_csm_ras_event_action_h" btree (archive_history_time) Foreign-key constraints: "csm_ras_event_action_msg_id_seq_fkey" FOREIGN KEY (msg_id_seq) REFERENCES csm_ras_type_audit(msg_id_seq) Has OIDs: noCSM diagnostic tables¶
csm_diag_run¶
- Description
- This table contains information about each of the diagnostic runs. See table below for details.
Table Overview Action On: Usage Size Key(s) Index Functions
Referenced by table Constraint Fields Key csm_diag_result csm_diag_result_run_id_fkey run_id (FK) csm_diag_run (DB table overview)¶
Table "public.csm_diag_run" Column | Type | Modifiers | Storage | Stats target | Description ---------------+-----------------------------+------------------------------------+----------+--------------+------------------------------------------------------------------------ run_id | bigint | not null | plain | | diagnostic/s run id allocation_id | bigint | | plain | | allocation that this diag_run is part of begin_time | timestamp without time zone | not null default now() | plain | | this is when the diagnostic run begins status | character(16) | not null default 'RUNNING'::bpchar | extended | | diagnostic/s status (RUNNING,COMPLETED,FAILED,CANCELED,COMPLETED_FAIL) inserted_ras | boolean | not null default false | plain | | inserted diagnostic ras events t/f log_dir | text | not null | extended | | location of diagnostic/s log files cmd_line | text | | extended | | how diagnostic program was invoked: program and arguments Indexes: "csm_diag_run_pkey" PRIMARY KEY, btree (run_id) Referenced by: TABLE "csm_diag_result" CONSTRAINT "csm_diag_result_run_id_fkey" FOREIGN KEY (run_id) REFERENCES csm_diag_run(run_id) Has OIDs: nocsm_diag_run_history¶
- Description
- This table contains historical information about each of the diagnostic runs. See table below for details.
Table Overview Action On: Usage Size Index csm_diag_run_history (DB table overview)¶
Table "public.csm_diag_run_history" Column | Type | Modifiers | Storage | Stats target | Description ----------------------+-----------------------------+-----------+----------+--------------+------------------------------------------------------------------------------------------------ history_time | timestamp without time zone | not null | plain | | timestamp when it enters the history table run_id | bigint | not null | plain | | diagnostic/s run id allocation_id | bigint | | plain | | allocation that this diag_run is part of begin_time | timestamp without time zone | not null | plain | | this is when the diagnostic run begins end_time | timestamp without time zone | | plain | | this is when the diagnostic run ends status | character(16) | not null | extended | | diagnostic/s status (RUNNING,COMPLETED,FAILED,CANCELED,COMPLETED_FAIL) inserted_ras | boolean | not null | plain | | inserted diagnostic ras events t/f log_dir | text | not null | extended | | location of diagnostic/s log files cmd_line | text | | extended | | how diagnostic program was invoked: program and arguments archive_history_time | timestamp without time zone | | plain | | timestamp when the history data has been archived and sent to: BDS, archive file, and or other Indexes: "ix_csm_diag_run_history_a" btree (history_time) "ix_csm_diag_run_history_b" btree (run_id) "ix_csm_diag_run_history_c" btree (allocation_id) "ix_csm_diag_run_history_e" btree (archive_history_time) Has OIDs: nocsm_diag_result¶
- Description
- This table contains the results of a specific instance of a diagnostic.
Table Overview Action On: Usage Size Key(s) Index Functions Triggers csm_diag_result (DB table overview)¶
Table "public.csm_diag_result" Column | Type | Modifiers | Storage | Stats target | Description ---------------+-----------------------------+---------------------------+----------+--------------+---------------------------------------------------------------------------------------- run_id | bigint | | plain | | diagnostic/s run id test_name | text | not null | extended | | the name of the specific testcase node_name | text | not null | extended | | identifies which node serial_number | text | | extended | | serial number of the field replaceable unit (fru) that this diagnostic was run against begin_time | timestamp without time zone | | plain | | the time when the task begins end_time | timestamp without time zone | default now() | plain | | the time when the task is complete status | character(16) | default 'unknown'::bpchar | extended | | test status after the diagnostic finishes (pass, fail, completed_fail) log_file | text | | extended | | location of diagnostic/s log file Indexes: "ix_csm_diag_result_a" btree (run_id, test_name, node_name) Foreign-key constraints: "csm_diag_result_run_id_fkey" FOREIGN KEY (run_id) REFERENCES csm_diag_run(run_id) Triggers: tr_csm_diag_result_history_dump BEFORE DELETE ON csm_diag_result FOR EACH ROW EXECUTE PROCEDURE fn_csm_diag_result_history_dump() Has OIDs: nocsm_diag_result_history¶
- Description
- This table contains historical results of a specific instance of a diagnostic.
Table Overview Action On: Usage Size Index csm_diag_result_history (DB table overview)¶
Table "public.csm_diag_result_history" Column | Type | Modifiers | Storage | Stats target | Description ----------------------+-----------------------------+---------------------------+----------+--------------+------------------------------------------------------------------------------------------------ history_time | timestamp without time zone | not null | plain | | timestamp when it enters the history table run_id | bigint | | plain | | diagnostic/s run id test_name | text | not null | extended | | the name of the specific testcase node_name | text | not null | extended | | identifies which node serial_number | text | | extended | | serial number of the field replaceable unit (fru) that this diagnostic was run against begin_time | timestamp without time zone | | plain | | the time when the task begins end_time | timestamp without time zone | default now() | plain | | the time when the task is complete status | character(16) | default 'unknown'::bpchar | extended | | test status after the diagnostic finishes (pass, fail, completed_fail) log_file | text | | extended | | location of diagnostic/s log file archive_history_time | timestamp without time zone | | plain | | timestamp when the history data has been archived and sent to: BDS, archive file, and or other Indexes: "ix_csm_diag_result_history_a" btree (history_time) "ix_csm_diag_result_history_b" btree (run_id) "ix_csm_diag_result_history_d" btree (archive_history_time) Has OIDs: noSSD partition and SSD logical volume tables¶
csm_lv¶
- Description
- This table contains information about the logical volumes that are created within the compute nodes.
Table Overview Action On: Usage Size Key(s) Index Functions Triggers csm_lv (DB table overview)¶
Table "public.csm_lv" Column | Type | Modifiers | Storage | Stats target | Description ---------------------+-----------------------------+-----------+----------+--------------+----------------------------------------------------- logical_volume_name | text | not null | extended | | unique identifier for this ssd partition node_name | text | not null | extended | | node a part of this group allocation_id | bigint | not null | plain | | unique identifier for this allocation vg_name | text | not null | extended | | volume group name state | character(1) | not null | extended | | state: (c)reated, (m)ounted, (s)hrinking, (r)emoved current_size | bigint | not null | plain | | current size (in bytes) max_size | bigint | not null | plain | | max size (in bytes) at runtime begin_time | timestamp without time zone | not null | plain | | when the partitioning begins updated_time | timestamp without time zone | | plain | | when it was last updated file_system_mount | text | | extended | | identifies the file system and mount point file_system_type | text | | extended | | identifies the file system and its partition Indexes: "csm_lv_pkey" PRIMARY KEY, btree (logical_volume_name, node_name) "ix_csm_lv_a" btree (logical_volume_name) Foreign-key constraints: "csm_lv_allocation_id_fkey" FOREIGN KEY (allocation_id, node_name) REFERENCES csm_allocation_node(allocation_id, node_name) "csm_lv_node_name_fkey" FOREIGN KEY (node_name, vg_name) REFERENCES csm_vg(node_name, vg_name) Triggers: tr_csm_lv_update_history_dump BEFORE UPDATE OF state, current_size, updated_time ON csm_lv FOR EACH ROW EXECUTE PROCEDURE fn_csm_lv_update_history_dump() Has OIDs: nocsm_lv_history¶
- Description
- This table contains historical information associated with previously active logical volumes.
Table Overview Action On: Usage Size Index csm_lv_history (DB table overview)¶
Table "public.csm_lv_history" Column | Type | Modifiers | Storage | Stats target | Description ----------------------+-----------------------------+-----------+----------+--------------+------------------------------------------------------------------------------------------------ history_time | timestamp without time zone | not null | plain | | this is when the lv enters the history table logical_volume_name | text | not null | extended | | unique identifier for this ssd partition node_name | text | not null | extended | | node a part of this group allocation_id | bigint | | plain | | unique identifier for this allocation vg_name | text | | extended | | volume group name state | character(1) | not null | extended | | state: (c)reated, (m)ounted, (s)hrinking, (r)emoved current_size | bigint | not null | plain | | current size (in bytes) max_size | bigint | not null | plain | | max size (in bytes) at runtime begin_time | timestamp without time zone | not null | plain | | when the partitioning begins updated_time | timestamp without time zone | | plain | | when it was last updated end_time | timestamp without time zone | | plain | | when the partitioning stage ends file_system_mount | text | | extended | | identifies the file system and mount point file_system_type | text | | extended | | identifies the file system and its partition num_bytes_read | bigint | | plain | | number of bytes read during the life of this partition num_bytes_written | bigint | | plain | | number of bytes written during the life of this partition operation | character(1) | | extended | | operation of transaction (I - INSERT), (U - UPDATE), (D - DELETE) archive_history_time | timestamp without time zone | | plain | | timestamp when the history data has been archived and sent to: BDS, archive file, and or other num_reads | bigint | | plain | | number of read during the life of this partition num_writes | bigint | | plain | | number of writes during the life of this partition Indexes: "ix_csm_lv_history_a" btree (history_time) "ix_csm_lv_history_b" btree (logical_volume_name) "ix_csm_lv_history_d" btree (archive_history_time) Has OIDs: nocsm_lv_update_history¶
- Description
- This table contains historical information associated with lv updates.
Table Overview Action On: Usage Size Index csm_lv_update_history (DB table overview)¶
Table "public.csm_lv_update_history" Column | Type | Modifiers | Storage | Stats target | Description ----------------------+-----------------------------+-----------+----------+--------------+------------------------------------------------------------------------------------------------ history_time | timestamp without time zone | not null | plain | | this is when the lv update enters the history table logical_volume_name | text | not null | extended | | unique identifier for this ssd partition allocation_id | bigint | not null | plain | | unique identifier for this allocation state | character(1) | not null | extended | | state: (c)reate, (m)ounted, (s)hrinking, (r)emoved current_size | bigint | not null | plain | | current size (in bytes) updated_time | timestamp without time zone | | plain | | when it was last updated operation | character(1) | | extended | | operation of transaction (I - INSERT), (U - UPDATE), (D - DELETE) archive_history_time | timestamp without time zone | | plain | | timestamp when the history data has been archived and sent to: BDS, archive file, and or other Indexes: "ix_csm_lv_update_history_a" btree (history_time) "ix_csm_lv_update_history_b" btree (logical_volume_name) "ix_csm_lv_update_history_d" btree (archive_history_time) Has OIDs: nocsm_vg_ssd¶
- Description
- This table contains information that references both the SSD logical volume tables.
Table Overview Action On: Usage Size Key(s) Index Functions Triggers csm_vg_ssd (DB table overview)¶
Table "public.csm_vg_ssd" Column | Type | Modifiers | Storage | Stats target | Description ----------------+--------+-----------+----------+--------------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- vg_name | text | not null | extended | | unique identifier for this ssd partition node_name | text | not null | extended | | identifies which node serial_number | text | not null | extended | | serial number for the ssd ssd_allocation | bigint | not null | plain | | the amount of space (in bytes) that this ssd contributes to the volume group. Can not be less than zero. The total sum of these fields should equal total_size of the this vg in the vg table Indexes: "uk_csm_vg_ssd_a" UNIQUE, btree (vg_name, node_name, serial_number) Foreign-key constraints: "csm_vg_ssd_serial_number_fkey" FOREIGN KEY (serial_number, node_name) REFERENCES csm_ssd(serial_number, node_name) "csm_vg_ssd_vg_name_fkey" FOREIGN KEY (vg_name, node_name) REFERENCES csm_vg(vg_name, node_name) Triggers: tr_csm_vg_ssd_history_dump BEFORE INSERT OR DELETE OR UPDATE ON csm_vg_ssd FOR EACH ROW EXECUTE PROCEDURE fn_csm_vg_ssd_history_dump() Has OIDs: nocsm_vg_ssd_history¶
- Description
- This table contains historical information associated with SSD and logical volume tables.
Table Overview Action On: Usage Size Index csm_vg_ssd_history (DB table overview)¶
Table "public.csm_vg_ssd_history" Column | Type | Modifiers | Storage | Stats target | Description ----------------------+-----------------------------+-----------+----------+--------------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- history_time | timestamp without time zone | not null | plain | | time when enters into the history table vg_name | text | not null | extended | | unique identifier for this ssd partition node_name | text | not null | extended | | identifies which node serial_number | text | not null | extended | | serial number for the ssd ssd_allocation | bigint | not null | plain | | the amount of space (in bytes) that this ssd contributes to the volume group. Can not be less than zero. The total sum of these fields should equal total_size of the this vg in the vg table operation | character(1) | not null | extended | | operation of transaction (I - INSERT), (U - UPDATE), (D - DELETE) archive_history_time | timestamp without time zone | | plain | | timestamp when the history data has been archived and sent to: BDS, archive file, and or other Indexes: "ix_csm_vg_ssd_history_a" btree (history_time) "ix_csm_vg_ssd_history_b" btree (vg_name, node_name) "ix_csm_vg_ssd_history_d" btree (archive_history_time) Has OIDs: nocsm_vg¶
- Description
- This table contains information that references both the SSD logical volume tables.
Table Overview Action On: Usage Size Key(s) Index Functions Triggers
Referenced by table Constraint Fields Key csm_lv csm_lv_node_name_fkey node_name, vg_name (FK) csm_vg (DB table overview)¶
Table "public.csm_vg" Column | Type | Modifiers | Storage | Stats target | Description ----------------+-----------------------------+-----------+----------+--------------+---------------------------------------------------------------------- vg_name | text | not null | extended | | unique identifier for this ssd partition node_name | text | not null | extended | | identifies which node total_size | bigint | not null | plain | | volume group size. measured in bytes available_size | bigint | not null | plain | | remaining bytes available out of total size. scheduler | boolean | not null | plain | | tells CSM whether or not this is the volume group for the scheduler. update_time | timestamp without time zone | | plain | | timestamp when the vg was updated Indexes: "csm_vg_pkey" PRIMARY KEY, btree (vg_name, node_name) Check constraints: "csm_available_size_should_be_less_than_total_size" CHECK (available_size <= total_size) Referenced by: TABLE "csm_lv" CONSTRAINT "csm_lv_node_name_fkey" FOREIGN KEY (node_name, vg_name) REFERENCES csm_vg(node_name, vg_name) TABLE "csm_vg_ssd" CONSTRAINT "csm_vg_ssd_vg_name_fkey" FOREIGN KEY (vg_name, node_name) REFERENCES csm_vg(vg_name, node_name) Triggers: tr_csm_vg_history_dump BEFORE INSERT OR DELETE OR UPDATE ON csm_vg FOR EACH ROW EXECUTE PROCEDURE fn_csm_vg_history_dump() Has OIDs: nocsm_vg_history¶
- Description
- This table contains historical information associated with SSD and logical volume tables.
Table Overview Action On: Usage Size Index csm_vg_history (DB table overview)¶
Table "public.csm_vg_history" Column | Type | Modifiers | Storage | Stats target | Description ----------------------+-----------------------------+-----------+----------+--------------+------------------------------------------------------------------------------------------------ history_time | timestamp without time zone | not null | plain | | time when enters into the history table vg_name | text | not null | extended | | unique identifier for this ssd partition node_name | text | not null | extended | | identifies which node total_size | bigint | not null | plain | | volume group size. measured in bytes available_size | bigint | not null | plain | | remaining bytes available out of total size. scheduler | boolean | not null | plain | | tells CSM whether or not this is the volume group for the scheduler. update_time | timestamp without time zone | | plain | | timestamp when the vg was updated operation | character(1) | not null | extended | | operation of transaction (I - INSERT), (U - UPDATE), (D - DELETE) archive_history_time | timestamp without time zone | | plain | | timestamp when the history data has been archived and sent to: BDS, archive file, and or other Indexes: "ix_csm_vg_history_a" btree (history_time) "ix_csm_vg_history_b" btree (vg_name, node_name) "ix_csm_vg_history_d" btree (archive_history_time) Has OIDs: noSwitch & ib cable tables¶
csm_switch¶
- Description
- This table contain information about the switch and it attributes. See table below for details.
Table Overview Action On: Usage Size Key(s) Index Functions Triggers
Referenced by table Constraint Fields Key csm_switch_inventory csm_switch_inventory_host_system_guid_fkey host_system_guid (FK) csm_switch (DB table overview)¶
Table "public.csm_switch" Column | Type | Modifiers | Storage | Stats target | Description -------------------------+-----------------------------+-----------+----------+--------------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- switch_name | text | not null | extended | | switch name: Identification of the system For hosts, it is caguid, For 1U switch, it is switchguid, For modular switches, is it sysimgguid serial_number | text | | extended | | identifies the switch this information is for discovery_time | timestamp without time zone | | plain | | time the switch collected at inventory time collection_time | timestamp without time zone | | plain | | time the switch was initially connected comment | text | | extended | | a comment can be generated for this field description | text | | extended | | description of system – system type of this systems (More options: SHArP, MSX1710 , CS7520) fw_version | text | | extended | | firmware version of the Switch or HCA gu_id | text | | extended | | Node guid of the system. In case of HCA, it is the caguid. In case of Switch, it is the switchguid has_ufm_agent | boolean | | plain | | indicate if system (Switch or Host) is running a UFM Agent hw_version | text | | extended | | hardware version related to the switch ip | text | | extended | | ip address of the system (Switch or Host) (0.0.0.0 in case ip address not available) model | text | | extended | | system model – in case of switch, it is the switch model, For hosts – Computer num_modules | integer | | plain | | number of modules attached to this switch. This is the number of expected records in the csm_switch inventory table associated with this switch name. physical_frame_location | text | | extended | | where the switch is located physical_u_location | text | | extended | | physical u location (position in the frame) where the switch is located ps_id | text | | extended | | PSID (Parameter-Set IDentification) is a 16-ascii character string embedded in the firmware image which provides a unique identification for the configuration of the firmware. role | text | | extended | | Type/Role of system in the current fabric topology: Tor / Core / Endpoint (host). (Optional Values: core, tor, endpoint) server_operation_mode | text | | extended | | Operation mode of system. (Optional Values: Stand_Alone, HA_Active, HA_StandBy, Not_UFM_Server, Router, Gateway, Switch) sm_mode | text | | extended | | Indicate if SM is running on that system. (Optional Values: no SM, activeSM, hasSM) state | text | | extended | | runtime state of the system. (Optional Values: active, rebooting, down, error (failed to reboot)) sw_version | text | | extended | | software version of the system – full MLNX_OS version. Relevant only for MLNX-OS systems (Not available for Hosts) system_guid | text | | extended | | system image guid for that system system_name | text | | extended | | system name as it appear on the system node description total_alarms | integer | | plain | | total number of alarms which are currently exist on the system type | text | | extended | | type of system. (Optional Values: switch, host, gateway) vendor | text | | extended | | system vendor Indexes: "csm_switch_pkey" PRIMARY KEY, btree (switch_name) "uk_csm_switch_gu_id_a" UNIQUE CONSTRAINT, btree (gu_id) Referenced by: TABLE "csm_switch_inventory" CONSTRAINT "csm_switch_inventory_host_system_guid_fkey" FOREIGN KEY (host_system_guid) REFERENCES csm_switch(gu_id) Triggers: tr_csm_switch_history_dump BEFORE INSERT OR DELETE OR UPDATE ON csm_switch FOR EACH ROW EXECUTE PROCEDURE fn_csm_switch_history_dump() Has OIDs: nocsm_switch_history¶
- Description
- This table contains historical information associated with individual switches.
Table Overview Action On: Usage Size Index csm_switch_history (DB table overview)¶
Table "public.csm_switch_history" Column | Type | Modifiers | Storage | Stats target | Description -------------------------+-----------------------------+-----------+----------+--------------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- history_time | timestamp without time zone | not null | plain | | the time when the switch enters the history table switch_name | text | not null | extended | | switch name: Identification of the system For hosts, it is caguid, For 1U switch, it is switchguid, For modular switches, is it sysimgguid serial_number | text | | extended | | identifies the switch this information is for discovery_time | timestamp without time zone | | plain | | time the switch collected at inventory time collection_time | timestamp without time zone | | plain | | time the switch was initially connected comment | text | | extended | | a comment can be generated for this field description | text | | extended | | Description of system – system type of this systems (More options: SHArP, MSX1710 , CS7520) fw_version | text | | extended | | firmware version of the Switch or HCA gu_id | text | | extended | | Node guid of the system. In case of HCA, it is the caguid. In case of Switch, it is the switchguid has_ufm_agent | boolean | | plain | | Indicate if system (Switch or Host) is running a UFM Agent hw_version | text | | extended | | hardware version related to the switch ip | text | | extended | | ip address of the system (Switch or Host) (0.0.0.0 in case ip address not available) model | text | | extended | | System model – in case of switch, it is the switch model, For hosts – Computer num_modules | integer | | plain | | number of modules attached to this switch. This is the number of expected records in the csm_switch inventory table associated with this switch name. physical_frame_location | text | | extended | | where the switch is located physical_u_location | text | | extended | | physical u location (position in the frame) where the switch is located ps_id | text | | extended | | PSID (Parameter-Set IDentification) is a 16-ascii character string embedded in the firmware image which provides a unique identification for the configuration of the firmware. role | text | | extended | | Type/Role of system in the current fabric topology: Tor / Core / Endpoint (host). (Optional Values: core, tor, endpoint) server_operation_mode | text | | extended | | Operation mode of system. (Optional Values: Stand_Alone, HA_Active, HA_StandBy, Not_UFM_Server, Router, Gateway, Switch) sm_mode | text | | extended | | Indicate if SM is running on that system. (Optional Values: no SM, activeSM, hasSM) state | text | | extended | | runtime state of the system. (Optional Values: active, rebooting, down, error (failed to reboot)) sw_version | text | | extended | | software version of the system – full MLNX_OS version. Relevant only for MLNX-OS systems (Not available for Hosts) system_guid | text | | extended | | system image guid for that system system_name | text | | extended | | system name as it appear on the system node description total_alarms | integer | | plain | | total number of alarms which are currently exist on the system type | text | | extended | | type of system. (Optional Values: switch, host, gateway) vendor | text | | extended | | system_vendor operation | character(1) | not null | extended | | operation of transaction (I - INSERT), (U - UPDATE), (D - DELETE) archive_history_time | timestamp without time zone | | plain | | timestamp when the history data has been archived and sent to: BDS, archive file, and or other Indexes: "ix_csm_switch_history_a" btree (history_time) "ix_csm_switch_history_b" btree (switch_name, history_time) "ix_csm_switch_history_d" btree (archive_history_time) Has OIDs: nocsm_ib_cable¶
- Description
- This table contains information about the InfiniBand cables. See table below for details.
Table Overview Action On: Usage Size Key(s) Index Functions Triggers csm_ib_cable (DB table overview)¶
Table "public.csm_ib_cable" Column | Type | Modifiers | Storage | Stats target | Description -----------------+-----------------------------+-----------+----------+--------------+------------------------------------------------------------------------------------------------------------ serial_number | text | not null | extended | | identifies the cables serial number discovery_time | timestamp without time zone | | plain | | First time the ib cable was found in the system collection_time | timestamp without time zone | | plain | | Last time the ib cable inventory was collected comment | text | | extended | | comment can be generated for this field guid_s1 | text | | extended | | guid: side 1 of the cable guid_s2 | text | | extended | | guid: side 2 of the cable identifier | text | | extended | | cable identifier (example value: QSFP+) length | text | | extended | | the length of the cable name | text | | extended | | name (Id) of link object in UFM. Based on link sorce and destination. part_number | text | | extended | | part number of this particular ib cable port_s1 | text | | extended | | port: side 1 of the cable port_s2 | text | | extended | | port: side 2 of the cable revision | text | | extended | | hardware revision associated with this ib cable severity | text | | extended | | severity associated with this ib cable (severity of link according to highest severity of related events) type | text | | extended | | field from UFM (technology ) - the specific type of cable used (example used : copper cable - unequalized) width | text | | extended | | the width of the cable - physical state of IB port (Optional Values: IB_1x ,IB_4x, IB_8x, IB_12x) Indexes: "csm_ib_cable_pkey" PRIMARY KEY, btree (serial_number) Triggers: tr_csm_ib_cable_history_dump BEFORE INSERT OR DELETE OR UPDATE ON csm_ib_cable FOR EACH ROW EXECUTE PROCEDURE fn_csm_ib_cable_history_dump() Has OIDs: nocsm_ib_cable_history¶
- Description
- This table contains historical information about the InfiniBand cables.
Table Overview Action On: Usage Size Index csm_ib_cable_history (DB table overview)¶
Table "public.csm_ib_cable_history" Column | Type | Modifiers | Storage | Stats target | Description ----------------------+-----------------------------+-----------+----------+--------------+------------------------------------------------------------------------------------------------------------ history_time | timestamp without time zone | not null | plain | | the time when the cable enters the history table serial_number | text | not null | extended | | identifies the cables serial number discovery_time | timestamp without time zone | | plain | | first time the ib cable was found in the system collection_time | timestamp without time zone | | plain | | comment can be generated for this field comment | text | | extended | | comment can be generated for this field guid_s1 | text | | extended | | guid: side 1 of the cable guid_s2 | text | | extended | | guid: side 2 of the cable identifier | text | | extended | | cable identifier (example value: QSFP+) length | text | | extended | | the length of the cable name | text | | extended | | name (Id) of link object in UFM. Based on link sorce and destination. part_number | text | | extended | | part number of this particular ib cable port_s1 | text | | extended | | port: side 1 of the cable port_s2 | text | | extended | | port: side 2 of the cable revision | text | | extended | | hardware revision associated with this ib cable severity | text | | extended | | severity associated with this ib cable (severity of link according to highest severity of related events) type | text | | extended | | field from UFM (technology ) - the specific type of cable used (example used : copper cable - unequalized) width | text | | extended | | the width of the cable - physical state of IB port (Optional Values: IB_1x ,IB_4x, IB_8x, IB_12x) operation | character(1) | not null | extended | | operation of transaction (I - INSERT), (U - UPDATE), (D - DELETE) archive_history_time | timestamp without time zone | | plain | | timestamp when the history data has been archived and sent to: BDS, archive file, and or other Indexes: "ix_csm_ib_cable_history_a" btree (history_time) "ix_csm_ib_cable_history_b" btree (serial_number) "ix_csm_ib_cable_history_d" btree (archive_history_time) Has OIDs: nocsm_switch_inventory¶
- Description
- This table contains information about the switch inventory. See table below for details.
Table Overview Action On: Usage Size Key(s) Index Functions Triggers csm_switch_inventory (DB table overview)¶
Table "public.csm_switch_inventory" Column | Type | Modifiers | Storage | Stats target | Description ------------------+-----------------------------+-----------+----------+--------------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- name | text | not null | extended | | name (identifier) of this module in UFM. host_system_guid | text | not null | extended | | the system image guid of the hosting system. discovery_time | timestamp without time zone | | plain | | first time the module was found in the system collection_time | timestamp without time zone | | plain | | last time the module inventory was collected comment | text | | extended | | system administrator comment about this module description | text | | extended | | description type of module - can be the module type: system, FAN, MGMT,PS or the type of module in case of line / spine modules: SIB7510(Barracud line), SIB7520(Barracuda spine) device_name | text | | extended | | name of device containing this module. device_type | text | | extended | | type of device module belongs to. hw_version | text | | extended | | hardware version related to the switch max_ib_ports | integer | | plain | | maximum number of external ports of this module. module_index | integer | | plain | | index of module. Each module type has separate index: FAN1,FAN2,FAN3…PS1,PS2 number_of_chips | integer | | plain | | number of chips which are contained in this module. (relevant only for line / spine modules, for all other modules number_of_chips=0) path | text | | extended | | full path of module object. Path format: site-name (number of devices) / device type: device-name / module description module index. serial_number | text | | extended | | serial_number of the module. severity | text | | extended | | severity of the module according to the highest severity of related events. values: Info, Warning, Minor, Critical status | text | | extended | | current module status. valid values: ok, fault type | text | | extented | | The category of this piece of hardware inventory. For example: "FAN", "PS", "SYSTEM", or "MGMT". fw_version | text | | extented | | The firmware version on this piece of inventory. Indexes: "csm_switch_inventory_pkey" PRIMARY KEY, btree (name) Foreign-key constraints: "csm_switch_inventory_host_system_guid_fkey" FOREIGN KEY (host_system_guid) REFERENCES csm_switch(gu_id) Triggers: tr_csm_switch_inventory_history_dump BEFORE INSERT OR DELETE OR UPDATE ON csm_switch_inventory FOR EACH ROW EXECUTE PROCEDURE fn_csm_switch_inventory_history_dump() Has OIDs: nocsm_switch_inventory_history¶
- Description
- This table contains historical information about the switch inventory.
Table Overview Action On: Usage Size Index csm_switch_inventory_history (DB table overview)¶
Table "public.csm_switch_inventory_history" Column | Type | Modifiers | Storage | Stats target | Description ----------------------+-----------------------------+-----------+----------+--------------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- history_time | timestamp without time zone | not null | plain | | the time when the inventory record enters the history table name | text | not null | extended | | name (identifier) of this module in UFM. host_system_guid | text | not null | extended | | the system image guid of the hosting system. discovery_time | timestamp without time zone | | plain | | first time the module was found in the system collection_time | timestamp without time zone | | plain | | last time the module inventory was collected comment | text | | extended | | system administrator comment about this module description | text | | extended | | description type of module - can be the module type: system, FAN, MGMT,PS or the type of module in case of line / spine modules: SIB7510(Barracud line), SIB7520(Barracuda spine) device_name | text | | extended | | name of device containing this module. device_type | text | | extended | | type of device module belongs to. hw_version | text | | extended | | hardware version related to the switch max_ib_ports | integer | | plain | | maximum number of external ports of this module. module_index | integer | | plain | | index of module. Each module type has separate index: FAN1,FAN2,FAN3…PS1,PS2 number_of_chips | integer | | plain | | number of chips which are contained in this module. (relevant only for line / spine modules, for all other modules number_of_chips=0) path | text | | extended | | full path of module object. Path format: site-name (number of devices) / device type: device-name / module description module index. serial_number | text | | extended | | serial_number of the module. severity | text | | extended | | severity of the module according to the highest severity of related events. values: Info, Warning, Minor, Critical status | text | | extended | | current module status. valid values: ok, fault operation | character(1) | not null | extended | | operation of transaction (I - INSERT), (U - UPDATE), (D - DELETE) archive_history_time | timestamp without time zone | | plain | | timestamp when the history data has been archived and sent to: BDS, archive file, and or other type | text | | extented | | The category of this piece of hardware inventory. For example: "FAN", "PS", "SYSTEM", or "MGMT". fw_version | text | | extented | | The firmware version on this piece of inventory. Indexes: "ix_csm_switch_inventory_history_a" btree (history_time) "ix_csm_switch_inventory_history_b" btree (name) "ix_csm_switch_inventory_history_d" btree (archive_history_time) Has OIDs: noCSM configuration tables¶
csm_config¶
- Description
- This table contains information about the CSM configuration.
Table Overview Action On: Usage Size Key(s) Index Functions Triggers csm_config (DB table overview)¶
Table "public.csm_config" Column | Type | Modifiers | Storage | Stats target | Description ------------------------+-----------------------------+--------------------------------------------------------------------+----------+--------------+----------------------------------------------------------------------- csm_config_id | bigint | not null default nextval('csm_config_csm_config_id_seq'::regclass) | plain | | the configuration identification local_socket | text | | extended | | socket to use to local csm daemon mqtt_broker | text | | extended | | ip: port log_level | text[] | | extended | | db#, daemon.compute, daemon.aggragator, daemon.master, daemon.utility buckets | text[] | | extended | | list of items to execute in buckets jitter_window_interval | integer | | plain | | jitter interval for compute agent (how often to wake up) jitter_window_duration | integer | | plain | | jitter duration for compute agent (duration of the window) path_certificate | text | | extended | | location of certificates for authentication path_log | text | | extended | | path where the daemon will log create_time | timestamp without time zone | | plain | | when these logs were created Indexes: "csm_config_pkey" PRIMARY KEY, btree (csm_config_id) Triggers: tr_csm_config_history_dump BEFORE DELETE OR UPDATE ON csm_config FOR EACH ROW EXECUTE PROCEDURE fn_csm_config_history_dump() Has OIDs: nocsm_config_history¶
- Description
- This table contains historical information about the CSM configuration.
Table Overview Action On: Usage Size Index csm_config_history (DB table overview)¶
Table "public.csm_config_history" Column | Type | Modifiers | Storage | Stats target | Description ------------------------+-----------------------------+-----------+----------+--------------+------------------------------------------------------------------------------------------------ history_time | timestamp without time zone | not null | plain | | the time when the configuration enters the history table csm_config_id | bigint | | plain | | the configuration identification local_socket | text | | extended | | socket to use to local csm daemon mqtt_broker | text | | extended | | ip: port log_level | text[] | | extended | | db#, daemon.compute, daemon.aggragator, daemon.master, daemon.utility buckets | text[] | | extended | | list of items to execute in buckets jitter_window_interval | integer | | plain | | jitter interval for compute agent (how often to wake up) jitter_window_duration | integer | | plain | | jitter duration for compute agent (duration of the window) path_certificate | text | | extended | | location of certificates for authentication path_log | text | | extended | | path where the daemon will log create_time | timestamp without time zone | | plain | | when these logs were created archive_history_time | timestamp without time zone | | plain | | timestamp when the history data has been archived and sent to: BDS, archive file, and or other Indexes: "ix_csm_config_history_a" btree (history_time) "ix_csm_config_history_b" btree (csm_config_id) "ix_csm_config_history_d" btree (archive_history_time) Has OIDs: nocsm_config_bucket¶
- Description
- This table is the list of items that will placed in the bucket. See table below for details.
Table Overview Action On: Usage Size Index csm_config_bucket (DB table overview)¶
Table "public.csm_config_bucket" Column | Type | Modifiers | Storage | Stats target | Description --------------------+-----------------------------+-----------+----------+--------------+------------------------------------------ bucket_id | integer | | plain | | this is the identification of the bucket item_list | bigint | | plain | | the item list within in the bucket execution_interval | text | | extended | | execution interval (the counter) time_stamp | timestamp without time zone | | plain | | time when the process takes place Indexes: "ix_csm_config_bucket_a" btree (bucket_id, item_list, time_stamp) Has OIDs: noCSM DB schema version tables¶
csm_db_schema_version¶
- Description
- This is the current database schema version when loaded.
Table Overview Action On: Usage Size Key(s) Index Functions Triggers csm_db_schema_version (DB table overview)¶
Table "public.csm_db_schema_version" Column | Type | Modifiers | Storage | Stats target | Description -------------+-----------------------------+---------------+----------+--------------+--------------------------------------------- version | text | not null | extended | | this is the current database schema version create_time | timestamp without time zone | default now() | plain | | time when the db was created comment | text | | extended | | comment Indexes: "csm_db_schema_version_pkey" PRIMARY KEY, btree (version) "ix_csm_db_schema_version_a" btree (version, create_time) Triggers: tr_csm_db_schema_version_history_dump BEFORE DELETE OR UPDATE ON csm_db_schema_version FOR EACH ROW EXECUTE PROCEDURE fn_csm_db_schema_version_history_dump() Has OIDs: nocsm_db_schema_version_history¶
- Description
- This is the historical database schema version (if changes have been made)
Table Overview Action On: Usage Size Index csm_db_schema_version_history (DB table overview)¶
Table "public.csm_db_schema_version_history" Column | Type | Modifiers | Storage | Stats target | Description ----------------------+-----------------------------+-----------+----------+--------------+------------------------------------------------------------------------------------------------ history_time | timestamp without time zone | not null | plain | | the time when the schema version enters the history table version | text | | extended | | this is the current database schema version create_time | timestamp without time zone | | plain | | time when the db was created comment | text | | extended | | comment archive_history_time | timestamp without time zone | | plain | | timestamp when the history data has been archived and sent to: BDS, archive file, and or other Indexes: "ix_csm_db_schema_version_history_a" btree (history_time) "ix_csm_db_schema_version_history_b" btree (version) "ix_csm_db_schema_version_history_d" btree (archive_history_time) Has OIDs: noPK, FK, UK keys and Index Charts¶
Primary Keys (default Indexes)¶
Index Name Table Name Index on Column Names csm_allocation_pkey csm_allocation pkey index on allocation_id csm_config_pkey csm_config pkey index on csm_config_id csm_db_schema_version_pkey csm_db_schema_version pkey index on version csm_diag_run_pkey csm_diag_run pkey index on run_id csm_dimm_pkey csm_dimm pkey index on node_name, serial_number csm_gpu_pkey csm_gpu pkey index on node_name, gpu_id csm_hca_pkey csm_hca pkey index on serial_number, node_name csm_ib_cable_pkey csm_ib_cable pkey index on serial_number csm_lv_pkey csm_lv pkey index on node_name, logical_volume_name csm_node_pkey csm_node pkey index on node_name csm_processor_socket_pkey csm_processor_socket pkey index on serial_number, node_name csm_ras_event_action_pkey csm_ras_event_action pkey index on rec_id csm_ras_type_pkey csm_ras_type pkey index on msg_id csm_ras_type_audit_pkey csm_ras_type_audit pkey index on msg_id_seq csm_ssd_pkey csm_ssd pkey index on node_name, serial_number csm_step_pkey csm_step pkey index on step_id, allocation_id csm_switch_pkey csm_switch pkey index on switch_name csm_switch_inventory_pkey csm_switch_inventory pkey index on name csm_vg_pkey csm_vg pkey index on vg_name, node_name Foreign Keys¶
Index Name From Table From Cols To Table To Cols csm_allocation_node_allocation_id_fkey csm_allocation_node allocation_id csm_allocation allocation_id csm_allocation_node_node_name_fkey csm_allocation_node node_name csm_node node_name csm_diag_result_run_id_fkey csm_diag_result run_id csm_diag_run run_id csm_dimm_node_name_fkey csm_dimm node_name csm_node node_name csm_gpu_node_name_fkey csm_gpu node_name csm_node node_name csm_hca_node_name_fkey csm_hca node_name csm_node node_name csm_lv_allocation_id_fkey csm_lv allocation_id, node_name csm_allocation_node allocation_id, node_name csm_lv_node_name_fkey csm_lv node_name, vg_name csm_vg node_name, vg_name csm_processor_socket_node_name_fkey csm_processor_socket node_name csm_node node_name csm_ras_event_action_msg_id_seq_fkey csm_ras_event_action msg_id_seq csm_ras_type_audit msg_id_seq csm_ssd_node_name_fkey csm_ssd node_name csm_node node_name csm_step_allocation_id_fkey csm_step allocation_id csm_allocation allocation_id csm_step_node_allocation_id_fkey csm_step_node allocation_id, node_name csm_allocation_node allocation_id, node_name csm_step_node_step_id_fkey csm_step_node step_id, allocation_id csm_step step_id, allocation_id csm_switch_inventory_host_system_guid_fkey csm_switch_inventory host_system_guid csm_switch gu_id csm_vg_ssd_serial_number_fkey csm_vg_ssd serial_number, node_name csm_ssd serial_number, node_name csm_vg_ssd_vg_name_fkey csm_vg_ssd vg_name, node_name csm_vg vg_name, node_name Indexes¶
Index Name Table Name Index on Column Names ix_csm_allocation_history_a csm_allocation_history index on history_time ix_csm_allocation_history_b csm_allocation_history index on allocation_id ix_csm_allocation_history_d csm_allocation_history index on archive_history_time ix_csm_allocation_node_a csm_allocation_node index on allocation_id ix_csm_allocation_node_history_a csm_allocation_node_history index on history_time ix_csm_allocation_node_history_b csm_allocation_node_history index on allocation_id ix_csm_allocation_node_history_d csm_allocation_node_history index on archive_history_time ix_csm_allocation_state_history_a csm_allocation_state_history index on history_time ix_csm_allocation_state_history_b csm_allocation_state_history index on allocation_id ix_csm_allocation_state_history_d csm_allocation_state_history index on archive_history_time ix_csm_config_bucket_a csm_config_bucket index on time_stamp, bucket_id, item_list ix_csm_config_history_a csm_config_history index on history_time ix_csm_config_history_b csm_config_history index on csm_config_id ix_csm_config_history_d csm_config_history index on archive_history_time ix_csm_db_schema_version_a csm_db_schema_version index on create_time, version ix_csm_db_schema_version_history_a csm_db_schema_version_history index on history_time ix_csm_db_schema_version_history_b csm_db_schema_version_history index on version ix_csm_db_schema_version_history_d csm_db_schema_version_history index on archive_history_time ix_csm_diag_result_a csm_diag_result index on node_name, test_name, run_id ix_csm_diag_result_history_a csm_diag_result_history index on history_time ix_csm_diag_result_history_b csm_diag_result_history index on run_id ix_csm_diag_result_history_d csm_diag_result_history index on archive_history_time ix_csm_diag_run_history_a csm_diag_run_history index on history_time ix_csm_diag_run_history_b csm_diag_run_history index on run_id ix_csm_diag_run_history_c csm_diag_run_history index on allocation_id ix_csm_diag_run_history_e csm_diag_run_history index on archive_history_time ix_csm_dimm_history_a csm_dimm_history index on history_time ix_csm_dimm_history_b csm_dimm_history index on node_name, serial_number ix_csm_dimm_history_d csm_dimm_history index on archive_history_time ix_csm_gpu_history_a csm_gpu_history index on history_time ix_csm_gpu_history_b csm_gpu_history index on serial_number ix_csm_gpu_history_c csm_gpu_history index on node_name, gpu_id ix_csm_gpu_history_e csm_gpu_history index on archive_history_time ix_csm_hca_history_a csm_hca_history index on history_time ix_csm_hca_history_b csm_hca_history index on node_name, serial_number ix_csm_hca_history_d csm_hca_history index on archive_history_time ix_csm_ib_cable_history_a csm_ib_cable_history index on history_time ix_csm_ib_cable_history_b csm_ib_cable_history index on serial_number ix_csm_ib_cable_history_d csm_ib_cable_history index on archive_history_time ix_csm_lv_a csm_lv index on logical_volume_name ix_csm_lv_history_a csm_lv_history index on history_time ix_csm_lv_history_b csm_lv_history index on logical_volume_name ix_csm_lv_history_d csm_lv_history index on archive_history_time ix_csm_lv_update_history_a csm_lv_update_history index on history_time ix_csm_lv_update_history_b csm_lv_update_history index on logical_volume_name ix_csm_lv_update_history_d csm_lv_update_history index on archive_history_time ix_csm_node_a csm_node index on state, node_name ix_csm_node_history_a csm_node_history index on history_time ix_csm_node_history_b csm_node_history index on node_name ix_csm_node_history_d csm_node_history index on archive_history_time ix_csm_node_state_history_a csm_node_state_history index on history_time ix_csm_node_state_history_b csm_node_state_history index on state, node_name ix_csm_node_state_history_d csm_node_state_history index on archive_history_time ix_csm_processor_socket_history_a csm_processor_socket_history index on history_time ix_csm_processor_socket_history_b csm_processor_socket_history index on serial_number, node_name ix_csm_processor_socket_history_d csm_processor_socket_history index on archive_history_time ix_csm_ras_event_action_a csm_ras_event_action index on msg_id ix_csm_ras_event_action_b csm_ras_event_action index on time_stamp ix_csm_ras_event_action_c csm_ras_event_action index on location_name ix_csm_ras_event_action_d csm_ras_event_action index on time_stamp, msg_id ix_csm_ras_event_action_e csm_ras_event_action index on time_stamp, location_name ix_csm_ras_event_action_f csm_ras_event_action index on master_time_stamp ix_csm_ras_event_action_h csm_ras_event_action index on archive_history_time ix_csm_ssd_history_a csm_ssd_history index on history_time ix_csm_ssd_history_b csm_ssd_history index on serial_number, node_name ix_csm_ssd_history_d csm_ssd_history index on archive_history_time ix_csm_ssd_wear_history_a csm_ssd_wear_history index on history_time ix_csm_ssd_wear_history_b csm_ssd_wear_history index on serial_number, node_name ix_csm_ssd_wear_history_d csm_ssd_wear_history index on archive_history_time ix_csm_step_history_a csm_step_history index on history_time ix_csm_step_history_b csm_step_history index on end_time, begin_time ix_csm_step_history_c csm_step_history index on end_time, allocation_id ix_csm_step_history_d csm_step_history index on end_time ix_csm_step_history_e csm_step_history index on step_id ix_csm_step_history_g csm_step_history index on archive_history_time ix_csm_step_node_b csm_step_node index on allocation_id ix_csm_step_node_c csm_step_node index on allocation_id, step_id ix_csm_step_node_history_a csm_step_node_history index on history_time ix_csm_step_node_history_b csm_step_node_history index on allocation_id ix_csm_step_node_history_c csm_step_node_history index on step_id, allocation_id ix_csm_step_node_history_e csm_step_node_history index on archive_history_time ix_csm_switch_history_a csm_switch_history index on history_time ix_csm_switch_history_b csm_switch_history index on switch_name, history_time ix_csm_switch_history_d csm_switch_history index on archive_history_time ix_csm_switch_inventory_history_a csm_switch_inventory_history index on history_time ix_csm_switch_inventory_history_b csm_switch_inventory_history index on name ix_csm_switch_inventory_history_d csm_switch_inventory_history index on archive_history_time ix_csm_vg_history_a csm_vg_history index on history_time ix_csm_vg_history_b csm_vg_history index on node_name, vg_name ix_csm_vg_history_d csm_vg_history index on archive_history_time ix_csm_vg_ssd_history_a csm_vg_ssd_history index on history_time ix_csm_vg_ssd_history_b csm_vg_ssd_history index on vg_name, node_name ix_csm_vg_ssd_history_d csm_vg_ssd_history index on archive_history_time Unique UKs¶
Index Name Table Name Index on Column Names uk_csm_allocation_node_b csm_allocation_node uniqueness on allocation_id, node_name uk_csm_ssd_a csm_ssd uniqueness on serial_number, node_name uk_csm_step_a csm_step uniqueness on allocation_id, step_id uk_csm_step_node_a csm_step_node uniqueness on node_name, step_id, allocation_id uk_csm_switch_gu_id_a csm_switch uniqueness on gu_id uk_csm_vg_ssd_a csm_vg_ssd uniqueness on vg_name, node_name, serial_number Functions and Triggers¶
Function Name Trigger Name Trigger Table Trigger Type Result Data Type Action On Argument Data Type Description fn_csm_allocation_create_data_aggregator (Stored Procedure) timestamp without time zone i_allocation_id bigint, i_state text, i_node_names text[], i_ib_rx_list bigint[], i_ib_tx_list bigint[], i_gpfs_read_list bigint[], i_gpfs_write_list bigint[], i_energy bigint[], i_power_cap integer[], i_ps_ratio integer[], i_power_cap_hit bigint[], i_gpu_energy bigint[], OUT o_timestamp timestamp without time zone csm_allocation_node function to populate the data aggregator fields in csm_allocation_node. fn_csm_allocation_dead_records_on_lv (Stored Procedure) void i_allocation_id bigint Delete any lvs on an allocation that is being deleted. fn_csm_allocation_delete_start (Stored Procedure) record i_allocation_id bigint, i_primary_job_id bigint, i_secondary_job_id integer, i_timeout_time bigint, OUT o_allocation_id bigint, OUT o_primary_job_id bigint, OUT o_secondary_job_id integer, OUT o_user_flags text, OUT o_system_flags text, OUT o_num_nodes integer, OUT o_state text, OUT o_type text, OUT o_isolated_cores integer, OUT o_user_name text, OUT o_nodelist text, OUT o_runtime bigint Retrieves allocation details for delete a d sets the state to deleteing. fn_csm_allocation_finish_data_stats (Stored Procedure) record allocationid bigint, i_state text, node_names text[], ib_rx_list bigint[], ib_tx_list bigint[], gpfs_read_list bigint[], gpfs_write_list bigint[], energy_list bigint[], pc_hit_list bigint[], gpu_usage_list bigint[], cpu_usage_list bigint[], mem_max_list bigint[], gpu_energy_list bigint[], OUT o_end_time timestamp without time zone, OUT o_final_state text csm_allocation function to finalize the data aggregator fields. fn_csm_allocation_history_dump (Stored Procedure) timestamp without time zone allocationid bigint, endtime timestamp without time zone, exitstatus integer, i_state text, finalize boolean, node_names text[], ib_rx_list bigint[], ib_tx_list bigint[], gpfs_read_list bigint[], gpfs_write_list bigint[], energy_list bigint[], pc_hit_list bigint[], gpu_usage_list bigint[], cpu_usage_list bigint[], mem_max_list bigint[], gpu_energy_list bigint[], OUT o_end_time timestamp without time zone csm_allocation function to amend summarized column(s) on DELETE. (csm_allocation_history_dump) fn_csm_allocation_node_change tr_csm_allocation_node_change csm_allocation_node BEFORE trigger DELETE csm_allocation_node function to amend summarized column(s) on UPDATE and DELETE. fn_csm_allocation_node_sharing_status (Stored Procedure) void i_allocation_id bigint, i_type text, i_state text, i_shared boolean, i_nodenames text[] csm_allocation_sharing_status function to handle exclusive usage of shared nodes on INSERT. fn_csm_allocation_revert (Stored Procedure) void allocationid bigint Removes all traces of an allocation that never multicasted. fn_csm_allocation_state_history_state_change tr_csm_allocation_state_change csm_allocation BEFORE trigger INSERT, UPDATE csm_allocation_state_change function to amend summarized column(s) on UPDATE. fn_csm_allocation_update tr_csm_allocation_update csm_allocation BEFORE trigger UPDATE csm_allocation_update function to amend summarized column(s) on UPDATE. fn_csm_allocation_update_state (Stored Procedure) record i_allocationid bigint, i_state text, OUT o_primary_job_id bigint, OUT o_secondary_job_id integer, OUT o_user_flags text, OUT o_system_flags text, OUT o_num_nodes integer, OUT o_nodes text, OUT o_isolated_cores integer, OUT o_user_name text, OUT o_shared boolean, OUT o_num_gpus integer, OUT o_num_processors integer, OUT o_projected_memory integer, OUT o_state text, OUT o_runtime bigint, OUT o_smt_mode smallint, OUT o_core_blink boolean csm_allocation_update_state function that ensures the allocation can be legally updated to the supplied state fn_csm_config_history_dump tr_csm_config_history_dump csm_config BEFORE trigger UPDATE, DELETE csm_config function to amend summarized column(s) on UPDATE and DELETE. fn_csm_db_schema_version_history_dump tr_csm_db_schema_version_history_dump csm_db_schema_version BEFORE trigger UPDATE, DELETE csm_db_schema_version function to amend summarized column(s) on UPDATE and DELETE. fn_csm_diag_result_history_dump tr_csm_diag_result_history_dump csm_diag_result BEFORE trigger DELETE csm_diag_result function to amend summarized column(s) on DELETE. fn_csm_diag_run_history_dump (Stored Procedure) void _run_id bigint, _end_time timestamp with time zone, _status text, _inserted_ras boolean csm_diag_run function to amend summarized column(s) on UPDATE and DELETE. (csm_diag_run_history_dump) fn_csm_dimm_history_dump tr_csm_dimm_history_dump csm_dimm BEFORE trigger INSERT, UPDATE, DELETE csm_dimm function to amend summarized column(s) on UPDATE and DELETE. fn_csm_gpu_history_dump tr_csm_gpu_history_dump csm_gpu BEFORE trigger INSERT, UPDATE, DELETE csm_gpu function to amend summarized column(s) on UPDATE and DELETE. fn_csm_hca_history_dump tr_csm_hca_history_dump csm_hca BEFORE trigger INSERT, UPDATE, DELETE csm_hca function to amend summarized column(s) on UPDATE and DELETE. fn_csm_ib_cable_history_dump tr_csm_ib_cable_history_dump csm_ib_cable BEFORE trigger INSERT, UPDATE, DELETE csm_ib_cable function to amend summarized column(s) on UPDATE and DELETE. fn_csm_ib_cable_inventory_collection (Stored Procedure) record i_record_count integer, i_serial_number text[], i_comment text[], i_guid_s1 text[], i_guid_s2 text[], i_identifier text[], i_length text[], i_name text[], i_part_number text[], i_port_s1 text[], i_port_s2 text[], i_revision text[], i_severity text[], i_type text[], i_width text[], OUT o_insert_count integer, OUT o_update_count integer, OUT o_delete_count integer function to INSERT and UPDATE ib cable inventory. fn_csm_lv_history_dump (Stored Procedure) void i_logical_volume_name text, i_node_name text, i_allocationid bigint, i_updated_time timestamp without time zone, i_end_time timestamp without time zone, i_num_bytes_read bigint, i_num_bytes_written bigint, i_num_reads bigint, i_num_writes bigint csm_lv function to amend summarized column(s) on DELETE. (csm_lv_history_dump) fn_csm_lv_modified_history_dump (Stored Procedure) trigger fn_csm_lv_update_history_dump tr_csm_lv_update_history_dump csm_lv BEFORE trigger UPDATE csm_lv_update_history_dump function to amend summarized column(s) on UPDATE. fn_csm_lv_upsert (Stored Procedure) void l_logical_volume_name text, l_node_name text, l_allocation_id bigint, l_vg_name text, l_state character, l_current_size bigint, l_max_size bigint, l_begin_time timestamp without time zone, l_updated_time timestamp without time zone, l_file_system_mount text, l_file_system_type text csm_lv_upsert function to amend summarized column(s) on INSERT. (csm_lv table) fn_csm_node_attributes_query_details (Stored Procedure) node_details i_node_name text csm_node_attributes_query_details function to HELP CSM API. fn_csm_node_delete (Stored Procedure) record i_node_names text[], OUT o_not_deleted_node_names_count integer, OUT o_not_deleted_node_names text Function to delete a node, and remove records in the csm_node, csm_ssd, csm_processor, csm_gpu, csm_hca, csm_dimm tables fn_csm_node_state tr_csm_node_state csm_node BEFORE trigger INSERT, UPDATE csm_node function to amend summarized column(s) on UPDATE. fn_csm_node_state_history_temp_table (Stored Procedure) SETOF record i_state compute_node_states, i_start_t timestamp without time zone, i_end_t timestamp without time zone, OUT node_name text, OUT state compute_node_states, OUT hours_of_state numeric, OUT total_range_time numeric, OUT “%_of_state” numeric function to gather statistical information related to the csm_node_state_history state durations. fn_csm_node_update tr_csm_node_update csm_node BEFORE trigger INSERT, UPDATE, DELETE csm_node_update function to amend summarized column(s) on UPDATE and DELETE. fn_csm_processor_socket_history_dump tr_csm_processor_socket_history_dump csm_processor_socket BEFORE trigger INSERT, UPDATE, DELETE csm_processor_socket function to amend summarized column(s) on UPDATE and DELETE. fn_csm_ras_type_update tr_csm_ras_type_update csm_ras_type AFTER trigger INSERT, UPDATE, DELETE csm_ras_type function to add rows to csm_ras_type_audit on INSERT and UPDATE and DELETE. (csm_ras_type_update) fn_csm_ssd_dead_records (Stored Procedure) void i_sn text Delete any vg and lv on an ssd that is being deleted. fn_csm_ssd_history_dump tr_csm_ssd_history_dump csm_ssd BEFORE trigger INSERT, UPDATE, DELETE csm_ssd function to amend summarized column(s) on UPDATE and DELETE. fn_csm_ssd_wear tr_csm_ssd_wear csm_ssd BEFORE trigger UPDATE csm_ssd function to amend summarized column(s) on UPDATE. fn_csm_step_begin (Stored Procedure) timestamp without time zone i_step_id bigint, i_allocation_id bigint, i_status text, i_executable text, i_working_directory text, i_argument text, i_environment_variable text, i_num_nodes integer, i_num_processors integer, i_num_gpus integer, i_projected_memory integer, i_num_tasks integer, i_user_flags text, i_node_names text[], OUT o_begin_time timestamp without time zone csm_step_begin function to begin a step, adds the step to csm_step and csm_step_node fn_csm_step_end (Stored Procedure) record i_stepid bigint, i_allocationid bigint, i_exitstatus integer, i_errormessage text, i_cpustats text, i_totalutime double precision, i_totalstime double precision, i_ompthreadlimit text, i_gpustats text, i_memorystats text, i_maxmemory bigint, i_iostats text, OUT o_user_flags text, OUT o_num_nodes integer, OUT o_nodes text, OUT o_end_time timestamp without time zone csm_step_end function to delete the step from the nodes table (fn_csm_step_end) fn_csm_step_history_dump (Stored Procedure) void i_stepid bigint, i_allocationid bigint, i_endtime timestamp with time zone, i_exitstatus integer, i_errormessage text, i_cpustats text, i_totalutime double precision, i_totalstime double precision, i_ompthreadlimit text, i_gpustats text, i_memorystats text, i_maxmemory bigint, i_iostats text csm_step function to amend summarized column(s) on DELETE. (csm_step_history_dump) fn_csm_step_node_history_dump tr_csm_step_node_history_dump csm_step_node BEFORE trigger DELETE csm_step_node function to amend summarized column(s) on DELETE. (csm_step_node_history_dump) fn_csm_switch_attributes_query_details (Stored Procedure) switch_details i_switch_name text csm_switch_attributes_query_details function to HELP CSM API. fn_csm_switch_children_inventory_collection (Stored Procedure) record i_record_count integer, i_name text[], i_host_system_guid text[], i_comment text[], i_description text[], i_device_name text[], i_device_type text[], i_hw_version text[], i_max_ib_ports integer[], i_module_index integer[], i_number_of_chips integer[], i_path text[], i_serial_number text[], i_severity text[], i_status text[], i_type text[], i_fw_version text[], OUT o_insert_count integer, OUT o_update_count integer, OUT o_delete_count integer function to INSERT and UPDATE switch children inventory. fn_csm_switch_history_dump tr_csm_switch_history_dump csm_switch BEFORE trigger INSERT, UPDATE, DELETE csm_switch function to amend summarized column(s) on UPDATE and DELETE. fn_csm_switch_inventory_collection (Stored Procedure) record i_record_count integer, i_switch_name text[], i_serial_number text[], i_comment text[], i_description text[], i_fw_version text[], i_gu_id text[], i_has_ufm_agent boolean[], i_hw_version text[], i_ip text[], i_model text[], i_num_modules integer[], i_physical_frame_location text[], i_physical_u_location text[], i_ps_id text[], i_role text[], i_server_operation_mode text[], i_sm_mode text[], i_state text[], i_sw_version text[], i_system_guid text[], i_system_name text[], i_total_alarms integer[], i_type text[], i_vendor text[], OUT o_insert_count integer, OUT o_update_count integer, OUT o_delete_count integer, OUT o_delete_module_count integer function to INSERT and UPDATE switch inventory. fn_csm_switch_inventory_history_dump tr_csm_switch_inventory_history_dump csm_switch_inventory BEFORE trigger INSERT, UPDATE, DELETE csm_switch_inventory function to amend summarized column(s) on UPDATE and DELETE. fn_csm_vg_create (Stored Procedure) void i_available_size bigint, i_node_name text, i_ssd_count integer, i_ssd_serial_numbers text[], i_ssd_allocations bigint[], i_total_size bigint, i_vg_name text, i_is_scheduler boolean Function to create a vg, adds the vg to csm_vg_ssd and csm_vg fn_csm_vg_delete (Stored Procedure) void i_node_name text, i_vg_name text Function to delete a vg, and remove records in the csm_vg and csm_vg_ssd tables fn_csm_vg_history_dump tr_csm_vg_history_dump csm_vg BEFORE trigger INSERT, UPDATE, DELETE csm_vg function to amend summarized column(s) on UPDATE and DELETE. fn_csm_vg_ssd_history_dump tr_csm_vg_ssd_history_dump csm_vg_ssd BEFORE trigger INSERT, UPDATE, DELETE csm_vg_ssd function to amend summarized column(s) on UPDATE and DELETE. func_alt_type_val (Stored Procedure) void _type regtype, _val text function to alter existing db types. func_csm_delete_func (Stored Procedure) integer _name text, OUT func_dropped integer function to drop all existing db functions. func_csm_drop_all_triggers (Stored Procedure) text function to drop all existing db triggers. Using csm_db_history_archive.py¶
This section describes the archiving process associated with the CSM DB history tables. If run alone it will archive all history tables in the CSM Database, including the csm_ras_event_action table.
Note
This script is designed to run as a root user. If you try to run as a postgres user the script will prompt a message and exit.
-bash-4.2$ ./csm_db_history_archive.py -h --------------------------------------------------------------------------------------------------------- [INFO] Only root can run this script ---------------------------------------------------------------------------------------------------------Usage Overview¶
/opt/ibm/csm/db/csm_db_history_archive.py –h /opt/ibm/csm/db/csm_db_history_archive.py --helpThe help command (-h, –help) will specify each of the options available to use.
Options Description Result running the script with no options ./csm_db_history_archive.py Will execute with default configured settings running the script with –t, –target ./csm_db_history_archive.py –t, –target Specifies the target directory where json files will be written to. running the script with -n, –count ./csm_db_history_archive.py –n, –count specifies the number of records to be archived. running the script with –d, –database ./csm_db_history_archive.py -d, –database specifies the database name running the script with –u, –user ./csm_db_history_archive.py –u, –user specifies the database user name. running the script with –-threads ./csm_db_history_archive.py –-threads specifies threads. running the script with –h, –help ./csm_db_history_archive.py –h, –help see details below Example (usage)¶
-bash-4.2$ ./csm_db_history_archive.py -h --------------------------------------------------------------------------------------------------------- usage: csm_db_history_archive.py [-h] [-t dir] [-n count] [-d db] [-u user] [--threads threads] ------------------------------------------------------------------------------ A tool for archiving the CSM Database history tables. ------------------------------------------------------------------------------ LogDir:/var/log/ibm/csm/db/csm_db_archive_script.log ------------------------------------------------------------------------------ optional arguments: -h, --help show this help message and exit -t dir, --target dir Target directory to write archive to. Default: /var/log/ibm/csm/archive -n count, --count count Number of records to archive in the run. Default: 1000 -d db, --database db Database to archive tables from. Default: csmdb -u user, --user user The database user. Default: postgres --threads threads The number of threads for the thread pool. Default: 10 ------------------------------------------------------------------------------Note
This is a general overview of the CSM DB archive history process using the
csm_db_history_archive.pyscript.Script overview¶
The script may largely be broken into
- Create a temporary table to archive history data based on a condition.
- Connect to the Database with the postgres user.
- Drops and creates the temp table used in the archival process.
- The first query selects all the fields in the table.
- The second and third query is a nested query that defines a particular row count that a user can pass in or can be set as a default value. The data is filter by using the history_time)..
- The where clause defines whether the archive_history_time field is NULL.
- The user will have the option to pass in a row count value (ex. 10,000 records).
- The data will be ordered by
history_time ASC.
- Copies all satisfied history data to a json file.
- Copies all the results from the temp table and appends to a json file
- Then updates the archive_history_timestamp field, which can be later deleted during the purging process).
- Updates the csm_[table_name]_history table
- Sets the archive_history_time = current timestamp
- From clause on the temp table
- WHERE (compares history_time, from history table to temp table) AND history.archive_history_time IS NULL.
Attention
If this script below is run manually it will display the results to the screen. This script handles all history table archiving in the database.
Script out results¶
[root@c650mnp02 db]# /opt/ibm/csm/db/csm_db_history_archive.py -d csmdb -n 100 --------------------------------------------------------------------------------------------------------- Welcome to the CSM DB archiving script --------------------------------------------------------------------------------------------------------- Start Script Time: | 2019-02-13 18:29:58.203024 --------------------------------------------------------------------------------------------------------- Archiving Log Directory: | /var/log/ibm/csm/db/csm_db_archive_script.log --------------------------------------------------------------------------------------------------------- DB Name: | csmdb DB User Name: | postgres Script User Name: | root Thread Count: | 10 Archiving Data Directory: | /var/log/ibm/csm/archive --------------------------------------------------------------------------------------------------------- [INFO] Processing Table csm_config_history | User Ct: 100 | Act DB Ct: 0 [INFO] Processing Table csm_allocation_history | User Ct: 100 | Act DB Ct: 0 [INFO] Processing Table csm_allocation_node_history | User Ct: 100 | Act DB Ct: 0 [INFO] Processing Table csm_db_schema_version_history | User Ct: 100 | Act DB Ct: 100 [INFO] Processing Table csm_allocation_state_history | User Ct: 100 | Act DB Ct: 0 [INFO] Processing Table csm_diag_result_history | User Ct: 100 | Act DB Ct: 0 [INFO] Processing Table csm_diag_run_history | User Ct: 100 | Act DB Ct: 0 [INFO] Processing Table csm_hca_history | User Ct: 100 | Act DB Ct: 0 [INFO] Processing Table csm_dimm_history | User Ct: 100 | Act DB Ct: 0 [INFO] Processing Table csm_ib_cable_history | User Ct: 100 | Act DB Ct: 0 [INFO] Processing Table csm_gpu_history | User Ct: 100 | Act DB Ct: 0 [INFO] Processing Table csm_lv_history | User Ct: 100 | Act DB Ct: 0 [INFO] Processing Table csm_lv_update_history | User Ct: 100 | Act DB Ct: 0 [INFO] Processing Table csm_processor_socket_history | User Ct: 100 | Act DB Ct: 0 [INFO] Processing Table csm_node_history | User Ct: 100 | Act DB Ct: 0 [INFO] Processing Table csm_ssd_history | User Ct: 100 | Act DB Ct: 0 [INFO] Processing Table csm_node_state_history | User Ct: 100 | Act DB Ct: 0 [INFO] Processing Table csm_ssd_wear_history | User Ct: 100 | Act DB Ct: 0 [INFO] Processing Table csm_step_history | User Ct: 100 | Act DB Ct: 0 [INFO] Processing Table csm_switch_inventory_history | User Ct: 100 | Act DB Ct: 0 [INFO] Processing Table csm_step_node_history | User Ct: 100 | Act DB Ct: 0 [INFO] Processing Table csm_vg_history | User Ct: 100 | Act DB Ct: 0 [INFO] Processing Table csm_switch_history | User Ct: 100 | Act DB Ct: 0 [INFO] Processing Table csm_vg_ssd_history | User Ct: 100 | Act DB Ct: 0 [INFO] Processing Table csm_ras_event_action | User Ct: 100 | Act DB Ct: 0 --------------------------------------------------------------------------------------------------------- End Script Time: | 2019-02-13 18:29:58.258318 Total Process Time: | 0:00:00.055294 --------------------------------------------------------------------------------------------------------- Finish CSM DB archive script process ---------------------------------------------------------------------------------------------------------Attention
While using the csm_stats_script (in another session) the user can monitor the results
/opt/ibm/csm/db/csm_db_stats.sh –t <db_name> /opt/ibm/csm/db/csm_db_stats.sh –-tableinfo <db_name>If a user specifies a non related DB in the system or if there are issues connecting to the DB server a message will display.
[root@c650mnp02 db]# /opt/ibm/csm/db/csm_db_history_archive.py -d csmd -t -n 100 --------------------------------------------------------------------------------------------------------- Welcome to the CSM DB archiving script --------------------------------------------------------------------------------------------------------- Start Script Time: | 2019-02-13 18:35:18.071116 --------------------------------------------------------------------------------------------------------- Archiving Log Directory: | /var/log/ibm/csm/db/csm_db_archive_script.log --------------------------------------------------------------------------------------------------------- DB Name: | csmdb DB User Name: | postgres Script User Name: | root Thread Count: | 10 Archiving Data Directory: | /var/log/ibm/csm/archive --------------------------------------------------------------------------------------------------------- [CRITICAL] Unable to connect to local database. [CRITICAL] Unable to connect to local database. [CRITICAL] Unable to connect to local database. [CRITICAL] Unable to connect to local database. [CRITICAL] Unable to connect to local database. [CRITICAL] Unable to connect to local database. [CRITICAL] Unable to connect to local database. [CRITICAL] Unable to connect to local database. [CRITICAL] Unable to connect to local database. [CRITICAL] Unable to connect to local database. [CRITICAL] Unable to connect to local database. [CRITICAL] Unable to connect to local database. [CRITICAL] Unable to connect to local database. [CRITICAL] Unable to connect to local database. [CRITICAL] Unable to connect to local database. [CRITICAL] Unable to connect to local database. [CRITICAL] Unable to connect to local database. [CRITICAL] Unable to connect to local database. [CRITICAL] Unable to connect to local database. [CRITICAL] Unable to connect to local database. [CRITICAL] Unable to connect to local database. [CRITICAL] Unable to connect to local database. [CRITICAL] Unable to connect to local database. [CRITICAL] Unable to connect to local database. [CRITICAL] Unable to connect to local database. --------------------------------------------------------------------------------------------------------- End Script Time: | 2019-02-13 18:29:58.258318 Total Process Time: | 0:00:00.055294 --------------------------------------------------------------------------------------------------------- Finish CSM DB archive script process ---------------------------------------------------------------------------------------------------------Note
Directory: Currently the scripts are setup to archive the results in a specified directory.
The history table data will be archived in a .json file format and in the specified or default directory:
csm_allocation_history.archive.2018-11-23.jsonThe history table log file will be in a .log file format and in the default directory:
/var/log/ibm/csm/db/csm_db_archive_script.logUsing csm_db_backup_script_v1.sh¶
To manually perform a cold backup a CSM database on the system the following script may be run.
/opt/ibm/csm/db/csm_db_backup_script_v1.shNote
This script should be run as the root or postgres user.
Attention
There are a few step that should be taken before backing up a CSM or related DB on the system.
Backup script actions¶
The following steps are behaviors recommended for use of the back up script:
- Stop all CSM daemons.
- Run the backup script.
Invocation: /opt/ibm/csm/db/csm_db_backup_script_v1.sh [DBNAME] [/DIR/]Default Directory: /var/lib/pgsql/backups/ The script will check the DB connections and if there are no active connections then the backup process will begin. If there are any active connections to the DB, an Error message will be displayed and the program will exit.
To terminate active connections: csm_db_connections_script.sh
- Once the DB been successfully backed-up then the admin can restart the daemons.
Running the csm_db_backup_script_v1.sh¶
Example (-h, –help)¶
./csm_db_backup_script_v1.sh –h, --help ------------------------------------------------------------------------------------------------------------------------ [Info ] csm_db_backup_script_v1.sh : csmdb /tmp/csmdb_backup/ [Info ] csm_db_backup_script_v1.sh : csmdb [Usage] csm_db_backup_script_v1.sh : [OPTION]... [/DIR/] ------------------------------------------------------------------------------------------------------------------------ [Log Dir ] /var/log/ibm/csm/db/csm_db_backup_script.log (if root user and able to write to directory) [Log Dir ] /tmp/csm_db_backup_script.log (if postgres user and or not able to write to specific directory ------------------------------------------------------------------------------------------------------------------------ [Options] ----------------|------------------------------------------------------------------------------------------------------- Argument | Description ----------------|------------------------------------------------------------------------------------------------------- -h, --help | help menu ----------------|------------------------------------------------------------------------------------------------------- [Examples] ------------------------------------------------------------------------------------------------------------------------ csm_db_backup_script_v1.sh [DBNAME] | (default) will backup database to/var/lib/pgpsql/backups/ (directory) csm_db_backup_script_v1.sh [DBNAME] [/DIRECTORY/ | will backup database to specified directory | if the directory doesnt exist then it will be mode and | written. ------------------------------------------------------------------------------------------------------------------------Attention
Common errors
If the user tries to run the script as local user without PostgreSQL installed and does not provide a database name:
- An info message will prompt ([Info ] Database name is required)
- The usage message will also prompt the usage help menu
Example (no options, usage)¶
bash-4.1$ ./csm_db_backup_script_v1.sh ------------------------------------------------------------------------------------------------------------------------ [Info ] Database name is required ------------------------------------------------------------------------------------------------------------------------ [Info ] csm_db_backup_script_v1.sh : csmdb /tmp/csmdb_backup/ [Info ] csm_db_backup_script_v1.sh : csmdb [Usage] csm_db_backup_script_v1.sh : [OPTION]... [/DIR/] ------------------------------------------------------------------------------------------------------------------------ [Log Dir ] /var/log/ibm/csm/db/csm_db_backup_script.log (if root user and able to write to directory) [Log Dir ] /tmp/csm_db_backup_script.log (if postgres user and or not able to write to specific directory ------------------------------------------------------------------------------------------------------------------------ [Options] ----------------|------------------------------------------------------------------------------------------------------- Argument | Description ----------------|------------------------------------------------------------------------------------------------------- -h, --help | help menu ----------------|------------------------------------------------------------------------------------------------------- [Examples] ------------------------------------------------------------------------------------------------------------------------ csm_db_backup_script_v1.sh [DBNAME] | (default) will backup database to/var/lib/pgpsql/backups/ (directory) csm_db_backup_script_v1.sh [DBNAME] [/DIRECTORY/ | will backup database to specified directory | if the directory doesnt exist then it will be mode and | written. ------------------------------------------------------------------------------------------------------------------------Note
If the user tries to run the script as local user (non-root and postgresql not installed):
Example (postgreSQL not installed)¶
bash-4.1$ ./csm_db_backup_script_v1.sh csmdb /tmp/ ----------------------------------------------------------------------------------------- [Error ] PostgreSQL may not be installed. Please check configuration settings -----------------------------------------------------------------------------------------Note
If the user tries to run the script as local user (non-root and postgresql not installed)and doesnt specify a directory (default directory:
/var/lib/pgsql/backupsExample (invalid directory specified)¶
bash-4.1$ ./csm_db_backup_script_v1.sh csmdb /tmp123 ----------------------------------------------------------------------------------------- [Error ] make directory failed for: /tmp123 [Info ] User: postgres does not have permission to write to this directory [Info ] Please specify a valid directory [Info ] Or log in as the appropriate user -----------------------------------------------------------------------------------------Usage Overview¶
/opt/ibm/csm/db/csm_db_backup_script_v1.sh csmdb (with no specified directory: default)Example (backup process with default directory)¶
If the user chooses to back up the database with the default directory which is
/var/lib/pgsql/backups/Alternativly the user can choose another location to write to if they have appropriate permissions.------------------------------------------------------------------------------------------------------------------------ [Start ] Welcome to CSM datatbase backup process: ------------------------------------------------------------------------------------------------------------------------ [Info ] There are no connections to: | csmdb [Info ] Backup directory: | /var/lib/pgsql/backups/ [Info ] Log directory: | /tmp/csm_db_backup_script.log [Info ] Backing up DB: | csmdb [Info ] DB_Version: | 19.0 [Info ] DB User Name: | postgres [Info ] Script User: | postgres [Info ] Script Stats: | [ 509kiB] [0:00:00] [2.38MiB/s] [Info ] ------------------------------------------------------------------------------------------------------------- [Info ] Timing: | 0:00:00:0.2535 ------------------------------------------------------------------------------------------------------------------------ [End ] Backup process complete ------------------------------------------------------------------------------------------------------------------------Attention
PV was added to monitor backup statistics: pv allows a user to see the progress of data through a pipeline, by giving information such as total data transferred, time elapsed, and current throughput rate.
Using csm_db_connections_script.sh¶
This script is designed to list and/or kill all active connections to a PostgreSQL database. Logging for this script is placed in /var/log/ibm/csm/csm_db_connections_script.log This script can be ran as either
postgresorrootusers. If the script is ran as thepostgresuser then the log file may be written to the:/tmp/csm_db_connections_script.logdirectory. the script will specify the logging directory when executed.Usage Overview¶
/opt/ibm/csm/db/csm_db_connections_script.sh –h /opt/ibm/csm/db/csm_db_connections_script.sh --helpThe help command (-h, –help) will specify each of the options available to use.
Options Description Result running the script with no options ./csm_db_connections_script.sh Try ‘csm_db_connections_script.sh –help’ for more information. running the script with –l, –list ./csm_db_connections_script.sh –l, –list list database sessions. running the script with -k, –kill ./csm_db_connections_script.sh –k, –kill kill/terminate database sessions. running the script with –f, –force ./csm_db_connections_script.sh –f, –force force kill (do not ask for confirmation, use in conjunction with -k option). running the script with –u, –user ./csm_db_connections_script.sh –u, –user specify database user name. running the script with –p, –pid ./csm_db_connections_script.sh –p, –pid specify database user process id (pid). running the script with –h, –help ./csm_db_connections_script.sh –h, –help see details below Example (usage)¶
-bash-4.2$ ./csm_db_connections_script.sh --help ----------------------------------------------------------------------------------------------------------------- [Start ] Welcome to CSM datatbase connections script. ----------------------------------------------------------------------------------------------------------------- [Info ] /var/log/ibm/csm/db/csm_db_connections_script.log ----------------------------------------------------------------------------------------------------------------- [Info ] csm_db_connections_script.sh : List/Kill database user sessions [Usage] csm_db_connections_script.sh : [OPTION]... [USER] ----------------------------------------------------------------------------------------------------------------- [Options] ----------------|------------------------------------------------------------------------------------------------ Argument | Description ----------------|------------------------------------------------------------------------------------------------ -l, --list | list database sessions -k, --kill | kill/terminate database sessions -f, --force | force kill (do not ask for confirmation, | use in conjunction with -k option) -u, --user | specify database user name -p, --pid | specify database user process id (pid) -h, --help | help menu ----------------|------------------------------------------------------------------------------------------------ [Examples] ----------------------------------------------------------------------------------------------------------------- csm_db_connections_script.sh -l, --list | list all session(s) csm_db_connections_script.sh -l, --list -u, --user [USERNAME] | list user session(s) csm_db_connections_script.sh -k, --kill | kill all session(s) csm_db_connections_script.sh -k, --kill -f, --force | force kill all session(s) csm_db_connections_script.sh -k, --kill -u, --user [USERNAME] | kill user session(s) csm_db_connections_script.sh -k, --kill -p, --pid [PIDNUMBER]| kill user session with a specific pid -----------------------------------------------------------------------------------------------------------------Listing all DB connections¶
To display all current DB connections:
/opt/ibm/csm/db/csm_db_connections_script.sh -l /opt/ibm/csm/db/csm_db_connections_script.sh --listExample (-l, –list)¶
-bash-4.2$ ./csm_db_connections_script.sh –l ------------------------------------------------------------------------------------------------------------------------ [Start ] Welcome to CSM datatbase connections script. ------------------------------------------------------------------------------------------------------------------------ [Info ] /var/log/ibm/csm/db/csm_db_connections_script.log ------------------------------------------------------------------------------------------------------------------------ [Info ] Database Session | (all_users): 13 ------------------------------------------------------------------------------------------------------------------------ pid | database | user | connection_duration -------+----------+----------+----------------------- 61427 | xcatdb | xcatadm | 02:07:26.587854 61428 | xcatdb | xcatadm | 02:07:26.586227 73977 | postgres | postgres | 00:00:00.000885 72657 | csmdb | csmdb | 00:06:17.650398 72658 | csmdb | csmdb | 00:06:17.649185 72659 | csmdb | csmdb | 00:06:17.648012 72660 | csmdb | csmdb | 00:06:17.646846 72661 | csmdb | csmdb | 00:06:17.645662 72662 | csmdb | csmdb | 00:06:17.644473 72663 | csmdb | csmdb | 00:06:17.643285 72664 | csmdb | csmdb | 00:06:17.642105 72665 | csmdb | csmdb | 00:06:17.640927 72666 | csmdb | csmdb | 00:06:17.639771 (13 rows) ------------------------------------------------------------------------------------------------------------------------To display specified user(s) currently connected to the DB:
/opt/ibm/csm/db/csm_db_connections_script.sh -l –u <username> /opt/ibm/csm/db/csm_db_connections_script.sh --list --user <username>Note
The script will display the total users connected along with total users.
Example (-l, –list –u, –user)¶
-bash-4.2$ ./csm_db_connections_script.sh -l -u postgres ------------------------------------------------------------------------------------------------------------------------ [Start] Welcome to CSM datatbase connections script. ------------------------------------------------------------------------------------------------------------------------ [Info ] /var/log/ibm/csm/db/csm_db_connections_script.log ------------------------------------------------------------------------------------------------------------------------ [Info ] Database Session | (all_users): 13 [Info ] Session List | (postgres): 1 ------------------------------------------------------------------------------------------------------------------------ pid | database | user | connection_duration -------+----------+----------+--------------------- 74094 | postgres | postgres | 00:00:00.000876 (1 row) ------------------------------------------------------------------------------------------------------------------------Example (not specifying a specific user with the -l -u)¶
-bash-4.2$ ./csm_db_connections_script.sh -l -u ------------------------------------------------------------------------------------------------------------------------ [Start ] Welcome to CSM datatbase connections script. ------------------------------------------------------------------------------------------------------------------------ [Info ] /var/log/ibm/csm/db/csm_db_connections_script.log ------------------------------------------------------------------------------------------------------------------------ [Error ] Please specify user name ------------------------------------------------------------------------------------------------------------------------Example (invalid db user or not connected)¶
-bash-4.2$ ./csm_db_connections_script.sh -l -u 123 ------------------------------------------------------------------------------------------------------------------------ [Start ] Welcome to CSM datatbase connections script. ------------------------------------------------------------------------------------------------------------------------ [Info ] /var/log/ibm/csm/db/csm_db_connections_script.log ------------------------------------------------------------------------------------------------------------------------ [Error ] DB user: 123 is not connected or is invalid ------------------------------------------------------------------------------------------------------------------------ #-bash-4.2$ ./csm_db_connections_script.sh -k -u csmdbsadsd #[Error] DB user: csmdbsadsd is not connected or is invalid #------------------------------------------------------------------------------------------------------------------------Kill all DB connections¶
The user has the ability to kill all DB connections by using the
–k, --killoption:/opt/ibm/csm/db/csm_db_connections_script.sh -k /opt/ibm/csm/db/csm_db_connections_script.sh --killNote
If this option is chosen by itself, the script will prompt each session with a yes/no request. The user has the ability to manually kill or not kill each session. All responses are logged to the:
/var/log/ibm/csm/csm_db_connections_script.logExample (-k, –kill)¶
-bash-4.2$ ./csm_db_connections_script.sh –k ------------------------------------------------------------------------------------------------------------------------ [Start] Welcome to CSM datatbase connections script. ------------------------------------------------------------------------------------------------------------------------ [Info ] /var/log/ibm/csm/db/csm_db_connections_script.log ------------------------------------------------------------------------------------------------------------------------ [Info ] Kill database session (PID:61427) [y/n] ?: -------------------------------------------------------------------------------------------------------------------------bash-4.2$ ./csm_db_connections_script.sh –k ------------------------------------------------------------------------------------------------------------------------ [Start] Welcome to CSM datatbase connections script. ------------------------------------------------------------------------------------------------------------------------ [Info ] /var/log/ibm/csm/db/csm_db_connections_script.log ------------------------------------------------------------------------------------------------------------------------ [Start] Welcome to CSM datatbase connections script. [Info ] PostgreSQL is installed [Info ] Kill database session (PID:61427) [y/n] ?: [Info ] User response: n [Info ] Kill database session (PID:61428) [y/n] ?: [Info ] User response: n [Info ] Kill database session (PID:74295) [y/n] ?: [Info ] User response: n [Info ] Kill database session (PID:72657) [y/n] ?: [Info ] User response: n [Info ] Kill database session (PID:72658) [y/n] ?: [Info ] User response: n [Info ] Kill database session (PID:72659) [y/n] ?: [Info ] User response: n [Info ] Kill database session (PID:72660) [y/n] ?: [Info ] User response: n [Info ] Kill database session (PID:72661) [y/n] ?: [Info ] User response: n [Info ] Kill database session (PID:72662) [y/n] ?: [Info ] User response: n [Info ] Kill database session (PID:72663) [y/n] ?: [Info ] User response: n [Info ] Kill database session (PID:72664) [y/n] ?: [Info ] User response: n [Info ] Kill database session (PID:72665) [y/n] ?: [Info ] User response: n [Info ] Kill database session (PID:72666) [y/n] ?: [Info ] User response: n ------------------------------------------------------------------------------------------------------------------------Force kill all DB connections¶
The user has the ability to force kill all DB connections by using the
–k, --kill –f, --forceoption./opt/ibm/csm/db/csm_db_connections_script.sh -k –f /opt/ibm/csm/db/csm_db_connections_script.sh --kill --forceWarning
If this option is chosen by itself, the script will kill each open session(s).
All responses are logged to the:
/var/log/ibm/csm/csm_db_connections_script.logExample (-k, –kill –f, –force)¶
-bash-4.2$ ./csm_db_connections_script.sh –k -f ------------------------------------------------------------------------------------------------------------------------ [Start] Welcome to CSM datatbase connections script. ------------------------------------------------------------------------------------------------------------------------ [Info ] /var/log/ibm/csm/db/csm_db_connections_script.log ------------------------------------------------------------------------------------------------------------------------ [Info ] Killing session (PID:61427) [Info ] Killing session (PID:61428) [Info ] Killing session (PID:74295) [Info ] Killing session (PID:72657) [Info ] Killing session (PID:72658) [Info ] Killing session (PID:72659) [Info ] Killing session (PID:72660) [Info ] Killing session (PID:72661) [Info ] Killing session (PID:72662) [Info ] Killing session (PID:72663) [Info ] Killing session (PID:72664) [Info ] Killing session (PID:72665) ------------------------------------------------------------------------------------------------------------------------Example (Log file output)¶
------------------------------------------------------------------------------------------------------------------------ 2017-11-01 15:54:27 (postgres) [Start] Welcome to CSM datatbase automation stats script. 2017-11-01 15:54:27 (postgres) [Info ] --------------------------------------------------------------------------------- 2017-11-01 15:54:27 (postgres) [Info ] DB Names: template1 | template0 | postgres | 2017-11-01 15:54:27 (postgres) [Info ] DB Names: xcatdb | csmdb 2017-11-01 15:54:27 (postgres) [Info ] --------------------------------------------------------------------------------- 2017-11-01 15:54:27 (postgres) [Info ] PostgreSQL is installed 2017-11-01 15:54:27 (postgres) [Info ] --------------------------------------------------------------------------------- 2017-11-01 15:54:27 (postgres) [Info ] Script execution: csm_db_connections_script.sh -k, --kill 2017-11-01 15:54:29 (postgres) [Info ] Killing user session (PID:61427) kill –TERM 61427 2017-11-01 15:54:29 (postgres) [Info ] Killing user session (PID:61428) kill –TERM 61428 2017-11-01 15:54:29 (postgres) [Info ] Killing user session (PID:74295) kill –TERM 74295 2017-11-01 15:54:29 (postgres) [Info ] Killing user session (PID:72657) kill –TERM 72657 2017-11-01 15:54:29 (postgres) [Info ] Killing user session (PID:72658) kill –TERM 72658 2017-11-01 15:54:30 (postgres) [Info ] Killing user session (PID:72659) kill –TERM 72659 2017-11-01 15:54:30 (postgres) [Info ] Killing user session (PID:72660) kill –TERM 72660 2017-11-01 15:54:30 (postgres) [Info ] Killing user session (PID:72661) kill –TERM 72661 2017-11-01 15:54:30 (postgres) [Info ] Killing user session (PID:72662) kill –TERM 72662 2017-11-01 15:54:31 (postgres) [Info ] Killing user session (PID:72663) kill –TERM 72663 2017-11-01 15:54:31 (postgres) [Info ] Killing user session (PID:72664) kill –TERM 72664 2017-11-01 15:54:31 (postgres) [Info ] Killing user session (PID:72665) kill –TERM 72665 2017-11-01 15:54:31 (postgres) [Info ] Killing user session (PID:72666) kill –TERM 72666 2017-11-01 15:54:31 (postgres) [Info ] --------------------------------------------------------------------------------- 2017-11-01 15:54:31 (postgres) [End ] Postgres DB kill query executed ------------------------------------------------------------------------------------------------------------------------Kill user connection(s)¶
The user has the ability to kill specific user DB connections by using the
–k, --killalong with–u, --useroption./opt/ibm/csm/db/csm_kill_db_connections_test_1.sh -k –u <username> /opt/ibm/csm/db/csm_kill_db_connections_test_1.sh --kill --user <username>Note
If this option is chosen then the script will prompt each session with a yes/no request. The user has the ability to manually kill or not kill each session.
All responses are logged to the:
/var/log/ibm/csm/csm_db_connections_script.logExample (-k, –kill –u, –user <username>)¶
-bash-4.2$ ./csm_db_connections_script.sh -k -u csmdb ------------------------------------------------------------------------------------------------------------------------ [Start] Welcome to CSM datatbase connections script. ------------------------------------------------------------------------------------------------------------------------ [Info ] /var/log/ibm/csm/db/csm_db_connections_script.log ------------------------------------------------------------------------------------------------------------------------ [Info ] DB user: csmdb is connected [Info ] PostgreSQL is installed [Info ] Kill database session (PID:61427) [y/n] ?: ------------------------------------------------------------------------------------------------------------------------Example (Single session user kill)¶
-bash-4.2$ ./csm_db_connections_script.sh -k -u csmdb ------------------------------------------------------------------------------------------------------------------------ [Start] Welcome to CSM datatbase connections script. ------------------------------------------------------------------------------------------------------------------------ [Info ] /var/log/ibm/csm/db/csm_db_connections_script.log ------------------------------------------------------------------------------------------------------------------------ [Info ] DB user: csmdb is connected [Info ] Kill database session (PID:61427) [y/n] ?: [Info ] User response: y [Info ] Killing session (PID:61427) ------------------------------------------------------------------------------------------------------------------------Example (Multiple session user kill)¶
-bash-4.2$ ./csm_db_connections_script.sh -k -u csmdb ------------------------------------------------------------------------------------------------------ [Start] Welcome to CSM datatbase connections script. ------------------------------------------------------------------------------------------------------------------------ [Info ] /var/log/ibm/csm/db/csm_db_connections_script.log ------------------------------------------------------------------------------------------------------------------------ [Info ] PostgreSQL is installed [Info ] Kill database session (PID:61427) [y/n] ?: [Info ] User response: y [Info ] Killing session (PID:61427) [Info ] Kill database session (PID:61428) [y/n] ?: [Info ] User response: y [Info ] Killing session (PID:61428) ------------------------------------------------------------------------------------------------------Example (not specifying a specific user with the -k -u)¶
-bash-4.2$ ./csm_db_connections_script.sh -k -u ------------------------------------------------------------------------------------------------------------------------ [Start ] Welcome to CSM datatbase connections script. ------------------------------------------------------------------------------------------------------------------------ [Info ] /var/log/ibm/csm/db/csm_db_connections_script.log ------------------------------------------------------------------------------------------------------------------------ [Error ] Please specify user name ------------------------------------------------------------------------------------------------------------------------Example (invalid db user or not connected)¶
-bash-4.2$ ./csm_db_connections_script.sh -k -u 123 ------------------------------------------------------------------------------------------------------------------------ [Start ] Welcome to CSM datatbase connections script. ------------------------------------------------------------------------------------------------------------------------ [Info ] /var/log/ibm/csm/db/csm_db_connections_script.log ------------------------------------------------------------------------------------------------------------------------ [Error ] DB user: 123 is not connected or is invalid ------------------------------------------------------------------------------------------------------------------------Kill PID connection(s)¶
The user has the ability to kill specific user DB connections by using the
–k, --killalong with–p, --pidoption./opt/ibm/csm/db/csm_db_connections_script.sh -k –p <pidnumber> /opt/ibm/csm/db/csm_db_connections_script.sh --kill --pid <pidnumber>Note
If this option is chosen then the script will prompt the session with a yes/no request.
The response is logged to the:
/var/log/ibm/csm/csm_db_connections_script.logExample (-k, –kill –u, –pid <pidnumber>)¶
-bash-4.2$ ./csm_db_connections_script.sh -k -p 61427 ------------------------------------------------------------------------------------------------------------------------ [Start] Welcome to CSM datatbase connections script. ------------------------------------------------------------------------------------------------------------------------ [Info ] /var/log/ibm/csm/db/csm_db_connections_script.log ------------------------------------------------------------------------------------------------------------------------ [Info ] DB PID: 61427 is connected [Info ] PostgreSQL is installed [Info ] Kill database session (PID:61427) [y/n] ?: -------------------------------------------------------------------------------------------------------------------------bash-4.2$ ./csm_db_connections_script.sh -k -p 61427 ------------------------------------------------------------------------------------------------------------------------ [Start] Welcome to CSM datatbase connections script. ------------------------------------------------------------------------------------------------------------------------ [Info ] /var/log/ibm/csm/db/csm_db_connections_script.log ------------------------------------------------------------------------------------------------------------------------ [Info ] DB PID: 61427 is connected [Info ] PostgreSQL is installed [Info ] Kill database session (PID:61427) [y/n] ?: [Info ] User response: y [Info ] Killing session (PID:61427) ------------------------------------------------------------------------------------------------------------------------Example (not specifying a specific PID with the -k -p)¶
-bash-4.2$ ./csm_db_connections_script.sh -k -p ------------------------------------------------------------------------------------------------------------------------ [Start ] Welcome to CSM datatbase connections script. ------------------------------------------------------------------------------------------------------------------------ [Info ] /var/log/ibm/csm/db/csm_db_connections_script.log ------------------------------------------------------------------------------------------------------------------------ [Error ] Please specify pid ------------------------------------------------------------------------------------------------------------------------Example (invalid db PID or not connected)¶
-bash-4.2$ ./csm_db_connections_script.sh -k -u 123 ------------------------------------------------------------------------------------------------------------------------ [Start ] Welcome to CSM datatbase connections script. ------------------------------------------------------------------------------------------------------------------------ [Info ] /var/log/ibm/csm/db/csm_db_connections_script.log ------------------------------------------------------------------------------------------------------------------------ [Error ] DB PID: 123 is not connected or is invalid ------------------------------------------------------------------------------------------------------------------------Using csm_db_history_delete.py¶
This section describes the deletion process associated with the CSM Database history table records. If run alone it will delete all history tables including the csm_event_action table, which contain a non-null archive history timestamp.
Note
This script is designed to run as a root user. If you try to run as a postgres user the script will prompt a message and exit.
-bash-4.2$ ./csm_db_history_delete.py -h --------------------------------------------------------------------------------------------------------- [INFO] Only root can run this script ---------------------------------------------------------------------------------------------------------Usage Overview¶
- The
csm_db_history_delete.pyscript will accept certain flags:
- Interval time (in minutes) - required (tunable time interval for managing table record deletions)
- Database name - required
- DB user_name - optional
- Thread Count - optional
/opt/ibm/csm/db/csm_db_history_delete.py –h /opt/ibm/csm/db/csm_db_history_delete.py --help
Options Description Result running the script with no options ./csm_db_history_delete.py Will prompt a message explaining that the -n/–count and or -d/–database is required running the script with
-n, –count
./csm_db_history_delete.py –n, –count specifies the time (in mins.) of oldest records which to delete. (required) running the script with –d, –database ./csm_db_history_delete.py -d, –database specifies the database name (required) running the script with –u, –user ./csm_db_history_delete.py –u, –user specifies the database user name. (optional) running the script with –-threads ./csm_db_history_delete.py –-threads specifies threads. (optional) running the script with –h, –help ./csm_db_history_deletee.py –h, –help see details below Example (usage)¶
-bash-4.2$ /opt/ibm/csm/db/csm_db_history_delete.py –h --------------------------------------------------------------------------------------------------------- usage: csm_db_history_delete.py [-h] -n count -d db [-u user] [--threads threads] ------------------------------------------------------------------------------ A tool for deleting the CSM Database history table records. ------------------------------------------------------------------------------ LogDir:/var/log/ibm/csm/db/csm_db_history_delete.log ------------------------------------------------------------------------------ optional arguments: -h, --help show this help message and exit -n count, --count count The time (in mins.) of oldest records which to delete. required argument -d db, --database db Database name to delete history records from. required argument -u user, --user user The database user. Default: postgres --threads threads The number of threads for the thread pool. Default: 10 ------------------------------------------------------------------------------Note
This is a general overview of the CSM DB deletion process using the
csm_db_history_delete.pyscript.Script out results¶
[root@c650mnp02 db]# /opt/ibm/csm/db/csm_db_history_delete.py -d csmdb -n 2880 --------------------------------------------------------------------------------------------------------- Welcome to the CSM DB deletion of history table records script --------------------------------------------------------------------------------------------------------- Start Script Time: | 2019-02-13 18:45:06.385337 --------------------------------------------------------------------------------------------------------- Deletion Log Directory: | /var/log/ibm/csm/db/csm_db_history_delete.log --------------------------------------------------------------------------------------------------------- DB Name: | csmdb DB User Name: | postgres Script User Name: | root Thread Count: | 10 --------------------------------------------------------------------------------------------------------- [INFO] Processing Table csm_allocation_state_history | User Ct (time(mins)): 2880 | Act DB Ct: 0 [INFO] Processing Table csm_config_history | User Ct (time(mins)): 2880 | Act DB Ct: 0 [INFO] Processing Table csm_allocation_history | User Ct (time(mins)): 2880 | Act DB Ct: 0 [INFO] Processing Table csm_allocation_node_history | User Ct (time(mins)): 2880 | Act DB Ct: 0 [INFO] Processing Table csm_db_schema_version_history | User Ct (time(mins)): 2880 | Act DB Ct: 0 [INFO] Processing Table csm_diag_result_history | User Ct (time(mins)): 2880 | Act DB Ct: 0 [INFO] Processing Table csm_diag_run_history | User Ct (time(mins)): 2880 | Act DB Ct: 0 [INFO] Processing Table csm_dimm_history | User Ct (time(mins)): 2880 | Act DB Ct: 0 [INFO] Processing Table csm_gpu_history | User Ct (time(mins)): 2880 | Act DB Ct: 0 [INFO] Processing Table csm_hca_history | User Ct (time(mins)): 2880 | Act DB Ct: 0 [INFO] Processing Table csm_ib_cable_history | User Ct (time(mins)): 2880 | Act DB Ct: 0 [INFO] Processing Table csm_lv_history | User Ct (time(mins)): 2880 | Act DB Ct: 0 [INFO] Processing Table csm_lv_update_history | User Ct (time(mins)): 2880 | Act DB Ct: 0 [INFO] Processing Table csm_node_history | User Ct (time(mins)): 2880 | Act DB Ct: 0 [INFO] Processing Table csm_node_state_history | User Ct (time(mins)): 2880 | Act DB Ct: 0 [INFO] Processing Table csm_processor_socket_history | User Ct (time(mins)): 2880 | Act DB Ct: 0 [INFO] Processing Table csm_ssd_history | User Ct (time(mins)): 2880 | Act DB Ct: 0 [INFO] Processing Table csm_ssd_wear_history | User Ct (time(mins)): 2880 | Act DB Ct: 0 [INFO] Processing Table csm_step_history | User Ct (time(mins)): 2880 | Act DB Ct: 0 [INFO] Processing Table csm_step_node_history | User Ct (time(mins)): 2880 | Act DB Ct: 0 [INFO] Processing Table csm_switch_history | User Ct (time(mins)): 2880 | Act DB Ct: 0 [INFO] Processing Table csm_switch_inventory_history | User Ct (time(mins)): 2880 | Act DB Ct: 0 [INFO] Processing Table csm_vg_history | User Ct (time(mins)): 2880 | Act DB Ct: 0 [INFO] Processing Table csm_vg_ssd_history | User Ct (time(mins)): 2880 | Act DB Ct: 0 [INFO] Processing Table csm_ras_event_action | User Ct (time(mins)): 2880 | Act DB Ct: 0 --------------------------------------------------------------------------------------------------------- End Script Time: | 2019-02-13 18:45:06.432052 Total Process Time: | 0:00:00.046715 --------------------------------------------------------------------------------------------------------- Finish CSM DB deletion script process ---------------------------------------------------------------------------------------------------------If a user specifies a non related DB in the system, unrelated user name, or if there are issues connecting to the DB server a message will display.
[root@c650mnp02 db]# /opt/ibm/csm/db/csm_db_history_delete.py -d csmdb -n 1 --------------------------------------------------------------------------------------------------------- Welcome to the CSM DB deletion of history table records script --------------------------------------------------------------------------------------------------------- Start Script Time: | 2019-02-13 18:48:43.727626 --------------------------------------------------------------------------------------------------------- Deletion Log Directory: | /var/log/ibm/csm/db/csm_db_history_delete.log --------------------------------------------------------------------------------------------------------- DB Name: | csmdb DB User Name: | postgres Script User Name: | root Thread Count: | 10 --------------------------------------------------------------------------------------------------------- [CRITICAL] Unable to connect to local database. [CRITICAL] Unable to connect to local database. [CRITICAL] Unable to connect to local database. [CRITICAL] Unable to connect to local database. [CRITICAL] Unable to connect to local database. [CRITICAL] Unable to connect to local database. [CRITICAL] Unable to connect to local database. [CRITICAL] Unable to connect to local database. [CRITICAL] Unable to connect to local database. [CRITICAL] Unable to connect to local database. [CRITICAL] Unable to connect to local database. [CRITICAL] Unable to connect to local database. [CRITICAL] Unable to connect to local database. [CRITICAL] Unable to connect to local database. [CRITICAL] Unable to connect to local database. [CRITICAL] Unable to connect to local database. [CRITICAL] Unable to connect to local database. [CRITICAL] Unable to connect to local database. [CRITICAL] Unable to connect to local database. [CRITICAL] Unable to connect to local database. [CRITICAL] Unable to connect to local database. [CRITICAL] Unable to connect to local database. [CRITICAL] Unable to connect to local database. [CRITICAL] Unable to connect to local database. [CRITICAL] Unable to connect to local database. --------------------------------------------------------------------------------------------------------- End Script Time: | 2019-02-13 18:48:43.771443 Total Process Time: | 0:00:00.043817 --------------------------------------------------------------------------------------------------------- Finish CSM DB deletion script process ---------------------------------------------------------------------------------------------------------The
csm_db_history_delete.pyscript (when called manually) will delete history records which have been archived with a archive_history_timestamp. Records in the history table that do not have an archived_history_timestamp will remain in the system until it has been archived.Note
Directory: The scripts logging information will be in a specified directory.
The history table delete log file will be in a .log file format and in the default directory:
/var/log/ibm/csm/db/csm_db_history_delete.logUsing csm_db_schema_version_upgrade_19_0.sh¶
Important
Prior steps before migrating to the newest DB schema version.
- Stop all CSM daemons
- Run a cold backup of the csmdb or specified DB (csm_db_backup_script_v1.sh)
- Install the newest RPMs
- Run the csm_db_schema_version_upgrade_19_0.sh
- Start CSM daemons
Attention
To migrate the CSM database from
15.0, 15.1, 16.0, 16.1, 16.2, 17.0, or 18.0to the newest schema version/opt/ibm/csm/db/csm_db_schema_version_upgrade_19_0.sh <my_db_name>Note
The
csm_db_schema_version_upgrade_19_0.shscript creates a log file:/var/log/ibm/csm/csm_db_schema_upgrade_script.logThis script upgrades the CSM (or other specified) DB to the newest schema version (19.0).The script has the ability to alter tables, field types, indexes, triggers, functions, and any other relevant DB updates or requests. The script will only modify or add specificfields to the database and never eliminating certain fields.Note
For a quick overview of the script functionality:
/opt/ibm/csm/db/ csm_db_schema_version.sh –h /opt/ibm/csm/db/ csm_db_schema_version.sh --help If the script is ran without any options, then the usage function is displayed.Usage Overview¶
If a database name is not present then the usage message will appear with an
[Error ]message which is included below.-bash-4.2$ ./csm_db_schema_version_upgrade_19_0.sh -h ------------------------------------------------------------------------------------------------------------------------ [Start ] Welcome to CSM database schema version upgrade schema script. ------------------------------------------------------------------------------------------------------------------------ [Info ] Log Dir: /var/log/ibm/csm/db/csm_db_schema_upgrade_script.log [Error ] Please specify DB name ------------------------------------------------------------------------------------------------------------------------ [Info ] csm_db_schema_version_upgrade.sh : Load CSM DB upgrade schema file [Usage ] csm_db_schema_version_upgrade.sh : csm_db_schema_version_upgrade.sh [DBNAME] ------------------------------------------------------------------------------------------------------------------------ Argument | DB Name | Description -----------------|-----------|------------------------------------------------------------------------------------------ script_name | [db_name] | Imports sql upgrades to csm db table(s) (appends) | | fields, indexes, functions, triggers, etc -----------------|-----------|------------------------------------------------------------------------------------------ ------------------------------------------------------------------------------------------------------------------------Upgrading CSM DB (manual process)¶
Note
To upgrade the CSM or specified DB:
/opt/ibm/csm/db/csm_db_schema_version_upgrade_19_0.sh <my_db_name> (where my_db_name is the name of your DB).Note
The script will check to see if the given DB name exists. If the database name does not exist, then it will exit with an error message.
Example (non DB existence):¶
-bash-4.2$ ./csm_db_schema_version_upgrade_19_0.sh csmdb ------------------------------------------------------------------------------------------------------------------------ [Start ] Welcome to CSM database schema version upgrate script. ------------------------------------------------------------------------------------------------------------------------ [Info ] Log Dir: /var/log/ibm/csm/db/csm_db_schema_upgrade_script.log [Error ] PostgreSQL may not be installed or DB: asdf may not exist. [Error ] Please check configuration settings or psql -l ------------------------------------------------------------------------------------------------------------------------Note
- The script will check for the existence of these files:
csm_db_schema_version_data.csvcsm_create_tables.sqlcsm_create_triggers.sqlWhen an upgrade process happens, the new RPM will consist of a new schema version csv, DB create tables file, and or create triggers/functions file to be loaded into a (completley new) DB.
Once these files have been updated then the migration script can be executed. There is a built in check that does a comparison againt the DB schema version and the associated files. (These are just a couple of the check processes that takes place)Note
The same error message will prompt if the csm_create_tables.sql and or csm_create_triggers.sql file(s) do not exist in the directory.
Example (non file existence):¶
-bash-4.2$ ./csm_db_schema_version_upgrade_19_0.sh csmdb ------------------------------------------------------------------------------------------------------------------------ [Start ] Welcome to CSM database schema version upgrate script. ------------------------------------------------------------------------------------------------------------------------ [Info ] Log Dir: /var/log/ibm/csm/db/csm_db_schema_upgrade_script.log [Info ] csmdb current_schema_version is running: 18.0 ------------------------------------------------------------------------------------------------------------------------ [Error ] Cannot perform action because the csm_db_schema_version_data.csv file does not exist. ------------------------------------------------------------------------------------------------------------------------Note
The second check makes sure the file exists and compares the actual SQL upgrade version to the hardcoded version number. If the criteria is met successfully, then the script will proceed. If the process fails, then an error message will prompt.
Example (non compatible migration):¶
-bash-4.2$ ./csm_db_schema_version_upgrade_19_0.sh csmdb ------------------------------------------------------------------------------------------------------------------------ [Start ] Welcome to CSM database schema version upgrate script. ------------------------------------------------------------------------------------------------------------------------ [Info ] Log Dir: /var/log/ibm/csm/db/csm_db_schema_upgrade_script.log [Info ] csmdb current_schema_version is running: 18.0 ------------------------------------------------------------------------------------------------------------------------ [Error ] Cannot perform action because not compatible. [Info ] Required: appropriate files in directory [Info ] csm_create_tables.sql file currently in the directory is: 18.0 (required version) 19.0 [Info ] csm_create_triggers.sql file currently in the directory is: 19.0 (required version) 19.0 [Info ] csm_db_schema_version_data.csv file currently in the directory is: 19.0 (required version) 19.0 [Info ] Please make sure you have the latest RPMs installed and latest DB files. ------------------------------------------------------------------------------------------------------------------------Note
If the user selects the
"n/no"option when prompted to migrate to the newest DB schema upgrade, then the program will exit with the message below.Example (user prompt execution with “n/no” option):¶
-bash-4.2$ ./csm_db_schema_version_upgrade_19_0.sh csmdb ------------------------------------------------------------------------------------------------------------------------ [Start ] Welcome to CSM database schema version upgrate script. ------------------------------------------------------------------------------------------------------------------------ [Info ] Log Dir: /var/log/ibm/csm/db/csm_db_schema_upgrade_script.log [Info ] csmdb current_schema_version is running: 18.0 ------------------------------------------------------------------------------------------------------------------------ [Warning ] This will migrate csmdb database to schema version 19.0. Do you want to continue [y/n]?: [Info ] User response: n [Error ] Migration session for DB: csmdb User response: ****(NO)**** not updated ------------------------------------------------------------------------------------------------------------------------Note
If the user selects the
"y/yes"option when prompted to migrate to the newest DB schema upgrade, then the program will begin execution. An additional section has been added to the migration script to update existing ras message types or to insert new cases. The user will have to specifyy/yesfor these changes orn/noto skip the process. If there are no changes to the RAS message types or no new cases then the information will be displayed accordingly.Example (user prompt execution with “y/yes” options for both):¶
-bash-4.2$ ./csm_db_schema_version_upgrade_19_0.sh csmdb ------------------------------------------------------------------------------------------------------------------------ [Start ] Welcome to CSM database schema version upgrade script. ------------------------------------------------------------------------------------------------------------------------ [Info ] Log Dir: /var/log/ibm/csm/db/csm_db_schema_upgrade_script.log [Info ] csmdb current_schema_version is running: 18.0 ------------------------------------------------------------------------------------------------------------------------ [Warning ] This will migrate csmdb database to schema version 18.0. Do you want to continue [y/n]?: [Info ] User response: y [Info ] csmdb migration process begin. ------------------------------------------------------------------------------------------------------------------------ [Info ] Migration from 18.0 to 19.0 [Complete] ------------------------------------------------------------------------------------------------------------------------ [Start ] Welcome to CSM database ras type automation script. ------------------------------------------------------------------------------------------------------------------------ [Info ] Log Dir: /var/log/ibm/csm/db/csm_db_ras_type_script.log [Info ] csm_ras_type_data.csv file exists [Warning ] This will load and or update csm_ras_type table data into csmdb database. Do you want to continue [y/n]? [Info ] User response: y [Info ] csm_ras_type record count before script execution: 760 [Info ] Record import count from csm_ras_type_data.csv: 760 [Info ] Record update count from csm_ras_type_data.csv: 0 [Info ] csm_ras_type live row count after script execution: 760 [Info ] csm_ras_type_audit live row count: 760 [Info ] Database: csmdb csv upload process complete for csm_ras_type table. ------------------------------------------------------------------------------------------------------------------------ [End ] Database: csmdb csv upload process complete for csm_ras_type table. ------------------------------------------------------------------------------------------------------------------------ [Complete] csmdb database schema update 19.0. ------------------------------------------------------------------------------------------------------------------------ [Timing ] 0:00:00:3.9694 ------------------------------------------------------------------------------------------------------------------------Example (user prompt execution with “y/yes” for the migration and “n/no” for the RAS section):¶
-bash-4.2$ ./csm_db_schema_version_upgrade_19_0.sh csmdb ------------------------------------------------------------------------------------------------------------------------ [Start ] Welcome to CSM database schema version upgrade script. ------------------------------------------------------------------------------------------------------------------------ [Info ] Log Dir: /var/log/ibm/csm/db/csm_db_schema_upgrade_script.log [Info ] csmdb current_schema_version is running: 18.0 [Info ] ------------------------------------------------------------------------------------------------------------- [Warning ] This will migrate csmdb database to schema version 19.0. Do you want to continue [y/n]?: [Info ] User response: y [Info ] csmdb migration process begin. [Info ] ------------------------------------------------------------------------------------------------------------- [Info ] Migration from 18.0 to 19.0 [Complete] ------------------------------------------------------------------------------------------------------------------------ [Start ] Welcome to CSM database ras type automation script. ------------------------------------------------------------------------------------------------------------------------ [Info ] Log Dir: /var/log/ibm/csm/db/csm_db_ras_type_script.log [Info ] csm_ras_type_data.csv file exists [Warning ] This will load and or update csm_ras_type table data into csmdb database. Do you want to continue [y/n]? [Info ] User response: n [Info ] Skipping the csm_ras_type table data import/update process ------------------------------------------------------------------------------------------------------------------------ [End ] Database: csmdb csv upload process complete for csm_ras_type table. ------------------------------------------------------------------------------------------------------------------------ [Complete] csmdb database schema update 19.0. ------------------------------------------------------------------------------------------------------------------------ [Timing ] 0:00:00:3.4347 ------------------------------------------------------------------------------------------------------------------------Attention
It is not recommended to select
n/nofor the RAS section during the migration script process. If this process does occur, then the RAS script can be ran alone by the system admin.To run the RAS script by itself please refer to link: csm_ras_type_script_sh
Note
If the migration script has already ran already or a new database has been created with the latest schema version of
18.0then this message will be prompted to the user.Running the script with existing newer version¶
-bash-4.2$ ./csm_db_schema_version_upgrade_19_0.sh csmdb ------------------------------------------------------------------------------------------------------------------------ [Start ] Welcome to CSM database schema version upgrade script. ------------------------------------------------------------------------------------------------------------------------ [Info ] Log Dir: /tmp/csm_db_schema_upgrade_script.log [Info ] ------------------------------------------------------------------------------------------------------------- [Info ] csmdb is currently running db schema version: 19.0 ------------------------------------------------------------------------------------------------------------------------Warning
If there are existing DB connections, then the migration script will prompt a message and the admin will have to kill connections before proceeding.
Hint
The csm_db_connections_script.sh script can be used with the –l option to quickly list the current connections. (Please see user guide or
–hfor usage function). This script has the ability to terminate user sessions based on pids, users, or a–fforce option will kill all connections if necessary. Once the connections are terminated then thecsm_db_schema_version_upgrade_19_0.shscript can be executed. The log message will display current connection of user, database name, connection count, and duration.Example (user prompt execution with “y/yes” option and existing DB connection(s)):¶
-bash-4.2$ ./csm_db_schema_version_upgrade_19_0.sh csmdb ------------------------------------------------------------------------------------------------------------------------ [Start ] Welcome to CSM database schema version upgrate script. ------------------------------------------------------------------------------------------------------------------------ [Info ] Log Dir: /tmp/csm_db_schema_upgrade_script.log [Info ] csmdb current_schema_version is running: 18.0 [Info ] ------------------------------------------------------------------------------------------------------------- [Error ] csmdb has existing connection(s) to the database. [Error ] User: csmdb has 1 connection(s) [Info ] See log file for connection details ------------------------------------------------------------------------------------------------------------------------Running the script with older schema versions¶
Attention
It is possible to migrate older database versions to the latest schema release (ex. 19.0). Supporting databased include version 15.0, 15.1, 16.0, 16.1, 16.2, 17.0, and 18.0. The migration script will check previous versions and update accordingly. This script only supports bringing a previous version to the latest version, so if the current database version is at 15.0 then it will migrate to 19.0.
-bash-4.2$ ./csm_db_schema_version_upgrade_19_0.sh csmdb ------------------------------------------------------------------------------------------------------------------------ [Start ] Welcome to CSM database schema version upgrade script. ------------------------------------------------------------------------------------------------------------------------ [Info ] Log Dir: /var/log/ibm/csm/db/csm_db_schema_upgrade_script.log [Info ] csmdb current_schema_version is running: 15.0 [Info ] ------------------------------------------------------------------------------------------------------------- [Info ] There are critical migration steps needed to get to the latest schema version: 19.0 [Info ] These include versions 15.1, 16.0, 16.1, 16.2, 17.0, and 18.0 [Warning ] Do you want to continue [y/n]?: [Info ] User response: y [Info ] csmdb migration process begin. [Info ] ------------------------------------------------------------------------------------------------------------- [Info ] Migration from 15.0 to 18.0 [Complete] [Info ] ------------------------------------------------------------------------------------------------------------- [Info ] Migration from 18.0 to 19.0 [Complete] ------------------------------------------------------------------------------------------------------------------------ [Start ] Welcome to CSM database ras type automation script. ------------------------------------------------------------------------------------------------------------------------ [Info ] Log Dir: /var/log/ibm/csm/db/csm_db_ras_type_script.log [Info ] csm_ras_type_data.csv file exists [Warning ] This will load and or update csm_ras_type table data into csmdb database. Do you want to continue [y/n]? [Info ] User response: y [Info ] csm_ras_type record count before script execution: 760 [Info ] Record import count from csm_ras_type_data.csv: 760 [Info ] Record update count from csm_ras_type_data.csv: 0 [Info ] csm_ras_type live row count after script execution: 760 [Info ] csm_ras_type_audit live row count: 760 ------------------------------------------------------------------------------------------------------------------------ [End ] Database: csmdb csv upload process complete for csm_ras_type table. ------------------------------------------------------------------------------------------------------------------------ [Complete] csmdb database schema update 19.0. ------------------------------------------------------------------------------------------------------------------------ [Timing ] 0:00:00:3.2980 ------------------------------------------------------------------------------------------------------------------------Using csm_db_script.sh¶
Note
For a quick overview of the script functionality:
/opt/ibm/csm/db/csm_db_script.sh –h /opt/ibm/csm/db/csm_db_script.sh --help This help command <-h, --help> specifies each of the options available to use.Usage Overview¶
A new DB set up <default db> Command Result running the script with no options ./csm_db_script.sh This will create a default db with tables and populated data <specified by user or db admin> running the script with –x, –nodata ./csm_db_script.sh –x ./csm_db_script.sh –nodata This will create a default db with tables and no populated data
A new DB set up <new user db> Command Result running the script with –n, –newdb ./csm_db_script.sh -n <my_db_name> ./csm_db_script.sh –newdb <my_db_name> This will create a new db with tables and populated data. running the script with –n, –newdb, -x, –nodata ./csm_db_script.sh -n <my_db_name> –x ./csm_db_script.sh –newdb <my_db_name> –nodata This will create a new db with tables and no populated data.
If a DB already exists Command Result Drop DB totally ./csm_db_script.sh -d <my_db_name> ./csm_db_script.sh –delete <my_db_name> This will totally remove the DB from the system Drop only the existing CSM DB tables ./csm_db_script.sh -e <my_db_name> ./csm_db_script.sh –eliminatetables <my_db_name> This will only drop the specified CSM DB tables. <useful if integrated within another DB <e.x. “XCATDB”> Force overwrite of existing DB. ./csm_db_script.sh -f <my_db_name> ./csm_db_script.sh –force <my_db_name> This will totally drop the existing tables in the DB and recreate them with populated table data. Force overwrite of existing DB. ./csm_db_script.sh -f <my_db_name> –x ./csm_db_script.sh –force <my_db_name> –nodata This will totally drop the existing tables in the DB and recreate them without table data. Remove just the data from all the tables in the DB ./csm_db_script.sh -r <my_db_name> ./csm_db_script.sh –removetabledata <my_db_name> This will totally remove all data from all the tables within the DB. Example (usage)¶
-bash-4.2$ ./csm_db_script.sh -h ------------------------------------------------------------------------------------------------------------------------ [Start ] Welcome to CSM database automation script. [Info ] Log Dir: /tmp/csm_db_script.log ----------------------------------------------------------------------------------------------------------------- [Info ] csm_db_script.sh : CSM database creation script with additional features [Usage] csm_db_script.sh : [OPTION]... [DBNAME]... [OPTION] ----------------------------------------------------------------------------------------------------------------- [Options] -----------------------|-----------|----------------------------------------------------------------------------- Argument | DB Name | Description -----------------------|-----------|----------------------------------------------------------------------------- -x, --nodata | [DEFAULT] | creates database with tables and does not pre populate table data | [db_name] | this can also be used with the -f --force, -n --newdb option when | | recreating a DB. This should follow the specified DB name -d, --delete | [db_name] | totally removes the database from the system -e, --eliminatetables| [db_name] | drops CSM tables from the database -f, --force | [db_name] | drops the existing tables in the DB, recreates and populates with table data -n, --newdb | [db_name] | creates a new database with tables and populated data -r, --removetabledata| [db_name] | removes data from all database tables -h, --help | | help -----------------------|-----------|----------------------------------------------------------------------------- [Examples] ----------------------------------------------------------------------------------------------------------------- [DEFAULT] csm_db_script.sh | | [DEFAULT] csm_db_script.sh -x, --nodata | | csm_db_script.sh -d, --delete | [DBNAME] | csm_db_script.sh -e, --eliminatetables | [DBNAME] | csm_db_script.sh -f, --force | [DBNAME] | csm_db_script.sh -f, --force | [DBNAME] | -x, --nodata csm_db_script.sh -n, --newdb | [DBNAME] | csm_db_script.sh -n, --newdb | [DBNAME] | -x, --nodata csm_db_script.sh -r, --removetabledata | [DBNAME] | csm_db_script.sh -h, --help | | -----------------------------------------------------------------------------------------------------------------Note
Setting up or creating a new DB <manually>
To create your own DB¶
/opt/ibm/csm/db/db_script.sh –n <my_db_name> /opt/ibm/csm/db/db_script.sh --newdb <my_db_name> By default if no DB name is specified, then the script will create a DB called csmdb.Example (successful DB creation):¶
$ /opt/ibm/csm/db/csm_db_script.sh ------------------------------------------------------------------------------------------------------ [Start ] Welcome to CSM database automation script. [Info ] Log Dir: /var/log/ibm/csm/db/csm_db_script.log [Info ] PostgreSQL is installed [Info ] csmdb database user: csmdb already exists [Complete] csmdb database created. [Complete] csmdb database tables created. [Complete] csmdb database functions and triggers created. [Complete] csmdb table data loaded successfully into csm_db_schema_version [Complete] csmdb table data loaded successfully into csm_ras_type [Info ] csmdb DB schema version <19.0> ------------------------------------------------------------------------------------------------------Note
The script checks to see if the given name exists. If the database does not exist, then it will be created. If the database already exists, then the script prompts an error message indicating a database with this name already exists and exits the program.
Example (DB already exists)¶
$ /opt/ibm/csm/db/csm_db_script.sh ------------------------------------------------------------------------------------------------------ [Start ] Welcome to CSM database automation script. [Info ] Log Dir: /var/log/ibm/csm/db/csm_db_script.log [Info ] PostgreSQL is installed [Error ] Cannot perform action because the csmdb database already exists. Exiting. ------------------------------------------------------------------------------------------------------
- The script automatically populates data in specified tables using csv files.
For example, ras message type data, into the ras message type table. If a user does not want to populate these tables, then they should indicate a -x, --nodata in the command line during the initial setup process. /opt/ibm/csm/db/csm_db_script.sh -x /opt/ibm/csm/db/csm_db_script.sh --nodataExample (Default DB creation without loaded data option)¶
$ /opt/ibm/csm/db/csm_db_script.sh –x ------------------------------------------------------------------------------------------------------ [Start ] Welcome to CSM database automation script. [Info ] PostgreSQL is installed [Info ] Log Dir: /var/log/ibm/csm/db/csm_db_script.log [Info ] csmdb database user: csmdb already exists [Complete] csmdb database created. [Complete] csmdb database tables created. [Complete] csmdb database functions and triggers created. [Info ] csmdb skipping data load process. <----------[when running the -x, --nodata option] [Complete] csmdb initialized csm_db_schema_version data [Info ] csmdb DB schema version <19.0> ------------------------------------------------------------------------------------------------------Existing DB Options¶
Note
There are some other features in this script that will assist users in a “clean-up” process. If the database already exists, then these actions will work.
- Delete the database
/opt/ibm/csm/db/csm_db_script.sh –d <my_db_name> /opt/ibm/csm/db/csm_db_script.sh --delete <my_db_name>Example (Delete existing DB)¶
$ /opt/ibm/csm/db/csm_db_script.sh –d csmdb ------------------------------------------------------------------------------------------------------ [Start ] Welcome to CSM database automation script. [Info ] Log Dir: /var/log/ibm/csm/db/csm_db_script.log [Info ] PostgreSQL is installed [Info ] This will drop csmdb database including all tables and data. Do you want to continue [y/n]?y [Complete] csmdb database deleted ------------------------------------------------------------------------------------------------------
- Remove just data from all the tables
/opt/ibm/csm/db/csm_db_script.sh –r <my_db_name> /opt/ibm/csm/db/csm_db_script.sh --removetabledata <my_db_name>Example (Remove data from DB tables)¶
$ /opt/ibm/csm/db/csm_db_script.sh –r csmdb ------------------------------------------------------------------------------------------------------ [Start ] Welcome to CSM database automation script. [Info ] Log Dir: /var/log/ibm/csm/db/csm_db_script.log [Info ] PostgreSQL is installed [Complete] csmdb database data deleted from all tables excluding csm_schema_version and csm_db_schema_version_history tables ------------------------------------------------------------------------------------------------------
- Force a total overwrite of the database <drops tables and recreates them>.
/opt/ibm/csm/db/csm_db_script.sh –f <my_db_name> /opt/ibm/csm/db/csm_db_script.sh --force <my_db_name> (which auto populates table data).Example (Force DB receation)¶
$ /opt/ibm/csm/db/csm_db_script.sh –f csmdb ------------------------------------------------------------------------------------------------------ [Start ] Welcome to CSM database automation script. [Info ] Log Dir: /var/log/ibm/csm/db/csm_db_script.log [Info ] PostgreSQL is installed [Info ] csmdb database user: csmdb already exists [Complete] csmdb database tables and triggers dropped [Complete] csmdb database functions dropped [Complete] csmdb database tables recreated. [Complete] csmdb database functions and triggers recreated. [Complete] csmdb table data loaded successfully into csm_db_schema_version [Complete] csmdb table data loaded successfully into csm_ras_type [Info ] csmdb DB schema version <19.0> ------------------------------------------------------------------------------------------------------4. Force a total overwrite of the database <drops tables and recreates them without prepopulated data>.
/opt/ibm/csm/db/csm_db_script.sh –f <my_db_name> -x /opt/ibm/csm/db/csm_db_script.sh --force <my_db_name --nodata (which does not populate table data).Example (Force DB recreation without preloaded table data)¶
$ /opt/ibm/csm/db/csm_db_script.sh –f csmdb –x ------------------------------------------------------------------------------------------------------ [Start ] Welcome to CSM database automation script. [Info ] Log Dir: /var/log/ibm/csm/db/csm_db_script.log [Info ] PostgreSQL is installed [Info ] csmdb database user: csmdb already exists [Complete] csmdb database tables and triggers dropped [Complete] csmdb database functions dropped [Complete] csmdb database tables recreated. [Complete] csmdb database functions and triggers recreated. [Complete] csmdb skipping data load process. [Complete] csmdb table data loaded successfully into csm_db_schema_version [Info ] csmdb DB schema version <19.0> ------------------------------------------------------------------------------------------------------CSMDB user info.¶
5. The
"csmdb"user will remain in the system unless an admin manually deletes this option. If the user has to be deleted for any reason the Admin can run this command inside the psql postgres DB connection.DROP USER csmdb. If any current database are running with this user, then the user will get a response similar to the example belowERROR: database "csmdb" is being accessed by other users DETAIL: There is 1 other session using the database.Warning
It is not recommended to delete the csmdb user.
If the process has to be done manually then the admin can run these commands as logged in a postgres super user.Manual process As root user log into postgres:su – postgres psql -t -q -U postgres -d postgres -c "DROP USER csmdb;" psql -t -q -U postgres -d postgres -c "CREATE USER csmdb;"Note
The command below can be executed if specific privileges are needed.
psql -t -q -U postgres -d postgres -c "GRANT SELECT, INSERT, UPDATE, DELETE ON ALL TABLES IN SCHEMA public TO csmdb"Note
If admin wants to change the ownership of the DB to postgres then use the command below.
ALTER DATABASE csmdb OWNER TO postgres ALTER DATABASE csmdb OWNER TO csmdbThe automated DB script will check the existence of the DB user. If the user is already created then the process will be skipped.Please see the log file for details:
/var/log/ibm/csm/csm_db_script.logUsing csm_db_stats.sh script¶
This script will gather statistical information related to the CSM DB which includes, table data activity, index related information, and table lock monitoring, CSM DB schema version, DB connections stats query, DB user stats query, and PostgreSQL version installed .
Note
For a quick overview of the script functionality,
/opt/ibm/csm/db/csm_db_stats.sh –h /opt/ibm/csm/db/csm_db_stats.sh --help This help command <-h, --help> will specify each of the options available to use.The
csm_db_stats.shscript creates a log file for each query executed. (Please see the log file for details):/var/log/ibm/csm/csm_db_stats.logUsage Overview¶
Options Command Result Table data activity ./csm_db_stats.sh –t <my_db_name> ./csm_db_stats.sh –tableinfo <my_db_name> see details below Index related information ./csm_db_stats.sh –i <my_db_name> ./csm_db_stats.sh –indexinfo <my_db_name> see details below Index analysis information ./csm_db_stats.sh –x <my_db_name> ./csm_db_stats.sh –indexanalysis <my_db_name> see details below Table Locking Monitoring ./csm_db_stats.sh –l <my_db_name> ./csm_db_stats.sh –lockinfo <my_db_name> see details below Schema Version Query ./csm_db_stats.sh –s <my_db_name> ./csm_db_stats.sh –schemaversion <my_db_name> see details below DB connections stats Query ./csm_db_stats.sh –c <my_db_name> ./csm_db_stats.sh –connectionsdb <my_db_name> see details below DB user stats query ./csm_db_stats.sh –u <my_db_name> ./csm_db_stats.sh –usernamedb <my_db_name> see details below PostgreSQL Version Installed ./csm_db_stats.sh -v csmdb ./csm_db_stats.sh –postgresqlversion csmdb see details below DB Archiving Stats ./csm_db_stats.sh -a csmdb ./csm_db_stats.sh –archivecount csmdb see details below –help ./csm_db_stats.sh see details below Example (usage)¶
-bash-4.2$ ./csm_db_stats.sh -h ------------------------------------------------------------------------------------------------------------------------ [Start ] Welcome to CSM datatbase automation stats script. ------------------------------------------------------------------------------------------------------------------------ [Info ] Log Dir: /var/log/ibm/csm/db/csm_db_stats.log ------------------------------------------------------------------------------------------------------------------------ [Info ] csm_db_stats.sh : List/Kill database user sessions [Usage] csm_db_stats.sh : [OPTION]... [DBNAME] ------------------------------------------------------------------------------------------------------------------------ Argument | DB Name | Description -------------------------|-----------|---------------------------------------------------------------------------------- -t, --tableinfo | [db_name] | Populates Database Table Stats: | | Live Row Count, Inserts, Updates, Deletes, and Table Size -i, --indexinfo | [db_name] | Populates Database Index Stats: | | tablename, indexname, num_rows, tbl_size, ix_size, uk, | | num_scans, tpls_read, tpls_fetched -x, --indexanalysis | [db_name] | Displays the index usage analysis -l, --lockinfo | [db_name] | Displays any locks that might be happening within the DB -s, --schemaversion | [db_name] | Displays the current CSM DB version -c, --connectionsdb | [db_name] | Displays the current DB connections -u, --usernamedb | [db_name] | Displays the current DB user names and privileges -v, --postgresqlversion | [db_name] | Displays the current version of PostgreSQL installed | | along with environment details -a, --archivecount | [db_name] | Displays the archived and non archive record counts -d, --deletecount | [db_name] | Displays the total record count based on time interval -k, --vacuumstats | [db_name] | Displays the DB vacuum statistics -h, --help | | help -------------------------|-----------|---------------------------------------------------------------------------------- [Examples] ------------------------------------------------------------------------------------------------------------------------ csm_db_stats.sh -t, --tableinfo | [dbname] | | Database table stats csm_db_stats.sh -i, --indexinfo | [dbname] | | Database index stats csm_db_stats.sh -x, --indexanalysisinfo | [dbname] | | Database index usage analysis stats csm_db_stats.sh -l, --lockinfo | [dbname] | | Database lock stats csm_db_stats.sh -s, --schemaversion | [dbname] | | Database schema version (CSM_DB only) csm_db_stats.sh -c, --connectionsdb | [dbname] | | Database connections stats csm_db_stats.sh -u, --usernamedb | [dbname] | | Database user stats csm_db_stats.sh -v, --postgresqlversion | [dbname] | | Database (PostgreSQL) version csm_db_stats.sh -a, --archivecount | [dbname] | | Database archive stats csm_db_stats.sh -d, --deletecount | [dbname] | [time] | Database delete count stats csm_db_stats.sh -k, --vacuumstats | [dbname] | | Database vacuum stats csm_db_stats.sh -h, --help | [dbname] | | Help menu ------------------------------------------------------------------------------------------------------------------------1. Table data activity¶
/opt/ibm/csm/db/csm_db_stats.sh –t <my_db_name> /opt/ibm/csm/db/csm_db_stats.sh --tableinfo <my_db_name>Example (Query details)¶
Column_Name Description tablenametable name live_row_countcurrent row count in the CSM_DB insert_countnumber of rows inserted into each of the tables update_countnumber of rows updated in each of the tables delete_countnumber of rows deleted in each of the tables table_sizetable size Note
This query will display information related to the CSM DB tables (or other specified DB). The query will display results based on if the insert, update, and delete count is >
0. If there is no data in a particular table it will be omitted from the results.Example (DB Table info.)¶
-bash-4.2$ ./csm_db_stats.sh -t csmdb ------------------------------------------------------------------------------------------------------------------------ [Start ] Welcome to CSM datatbase automation stats script. ------------------------------------------------------------------------------------------------------------------------ [Info ] Log Dir: /var/log/ibm/csm/db/csm_db_stats.log ------------------------------------------------------------------------------------------------------------------------ relname | live_row_count | insert_count | update_count | delete_count | dead_tuples | table_size -----------------------+----------------+--------------+--------------+--------------+-------------+------------ csm_db_schema_version | 1 | 1 | 0 | 0 | 0 | 8192 bytes csm_ras_type | 744 | 744 | 0 | 0 | 0 | 112 kB csm_ras_type_audit | 744 | 744 | 0 | 0 | 0 | 128 kB (3 rows) ------------------------------------------------------------------------------------------------------------------------3. Index Analysis Usage Information¶
/opt/ibm/csm/db/csm_db_stats.sh –x <my_db_name> /opt/ibm/csm/db/csm_db_stats.sh --indexanalysis <my_db_name>Example (Query details)¶
Column_Name Description relnametable name too_much_seqcase when seq_scan - idx_scan > 0 caseIf Missing Index or is Ok rel_sizeOID of a table, index returns the on-disk size in bytes. seq_scanNumber of sequential scans initiated on this table. idx_scanNumber of index scans initiated on this index Note
This query checks if there are more sequence scans being performed instead of index scans. Results will be displayed if the
relname,too_much_seq,case,rel_size,seq_scan, andidx_scan. This query helps analyze database.Example (Indexes Usage)¶
-bash-4.2$ ./csm_db_stats.sh -x csmdb ------------------------------------------------------------------------------------------------------------------------ [Start ] Welcome to CSM datatbase automation stats script. ------------------------------------------------------------------------------------------------------------------------ [Info ] Log Dir: /var/log/ibm/csm/db/csm_db_stats.log ------------------------------------------------------------------------------------------------------------------------ relname | too_much_seq | case | rel_size | seq_scan | idx_scan ------------------------------+--------------+----------------+-------------+----------+---------- csm_step_node | 16280094 | Missing Index? | 245760 | 17438931 | 1158837 csm_allocation_history | 3061025 | Missing Index? | 57475072 | 3061787 | 762 csm_allocation_state_history | 3276 | Missing Index? | 35962880 | 54096 | 50820 csm_vg_history | 1751 | Missing Index? | 933888 | 1755 | 4 csm_vg_ssd_history | 1751 | Missing Index? | 819200 | 1755 | 4 csm_ssd_history | 1749 | Missing Index? | 1613824 | 1755 | 6 csm_dimm_history | 1652 | Missing Index? | 13983744 | 1758 | 106 csm_gpu_history | 1645 | Missing Index? | 24076288 | 1756 | 111 csm_hca_history | 1643 | Missing Index? | 8167424 | 1754 | 111 csm_ras_event_action | 1549 | Missing Index? | 263143424 | 1854 | 305 csm_node_state_history | 401 | Missing Index? | 78413824 | 821 | 420 csm_node_history | -31382 | OK | 336330752 | 879 | 32261 csm_ras_type_audit | -97091 | OK | 98304 | 793419 | 890510 csm_step_history | -227520 | OK | 342327296 | 880 | 228400 csm_vg_ssd | -356574 | OK | 704512 | 125588 | 482162 csm_vg | -403370 | OK | 729088 | 86577 | 489947 csm_hca | -547463 | OK | 1122304 | 1 | 547464 csm_ras_type | -942966 | OK | 81920 | 23 | 942989 csm_ssd | -1242433 | OK | 1040384 | 85068 | 1327501 csm_step_node_history | -1280913 | OK | 2865987584 | 49335 | 1330248 csm_allocation_node_history | -1664023 | OK | 21430599680 | 887 | 1664910 csm_gpu | -2152044 | OK | 5996544 | 1 | 2152045 csm_dimm | -2239777 | OK | 7200768 | 118280 | 2358057 csm_allocation_node | -52187077 | OK | 319488 | 1727675 | 53914752 csm_node | -78859700 | OK | 2768896 | 127214 | 78986914 (25 rows) --------------------------------------------------------------------------------------------------4. Table Lock Monitoring¶
/opt/ibm/csm/db/csm_db_stats.sh –l <my_db_name> /opt/ibm/csm/db/csm_db_stats.sh --lockinfo <my_db_name>Example (Query details)¶
Column_Name Description blocked_pidProcess ID of the server process holding or awaiting this lock, or null if the lock is held by a prepared transaction. blocked_userThe user that is being blocked. current_or_recent_statement_in_blocking_processThe query statement that is displayed as a result. state_of_blocking_processCurrent overall state of this backend. blocking_durationEvaluates when the process begin and subtracts from the current time when the query began. blocking_pidProcess ID of this backend. blocking_userThe user that is blocking other transactions. blocked_statementThe query statement that is displayed as a result. blocked_durationEvaluates when the process begin and subtracts from the current time when the query began. Example (Lock Monitoring)¶
-bash-4.2$ ./csm_db_stats.sh -l csmdb ------------------------------------------------------------------------------------------------------------------------ [Start ] Welcome to CSM datatbase automation stats script. ------------------------------------------------------------------------------------------------------------------------ [Info ] Log Dir: /var/log/ibm/csm/db/csm_db_stats.log ------------------------------------------------------------------------------------------------------------------------ -[ RECORD 1 ]-----------------------------------+-------------------------------------------------------------- blocked_pid | 38351 blocked_user | postgres current_or_recent_statement_in_blocking_process | update csm_processor set status=’N’ where serial_number=3; state_of+blocking_process | active blocking_duration | 01:01:11.653697 blocking_pid | 34389 blocking_user | postgres blocked_statement | update csm_processor set status=’N’ where serial_number=3; blocked_duration | 00:01:09.048478 ------------------------------------------------------------------------------------------------------------------------Note
This query displays relevant information related to lock monitoring. It will display the current blocked and blocking rows affected along with each duration. A systems administrator can run the query and evaluate what is causing the results of a “hung” procedure and determine the possible issue.
5. DB schema Version Query¶
/opt/ibm/csm/db/csm_db_stats.sh –s <my_db_name> /opt/ibm/csm/db/csm_db_stats.sh --schemaversion <my_db_name>Example (Query details)¶
versionThis provides the current CSM DB version that is current being used. create_timeThis column indicated when the database was created. commentThis column indicates the “current version” as comment. Example (DB Schema Version)¶
-bash-4.2$ ./csm_db_stats.sh -s csmdb ------------------------------------------------------------------------------------------------------------------------ [Start ] Welcome to CSM datatbase automation stats script. ------------------------------------------------------------------------------------------------------------------------ [Info ] Log Dir: /var/log/ibm/csm/db/csm_db_stats.log ------------------------------------------------------------------------------------------------------------------------ -bash-4.2$ ./csm_db_stats.sh -s csmdb ------------------------------------------------------------------------------------- version | create_time | comment ---------+----------------------------+----------------- 17.0 | 2019-02-14 17:31:10.079585 | current_version (1 row) ------------------------------------------------------------------------------------------------------------------------Note
This query provides the current database version the system is running along with its creation time.
6. DB Connections with details¶
/opt/ibm/csm/db/./csm_db_stats.sh –c <my_db_name> /opt/ibm/csm/db/./csm_db_stats.sh --connectionsdb <my_db_name>Example (Query details)¶
pidProcess ID of this backend. dbnameName of the database this backend is connected to. usernameName of the user logged into this backend. backend_startTime when this process was started, i.e., when the client connected to the server. query_startTime when the currently active query was started, or if state is not active, when the last query was started. state_changeTime when the state was last changed. waitTrue if this backend is currently waiting on a lock. queryText of this backends most recent query. If state is active this field shows the currently executing query. In all other states, it shows the last query that was executed. Example (database connections)¶
-bash-4.2$ ./csm_db_stats.sh -c csmdb ------------------------------------------------------------------------------------------------------------------------ [Start ] Welcome to CSM datatbase automation stats script. ------------------------------------------------------------------------------------------------------------------------ [Info ] Log Dir: /var/log/ibm/csm/db/csm_db_stats.log ------------------------------------------------------------------------------------------------------------------------ pid | dbname | usename | backend_start | query_start | state_change | wait | query -------+--------+----------+----------------------------+----------------------------+----------------------------+------+--------------------------------- 61427 | xcatdb | xcatadm | 2017-11-01 13:42:53.931094 | 2017-11-02 10:15:04.617097 | 2017-11-02 10:15:04.617112 | f | DEALLOCATE | | | | | | | dbdpg_p17050_384531 61428 | xcatdb | xcatadm | 2017-11-01 13:42:53.932721 | 2017-11-02 10:15:04.616291 | 2017-11-02 10:15:04.616313 | f | SELECT 'DBD::Pg ping test' 55753 | csmdb | postgres | 2017-11-02 10:15:06.619898 | 2017-11-02 10:15:06.620889 | 2017-11-02 10:15:06.620891 | f | | | | | | | | SELECT pid,datname AS dbname, | | | | | | | usename,backend_start, q. | | | | | | |.uery_start, state_change, | | | | | | | waiting AS wait,query FROM pg. | | | | | | |._stat_activity; (3 rows) ------------------------------------------------------------------------------------------------------------------------Note
This query will display information about the database connections that are in use on the system. The pid (Process ID), database name, user name, backend start time, query start time, state change, waiting status, and query will display statistics about the current database activity.
7. PostgreSQL users with details¶
/opt/ibm/csm/db/./csm_db_stats.sh –u <my_db_name> /opt/ibm/csm/db/./csm_db_stats.sh --usernamedb <my_db_name>Example (Query details)¶
Column_Name Description rolnameRole name (t/f). rolsuperRole has superuser privileges (t/f). rolinheritRole automatically inherits privileges of roles it is a member of (t/f). rolcreateroleRole can create more roles (t/f). rolcreatedbRole can create databases (t/f). rolcatupdateRole can update system catalogs directly. (Even a superuser cannot do this unless this column is true) (t/f). rolcanloginRole can log in. That is, this role can be given as the initial session authorization identifier (t/f). rolreplicationRole is a replication role. That is, this role can initiate streaming replication and set/unset the system backup mode using pg_start_backup and pg_stop_backup (t/f). rolconnlimitFor roles that can log in, this sets maximum number of concurrent connections this role can make. -1 means no limit. rolpasswordNot the password (always reads as ****). rolvaliduntilPassword expiry time (only used for password authentication); null if no expiration. rolconfigRole-specific defaults for run-time configuration variables. oidID of role. Example (DB users with details)¶
-bash-4.2$ ./csm_db_stats.sh -u postgres ------------------------------------------------------------------------------------------------------------------------ [Start ] Welcome to CSM datatbase automation stats script. ------------------------------------------------------------------------------------------------------------------------ [Info ] Log Dir: /var/log/ibm/csm/db/csm_db_stats.log ------------------------------------------------------------------------------------------------------------------------ rolname | rolsuper | rolinherit | rolcreaterole | rolcreatedb | rolcatupdate | rolcanlogin | rolreplication | rolconnlimit | rolpassword | rolvaliduntil | rolconfig | oid ----------+----------+------------+---------------+-------------+--------------+-------------+----------------+--------------+-------------+---------------+-----------+-------- postgres | t | t | t | t | t | t | t | -1 | ******** | | | 10 xcatadm | f | t | f | f | f | t | f | -1 | ******** | | | 16385 root | f | t | f | f | f | t | f | -1 | ******** | | | 16386 csmdb | f | t | f | f | f | t | f | -1 | ******** | | | 704142 (4 rows) ------------------------------------------------------------------------------------------------------------------------Note
This query will display specific information related to the users that are currently in the postgres database. These fields will appear in the query: rolname, rolsuper, rolinherit, rolcreaterole, rolcreatedb, rolcatupdate, rolcanlogin, rolreplication, rolconnlimit, rolpassword, rolvaliduntil, rolconfig, and oid. See below for details.
8. PostgreSQL Version Installed¶
/opt/ibm/csm/db/./csm_db_stats.sh –v <my_db_name> /opt/ibm/csm/db/./csm_db_stats.sh --postgresqlversion <my_db_name>
Column_Name Description versionThis provides the current PostgreSQL installed on the system along with other environment details. Example (DB Schema Version)¶
-bash-4.2$ ./csm_db_stats.sh -v csmdb ------------------------------------------------------------------------------------------------------------------------ [Start ] Welcome to CSM datatbase automation stats script. ------------------------------------------------------------------------------------------------------------------------ [Info ] Log Dir: /var/log/ibm/csm/db/csm_db_stats.log ------------------------------------------------------------------------------------------------------------------------ version ------------------------------------------------------------------------------------------------- PostgreSQL 9.2.18 on powerpc64le-redhat-linux-gnu, compiled by gcc (GCC) 4.8.5 20150623 (Red Hat 4.8.5-9), 64-bit (1 row) ------------------------------------------------------------------------------------------------------------------------Note
This query provides the current version of PostgreSQL installed on the system along with environment details.
9. DB Archiving Stats¶
/opt/ibm/csm/db/./csm_db_stats.sh –a <my_db_name> /opt/ibm/csm/db/./csm_db_stats.sh --indexanalysis <my_db_name>Example (Query details)¶
Column_Name Description table_nameTable name. total_rowsTotal Rows in DB. not_archivedTotal rows not archived in the DB. archivedTotal rows archived in the DB. last_archive_timeLast archived process time. Warning
This query could take several minutes to execute depending on the total size of each table.
Example (DB archive count with details)¶
-bash-4.2$ ./csm_db_stats.sh -a csmdb ------------------------------------------------------------------------------------------------------------------------ [Start ] Welcome to CSM datatbase automation stats script. ------------------------------------------------------------------------------------------------------------------------ [Info ] Log Dir: /var/log/ibm/csm/db/csm_db_stats.log ------------------------------------------------------------------------------------------------------------------------ table_name | total_rows | not_archived | archived | last_archive_time -------------------------------+------------+--------------+----------+---------------------------- csm_allocation_history | 94022 | 0 | 94022 | 2018-10-09 16:00:01.912545 csm_allocation_node_history | 73044162 | 0 | 73044162 | 2018-10-09 16:00:02.06098 csm_allocation_state_history | 281711 | 0 | 281711 | 2018-10-09 16:01:03.685959 csm_config_history | 0 | 0 | 0 | csm_db_schema_version_history | 2 | 0 | 2 | 2018-10-03 10:38:45.294172 csm_diag_result_history | 12 | 0 | 12 | 2018-10-03 10:38:45.379335 csm_diag_run_history | 8 | 0 | 8 | 2018-10-03 10:38:45.464976 csm_dimm_history | 76074 | 0 | 76074 | 2018-10-03 10:38:45.550827 csm_gpu_history | 58773 | 0 | 58773 | 2018-10-03 10:38:47.486974 csm_hca_history | 23415 | 0 | 23415 | 2018-10-03 10:38:50.574223 csm_ib_cable_history | 0 | 0 | 0 | csm_lv_history | 0 | 0 | 0 | csm_lv_update_history | 0 | 0 | 0 | csm_node_history | 536195 | 0 | 536195 | 2018-10-09 14:10:40.423458 csm_node_state_history | 966991 | 0 | 966991 | 2018-10-09 15:30:40.886846 csm_processor_socket_history | 0 | 0 | 0 | csm_ras_event_action | 1115253 | 0 | 1115253 | 2018-10-09 15:30:50.514246 csm_ssd_history | 4723 | 0 | 4723 | 2018-10-03 10:39:47.963564 csm_ssd_wear_history | 0 | 0 | 0 | csm_step_history | 456080 | 0 | 456080 | 2018-10-09 16:01:05.797751 csm_step_node_history | 25536362 | 0 | 25536362 | 2018-10-09 16:01:06.216121 csm_switch_history | 0 | 0 | 0 | csm_switch_inventory_history | 0 | 0 | 0 | csm_vg_history | 4608 | 0 | 4608 | 2018-10-03 10:44:25.837201 csm_vg_ssd_history | 4608 | 0 | 4608 | 2018-10-03 10:44:26.047599 (25 rows) ------------------------------------------------------------------------------------------------------------------------Note
This query provides statistical information related to the DB archiving count and processing time.
10. DB Delete Count Stats¶
/opt/ibm/csm/db/./csm_db_stats.sh –d <my_db_name> <interval_time> (in minutes - example 43800 mins = 1 month) /opt/ibm/csm/db/./csm_db_stats.sh --deletecount <my_db_name> <interval_time>Example (Query details)¶
Column_Name Description Table NameTable name. Time intervalThe time (in mins.) of oldest records which to delete. Total RecordsReturns total records which would be delete. Warning
This query could take several minutes to execute depending on the total size of each table.
Example (DB record count delete estimator)¶
-bash-4.2$ ./csm_db_stats.sh -d csmdb 1 ------------------------------------------------------------------------------------------------------------------------ [Start ] Welcome to CSM datatbase automation stats script. ------------------------------------------------------------------------------------------------------------------------ [Info ] Log Dir: /var/log/ibm/csm/db/csm_db_stats.log ------------------------------------------------------------------------------------------------------------------------ [Info ] Table Name: | Time interval: | Total Records: ------------------------------------------------------------------------------------------------------------------------ [Info ] csm_allocation_history | 1 (mins) | 0 [Info ] csm_allocation_node_history | 1 (mins) | 0 [Info ] csm_allocation_state_history | 1 (mins) | 0 [Info ] csm_config_history | 1 (mins) | 0 [Info ] csm_db_schema_version_history | 1 (mins) | 0 [Info ] csm_diag_result_history | 1 (mins) | 0 [Info ] csm_diag_run_history | 1 (mins) | 0 [Info ] csm_dimm_history | 1 (mins) | 0 [Info ] csm_gpu_history | 1 (mins) | 0 [Info ] csm_hca_history | 1 (mins) | 0 [Info ] csm_ib_cable_history | 1 (mins) | 0 [Info ] csm_lv_history | 1 (mins) | 0 [Info ] csm_lv_update_history | 1 (mins) | 0 [Info ] csm_node_history | 1 (mins) | 0 [Info ] csm_node_state_history | 1 (mins) | 0 [Info ] csm_processor_socket_history | 1 (mins) | 0 [Info ] csm_ssd_history | 1 (mins) | 0 [Info ] csm_ssd_wear_history | 1 (mins) | 0 [Info ] csm_step_history | 1 (mins) | 0 [Info ] csm_step_node_history | 1 (mins) | 0 [Info ] csm_switch_history | 1 (mins) | 0 [Info ] csm_switch_inventory_history | 1 (mins) | 0 [Info ] csm_vg_history | 1 (mins) | 0 [Info ] csm_vg_ssd_history | 1 (mins) | 0 [Info ] csm_ras_event_action | 1 (mins) | 0 ------------------------------------------------------------------------------------------------------------------------Note
This query provides statistical information related to the DB deletion script count. It provides a system admin or analyst accurate information of the total records which would be deleted based on a specific time range.
If the user does not specify the time interval then an error message will display.
-bash-4.2$ ./csm_db_stats.sh -d csmdb ------------------------------------------------------------------------------------------------------------------------ [Start ] Welcome to CSM datatbase automation stats script. ------------------------------------------------------------------------------------------------------------------------ [Info ] Log Dir: /tmp/csm_db_stats.log ------------------------------------------------------------------------------------------------------------------------ [Error ] Please specify the time interval [Info ] Example: ./csm_db_stats.sh -d csmdb 1 [min(s)] ------------------------------------------------------------------------------------------------------------------------11. DB Vacuum Stats¶
/opt/ibm/csm/db/./csm_db_stats.sh –k <my_db_name> /opt/ibm/csm/db/./csm_db_stats.sh --vacuumstats <my_db_name>Example (Query details)¶
Column_Name Description table_nameTable name. last_vacuumLast time at which this table was manually vacuumed (not counting VACUUM FULL). last_autovacuumLast time at which this table was vacuumed by the autovacuum daemon. last_analyzeLast time at which this table was manually analyzed. last_autoanalyzeLast time at which this table was analyzed by the autovacuum daemon. Example (DB vacuum stats)¶
-bash-4.2$ ./csm_db_stats.sh -k bills_db ------------------------------------------------------------------------------------------------------------------------ [Start ] Welcome to CSM datatbase automation stats script. ------------------------------------------------------------------------------------------------------------------------ [Info ] Log Dir: /var/log/ibm/csm/db/csm_db_stats.log ------------------------------------------------------------------------------------------------------------------------ table_name | last_vacuum | last_autovacuum | last_analyze | last_autoanalyze -------------------------------+-------------------------------+-------------------------------+-------------------------------+------------------------------- csm_gpu_history | 2018-12-02 01:51:52.40607-05 | 2019-01-04 09:21:37.459804-05 | | 2019-01-04 09:03:08.694441-05 csm_step_node_history | 2018-12-02 01:51:44.219276-05 | 2018-11-03 21:28:09.828034-04 | | 2018-12-02 01:52:30.650538-05 csm_step | 2018-12-02 01:16:25.870369-05 | 2018-10-25 16:56:00.464431-04 | | 2018-10-25 16:56:00.4645-04 csm_step_history | 2018-12-02 01:16:25.855684-05 | 2018-11-04 02:45:05.236657-05 | | 2018-12-02 01:22:45.147226-05 csm_allocation_state_history | 2018-12-01 22:59:33.799716-05 | 2018-11-29 21:29:29.254385-05 | 2018-10-31 15:26:34.900721-04 | 2018-12-02 01:18:57.064656-05 csm_vg_ssd_history | 2018-12-02 01:52:00.202179-05 | | | csm_switch | 2018-12-02 01:52:00.334302-05 | | | csm_switch_history | 2018-12-02 04:52:17.664809-05 | | | csm_diag_run_history | 2018-12-02 00:06:47.725711-05 | | | csm_processor_socket_history | 2018-12-02 04:52:17.664267-05 | 2019-01-04 08:57:40.818141-05 | | 2019-01-04 08:51:11.275687-05 csm_node_state_history | 2018-12-11 08:38:59.515742-05 | 2018-11-30 04:46:26.791063-05 | 2018-10-31 15:32:35.631237-04 | 2018-12-02 01:20:09.060344-05 csm_ib_cable_history | 2018-12-02 01:52:00.333189-05 | | | csm_switch_inventory | 2018-12-02 01:52:00.334752-05 | | | csm_node_history | 2018-12-11 08:43:11.872734-05 | 2018-11-30 06:52:44.334165-05 | 2018-10-31 15:31:47.598393-04 | 2018-12-01 21:16:11.64458-05 csm_diag_result | 2018-12-02 04:52:15.50969-05 | | | csm_vg_history | 2018-12-02 01:52:00.201805-05 | | | csm_node | 2018-12-02 01:52:00.243946-05 | | | csm_lv_history | 2018-12-02 01:52:00.25459-05 | | | csm_hca_history | 2018-12-02 01:51:55.096052-05 | 2019-01-04 09:16:14.732882-05 | | 2019-01-04 09:17:45.783809-05 csm_ssd_history | 2018-12-02 01:52:00.179348-05 | 2019-01-04 09:18:52.69561-05 | | 2019-01-04 09:02:52.365255-05 csm_vg | 2018-12-02 01:52:00.255147-05 | | | csm_diag_run | 2018-12-02 00:06:47.753997-05 | | | csm_vg_ssd | 2018-12-02 01:52:00.255371-05 | | | csm_dimm_history | 2018-12-02 01:51:57.461387-05 | 2019-01-04 09:13:25.641405-05 | | 2019-01-04 08:53:14.499878-05 csm_gpu | 2018-12-02 04:52:15.507073-05 | | | csm_ssd_wear_history | 2018-12-02 01:52:00.179796-05 | | | csm_config | 2018-12-02 04:52:15.50911-05 | | | csm_ssd | 2018-12-02 04:52:15.472697-05 | | | csm_allocation_node | 2018-12-02 01:52:00.244288-05 | 2018-10-25 16:56:00.47555-04 | | 2018-10-25 16:56:00.475655-04 csm_allocation_node_history | 2018-12-02 00:06:47.71226-05 | 2018-11-03 08:15:52.870707-04 | | 2018-12-02 01:22:10.362188-05 csm_hca | 2018-12-02 04:52:15.507982-05 | | | csm_switch_inventory_history | 2018-12-02 01:52:00.333537-05 | | | csm_config_bucket | 2018-12-02 01:52:00.334076-05 | | | csm_processor_socket | 2018-12-02 04:52:15.506159-05 | | | csm_ras_type | 2018-12-13 14:29:01.272399-05 | 2018-12-13 14:48:46.295323-05 | | 2019-02-05 14:11:43.368311-05 csm_ib_cable | 2018-12-02 01:52:00.334527-05 | | | csm_dimm | 2018-12-02 04:52:15.508856-05 | | | 2018-10-25 16:52:00.289175-04 csm_db_schema_version_history | 2018-12-02 01:52:00.363837-05 | | | 2018-12-02 00:27:34.520137-05 csm_allocation_history | 2018-12-02 04:52:15.372503-05 | 2018-11-24 19:33:37.983472-05 | 2018-10-31 15:29:11.390241-04 | 2018-12-02 04:54:48.182816-05 csm_allocation | 2018-12-02 01:52:00.201378-05 | 2018-10-25 16:56:00.442126-04 | | 2018-10-25 16:56:00.442232-04 csm_lv_update_history | 2018-12-02 01:52:00.254908-05 | | | csm_config_history | 2018-12-02 01:52:00.333859-05 | | | csm_ras_event_action | 2018-12-02 08:16:49.327258-05 | 2018-12-13 16:28:03.802508-05 | | 2018-12-13 16:17:22.491009-05 csm_diag_result_history | 2018-12-02 00:06:47.754361-05 | | | csm_step_node | 2018-12-02 01:52:00.244617-05 | 2018-10-25 16:56:00.453388-04 | | 2018-10-25 16:56:00.453442-04 csm_ras_type_audit | 2018-12-13 11:39:26.292136-05 | 2018-12-13 16:13:05.113418-05 | | 2019-02-05 14:11:43.413383-05 csm_db_schema_version | 2018-12-02 04:52:15.45307-05 | | | csm_lv | 2018-12-02 04:52:15.509398-05 | | | (48 rows) ------------------------------------------------------------------------------------------------------------------------Using csm_ras_type_script.sh¶
This script is for importing or removing records in the csm_ras_type table. The csm_db_ras_type_script.sh creates a log file:
/var/log/ibm/csm/csm_db_ras_type_script.logNote
csm_ras_typetable is pre populated which, contains the description and details for each of the possible RAS event types. This may change over time and new message types can be imported into the table. The script is ran and a temp table is created and appends the csv file data with the current records in thecsm_ras_typetable. If any duplicate (key) values exist in the process, they will get dismissed and the rest of the records get imported. A total record count is displayed and logged, along with the after livecsm_ras_typecount and also for thecsm_ras_type_audittable.- A complete cleanse of the
csm_ras_typetable may also need to take place. If this step is necessary then the auto script can be ran with the–roption. A"y/n"prompt will display to the admins to ensure this execution is really what they want. If thenoption is selected then the process is aborted and results are logged accordingly.Usage Overview¶
/opt/ibm/csm/db/ csm_db_ras_type_script.sh –h /opt/ibm/csm/db/ csm_db_ras_type_script.sh --helpNote
This help command (
-h, --help) will specify each of the options available to use.Example (Usage)¶
-bash-4.2$ ./csm_db_ras_type_script.sh -h ------------------------------------------------------------------------------------------------------------------------ [Start ] Welcome to CSM datatbase ras type automation script. ------------------------------------------------------------------------------------------------------------------------ [Info ] Log Dir: /var/log/ibm/csm/db/csm_db_ras_type_script.log ------------------------------------------------------------------------------------------------------------------------ [Info ] csm_db_ras_type_script.sh : Load/Remove data from csm_ras_type table [Usage] csm_db_ras_type_script.sh : [OPTION]... [DBNAME]... [CSV_FILE] ------------------------------------------------------------------------------------------------------------------------ Argument | DB Name | Description -------------------------|-----------|---------------------------------------------------------------------------------- -l, --loaddata | [db_name] | Imports CSV data to csm_ras_type table (appends) | | Live Row Count, Inserts, Updates, Deletes, and Table Size -r, --removedata | [db_name] | Removes all records from the csm_ras_type table -h, --help | | help -------------------------|-----------|---------------------------------------------------------------------------------- [Examples] ------------------------------------------------------------------------------------------------------------------------ csm_db_ras_type_script.sh -l, --loaddata [dbname] | [csv_file_name] csm_db_ras_type_script.sh -r, --removedata [dbname] | csm_db_ras_type_script.sh -h, --help [dbname] | ------------------------------------------------------------------------------------------------------------------------Importing records into csm_ras_type table (manually)¶
- To import data to the
csm_ras_typetable:/opt/ibm/csm/db/csm_db_ras_type_script.sh –l my_db_name (where my_db_name is the name of your DB) and the csv_file_name. /opt/ibm/csm/db/csm_db_ras_type_script.sh --loaddata my_db_name (where my_db_name is the name of your DB) and the csv_file_name.Note
The script will check to see if the given name is available and if the database does not exist then it will exit with an error message.
Example (non DB existence):¶
-bash-4.2$ ./csm_db_ras_type_script.sh -l csmdb csm_ras_type_data.csv ------------------------------------------------------------------------------------------------------------------------ [Start ] Welcome to CSM datatbase ras type automation script. ------------------------------------------------------------------------------------------------------------------------ [Info ] Log Dir: /var/log/ibm/csm/db/csm_db_ras_type_script.log [Error ] PostgreSQL may not be installed or DB: bills_test_d may not exist. [Info ] Please check configuration settings or psql -l ------------------------------------------------------------------------------------------------------------------------Note
Make sure PostgreSQL is installed on the system.
Example (non csv_file_name existence):¶
-bash-4.2$ ./csm_db_ras_type_script.sh -l csmdb csm_ras_type_data_file.csv ------------------------------------------------------------------------------------------------------------------------ [Start ] Welcome to CSM datatbase ras type automation script. ------------------------------------------------------------------------------------------------------------------------ [Info ] Log Dir: /var/log/ibm/csm/db/csm_db_ras_type_script.log [Error ] File csm_ras_type_data_file.csv can not be located or doesnt exist [Info ] Please choose another file or check path ------------------------------------------------------------------------------------------------------------------------Note
Make sure the latest csv file exists in the appropriate working directory
Example (successful execution):¶
-bash-4.2$ ./csm_db_ras_type_script.sh -l csmdb csm_ras_type_data.csv ------------------------------------------------------------------------------------------------------------------------ [Start ] Welcome to CSM database ras type automation script. ------------------------------------------------------------------------------------------------------------------------ [Info ] Log Dir: /var/log/ibm/csm/db/csm_db_ras_type_script.log [Info ] csm_ras_type_data.csv file exists [Warning ] This will load and or update csm_ras_type table data into csmdb database. Do you want to continue [y/n]? [Info ] User response: y [Info ] csm_ras_type record count before script execution: 744 [Info ] Record import count from csm_ras_type_data.csv: 744 [Info ] Record update count from csm_ras_type_data.csv: 0 [Info ] csm_ras_type live row count after script execution: 744 [Info ] csm_ras_type_audit live row count: 744 [Info ] Database: csmdb csv upload process complete for csm_ras_type table. ------------------------------------------------------------------------------------------------------------------------ [End ] Database: bills_test_db csv upload process complete for csm_ras_type table. ------------------------------------------------------------------------------------------------------------------------Removing records from csm_ras_type table (manually)¶
- The script will remove records from the
csm_ras_typetable. The option (-r, --removedata) can be executed. A prompt message will appear and the admin has the ability to choose"y/n". Each of the logging message will be logged accordingly./opt/ibm/csm/db/csm_db_ras_type_script.sh –r my_db_name (where my_db_name is the name of your DB). Example (successful execution): -bash-4.2$ ./csm_db_ras_type_script.sh -r csmdb ------------------------------------------------------------------------------------------------------------------------ [Start ] Welcome to CSM database ras type automation script. ------------------------------------------------------------------------------------------------------------------------ [Info ] Log Dir: /var/log/ibm/csm/db/csm_db_ras_type_script.log [Warning ] This will drop csm_ras_type table data from csmdb database. Do you want to continue [y/n]? [Info ] User response: y [Info ] Record delete count from the csm_ras_type table: 744 [Info ] csm_ras_type live row count: 0 [Info ] csm_ras_type_audit live row count: 1488 [Info ] Data from the csm_ras_type table has been successfully removed ------------------------------------------------------------------------------------------------------------------------
- The script will remove records from the
csm_ras_typetable and repopulate when a given csv file is present after the db_name. The option (-r, --removedata) can be executed. A prompt message will appear and the admin has the ability to choose"y/n". Each of the logging message will be logged accordingly./opt/ibm/csm/db/csm_db_ras_type_script.sh –r my_db_name <ras_csv_file> (where my_db_name is the name of your DB and the csv_file_name). Example (successful execution): -bash-4.2$ ./csm_db_ras_type_script.sh -r csmdb csm_ras_type_data.csv ------------------------------------------------------------------------------------------------------------------------ [Start ] Welcome to CSM database ras type automation script. ------------------------------------------------------------------------------------------------------------------------ [Info ] Log Dir: /var/log/ibm/csm/db/csm_db_ras_type_script.log [Info ] csm_ras_type_data.csv file exists [Warning ] This will drop csm_ras_type table data from csmdb database. Do you want to continue [y/n]? [Info ] User response: y [Info ] Record delete count from the csm_ras_type table: 744 [Info ] csm_ras_type live row count: 0 [Info ] csm_ras_type_audit live row count: 1488 [Info ] Data from the csm_ras_type table has been successfully removed ------------------------------------------------------------------------------------------------------------------------ [Info ] csm_ras_type record count before script execution: 0 [Info ] Record import count from csm_ras_type_data.csv: 744 [Info ] csm_ras_type live row count after script execution: 744 [Info ] csm_ras_type_audit live row count: 2232 [Info ] Database: csmdb csv upload process complete for csm_ras_type table. ------------------------------------------------------------------------------------------------------------------------Example (unsuccessful execution):¶
-bash-4.2$ ./csm_db_ras_type_script.sh -r csmdb ------------------------------------------------------------------------------------------------------------------------ [Start ] Welcome to CSM datatbase ras type automation script. ------------------------------------------------------------------------------------------------------------------------ [Info ] Log Dir: /var/log/ibm/csm/db/csm_db_ras_type_script.log [Info ] csm_ras_type_data.csv file exists [Warning ] This will drop csm_ras_type table data from csmdb database. Do you want to continue [y/n]? [Info ] User response: n [Info ] Data removal from the csm_ras_type table has been aborted ------------------------------------------------------------------------------------------------------------------------Infrastructure¶
The managing process of CSM. The infrastructure facilitates the interaction of the local CSM APIs and the CSM Database and cluster Compute nodes.
A Broad general visualization of the infrastructure has been reproduced below:
CSMD Executable¶
The
csmdexecutable is bundled in thecsm-core-*.rpmat/opt/ibm/csm/sbin/csmd.This executable has been daemonized to run the CSM Infrastructure.
CSMD Command line options¶
Supported Command Line Options: -h [ --help ] Show this help -f [ --file ] arg Specify configuration file (default: /etc/ibm/csm/csm_master.cfg) -r [ --role ] arg Set the role of the daemon (M|m)[aster] | (A|a)[ggregator] | (C|c)[ompute] | (U|u)[tility]Note
- The role is determined by the first letter of the role argument.
- The file path should be an absolute path to avoid confusion.
CSMD Services¶
CSM defines four service types that are accessible through
systemctl.
Type Config Service Utility /etc/ibm/csm/csm_utility.cfg csmd-utility.service Master /etc/ibm/csm/csm_master.cfg csmd-master.service Aggregator /etc/ibm/csm/csm_aggregator.cfg csmd-aggregator.service Compute /etc/ibm/csm/csm_compute.cfg csmd-compute.service The following is a sample how to manipulate these services:
systemctl [status|start|stop|restart] csmd-utilityCSMD Configuration¶
To configure the
csmddaemon please refer to CSMD Configuration.ACL Configuration¶
To use the CSM API with proper security an ACL file must be configured. Using a combination of user privilege level and API access level, CSM determines what the actions to perform when an API is called by a user.
For example, if the user doesn’t have the proper privilege on a private API, the returned information will be limited or denied all together.
A user can be either privileged or non-privileged. To become a privileged user, either the user name must be listed as a privileged user in the ACL file or the user needs to be a member of a group that’s listed as a privileged group.
A template or default ACL file is included in the installation and can be found under
/opt/ibm/share/etc/csm_api.acl.{ "privileged_user_id": "root", "privileged_group_id": "root", "private": ["csm_allocation_query_details", "csm_allocation_delete", "csm_allocation_update_state", "csm_bb_cmd", "csm_jsrun_cmd", "csm_allocation_step_query_details"], "public": ["csm_allocation_step_cgroup_create", "csm_allocation_step_cgroup_delete", "csm_allocation_query", "csm_allocation_query_active_all", "csm_allocation_resources_query", "csm_allocation_step_begin", "csm_allocation_step_end", "csm_allocation_step_query", "csm_allocation_step_query_active_all", "csm_diag_run_query", "csm_node_attributes_query", "csm_node_attributes_query_history", "csm_node_resources_query", "csm_node_resources_query_all"] }The CSM API ACL configuration is done through the file pointed at by the setting in the csm config file (
csm.api_permission_file). It is required to be in json format. The main entries are:
privileged_user_id: Lists the users that will be allowed to perform administrator tasks in terms of calling privileged CSM APIs. The user root will always be able to call APIs regardless of the configured privilege level.
If more than one user needs to be listed, use the
[..,..]format for json lists.privileged_user_group: Lists the groups which will be allowed to perform administrator tasks in terms of calling privileged CSM APIs. Users in group root will always be able to call APIs independent of the configured privilege level.
If more than one user needs to be listed, use the
[..,..]format for json lists.private: Specifies a list of CSM APIs that are private. A private API can only be called by privileged users or owners of the corresponding resources.
For example, csm_allocation_query_details can only be called by the owner of the requested allocation.
public: Specifies a list of CSM APIs that can be called by any user who has access to the node and the client_listen socket of the CSM daemon.
privileged: Explicitly configure a list of CSM APIs as privileged APIs. The section is not present in the template ACL file because any API will be privileged unless listed as private or public.
Warning
The ACL files should be synchronized between all nodes of the CSM infrastructure. Each daemon will attempt to enforce as many of the permissions as possible before routing the request to other daemons for furtherprocessing.
For example, if a user calls an API on a utility node where the API is configured public, there will be no further permission check if that request is forwarded to the master even if the ACL config on the master configures the API as private or privileged.
The permissions of a request are determined at the point of entry to the infrastructure. Enforcement is based on the effective user id and group id on the machine that runs the requesting client process.
API Configuration¶
The CSM API configuration file (json) allows the admin to set a number of API-specific parameters.
{ "#comment_1" : "This will be ignored", "csm_allocation_create" : 120, "csm_allocation_delete" : 120, "csm_allocation_update_state" : 120, "csm_allocation_step_end" : 120, "csm_allocation_step_begin" : 120, "csm_allocation_query" : 120, "csm_bb_cmd" : 120, "csm_jsrun_cmd" : 60, "csm_soft_failure_recovery" : 240 }At the moment this only includes the timeout for CSM APIs (in seconds). The API config file path and name is defined in the CSM config file setting
csm.api_configuration_file.Warning
The API configuration files should be synchronized between all nodes of the CSM infrastructure to avoid unexpected API timeout behavior.
The current version of CSM calculates daemon-role-specific, fixed API timeouts based on the configuration file. Meaning the actual timeouts will be different (lower) than the configured time to account for delays in the communication, processing, or number of internal round-trips for certain APIs.
For example, an API called from the utility node is configured with a 120s timeout. Once the request is forwarded to the master, the master will enforce a timeout of 119s accounting for network and processing delays.
If the request requires the master to reach out to compute nodes the aggregators will enforce a timeout of 58s because the aggregator accounts for some APIs requiring 2 round trips and 1 additional network hop.
Generally, the expected enforced timeout is: <value> / 2 - 2s.
CSMD Configuration¶
Each type of daemon is set up via a dedicated configuration file (default location: /etc/ibm/csm/csm_*.cfg). The format of the config file is json, json parse errors indicate formatting problems in the config file.
Warning
The CSM daemon needs to be restarted for any changes to the configuration to take effect.
The `csm` Block
{ "csm" : { "role": "<daemon_role>", "thread_pool_size" : 1, "api_permission_file": "/etc/ibm/csm/csm_api.acl", "api_configuration_file": "/etc/ibm/csm/csm_api.cfg", "log" : { }, "db" : { }, "inventory" : { }, "net" : { }, "ras" : { }, "ufm" : { }, "bds" : { }, "recurring_tasks": { }, "data_collection" : { }, "jitter_mitigation" : { } } }Beginning with the top-level configuration section csm.
role: Sets the role of the daemon (
master,utility,compute,aggregator). If the role is provided in both command line and config file, the command line setting overrides this setting.thread_pool_size: Controls the number of worker threads that are used to process any CSM API calls and event handling. A setting of 1 should generally suffice. However, if there are some CSM API calls that spawn external processes which in turn might call other CSM APIs (e.g. csm_allocation_create() spawning the prolog).
The worker thread waits for the completion of the spawned process and with only one available worker, there will be no resources left to process the additional API call. This is why a setting of at least 4 is recommended for compute nodes.
api_permission_file: Points to the file that controls the permissions of API calls to specify admin users/groups and classify CSM APIs as public, private, or privileged.
See ACL Configuration for details.
api_configuration_file: Points to the file that contains detailled configuration settings for CSM API calls. If an API requires a non-default timeout, it should be configured in that file.
See API Configuration for details.
log: A subsection that defines the logging level of various components of the daemon.
See The log Block.
db: A master-specific block to set up the data base connection.
inventory: Configures the inventory collection component.
See The inventory block.
net: Configures the network collection component to define the interconnectivity of the CSM infrastructure.
ras: Documentation ongoing.
ufm: Configures access to UFM.
See The UFM block.
bds: Addresses, ports, and other settings for BDS access.
See The BDS block.
recurring_tasks: Sets up intervals and types of predefined recurring tasks to be triggered by the daemon.
data_collection: Enables and configures predefined buckets for environmental data collection.
jitter_mitigation: Configures the Mitigation strategy for core isolation and CGroups.
The
logblock¶The log block determines what amount of logging goes to which files and console. This block also specifies log rotation options.
{ "format" : "%TimeStamp% %SubComponent%::%Severity% | %Message%", "consoleLog" : false, "sysLog" : true, "fileLog" : "/var/log/ibm/csm/csm_master.log", "#rotationSize_comment_1" : "Maximum size (in bytes) of the log file, ~1GB", "rotationSize" : 1000000000, "default_sev" : "warning", "csmdb" : "info", "csmnet" : "info", "csmd" : "info", "csmras" : "info", "csmapi" : "info", "csmenv" : "info", "transaction" : true, "transaction_file" : "/var/log/ibm/csm/csm_transaction.log", "transaction_rotation_size" : 1000000000 "allocation_metrics" : true, "allocation_metrics_file" : "/var/log/ibm/csm/csm_allocation_metrics.log", "allocation_metrics_rotation_size" : 1000000000 }
format: Defines a template for the format of the CSM log lines. In the given example, a log Message is prefixed with the TimeStamp followed the name of the SubComponent and the Severity. The SubComponent helps to identify the source of the message (e.g. the csmnet = Network component; csmapi = CSM API call processing).
consoleLog: Determines whether the logs should go to the console or not. Can be
trueorfalse.fileLog: Determine whether the logs should go to syslog or not. Can be
trueorfalse.rotationSize: Limits the size (bytes) of the log file before starting a new log file. If set to -1 the file is allowed to grow without limit.
default_sev: Set the logging level/verbosity for any component that’s not mentioned explicitly.
Options include:
criticalLog only very critical and fatal errors. errorErrors and critical messages. warningWarnings and everything above. infoInfo messages and everything above. debugDebug level messages and everything above; very verbose. traceVery detailed logging including everything. Intended for tracing analysis. csmdb: Log level of the database component. Includes messages about database access and request handling.
csmnet: Log level of the network component. Includes messages about the network interaction between daemons and daemons and client processes.
csmd: Log level of the core daemon. Includes messages from the core of the infrastructure handling and management.
csmras: Log level of the RAS component. Includes messages about RAS events and their processing within the daemon.
csmapi: Log level of CSM API handling. Includes messages about API call processing.
csmenv: Log level of environmental data handling. Includes messages related primarily to data collection and shipping from compute to aggregators.
transaction: Enables the mechanism transaction log mechanism.
transaction_file: Specifies the location the transaction log will be saved to.
transaction_rotation_size: The size of the file (in bytes) to rotate the log at.
allocation: Enables the mechanism allocation metrics log mechanism.
allocation_file: Specifies the location the allocation metrics log will be saved to.
allocation_rotation_size: The size of the file (in bytes) to rotate the log at.
The Database[
db] Block¶The database block configures the location and access parameters of the CSM database. The settings are specific and relevant to the master daemon only.
{ "connection_pool_size" : 10, "host" : "127.0.0.1", "name" : "csmdb", "user" : "csmdb", "password" : "", "schema_name" : "" }
connection_pool_size: Configures the number of connections to the database. This number also specifies the number of database worker threads for concurrent access and parallel processing of requests.
CSM recommends empirical adjustments to this size depending on system demand and spec. Demand will grow with size of the system and frequency of CSM API calls.
host: The hostname or IP address of the database server.
name: The name of the database on the
hostserver.user: The username that CSM should use to access the database.
password: The password to access the database.
Attention
Be sure to set permissions of the file when the
passwordfield is set!schema_name: in case there is a named schema in use, this configures the name The named schema in the database (optional in the default configuration).
The
inventoryBlock¶The inventory block configures the location of files that are used for collection of the network inventory.
{ "csm_inv_log_dir" : "/var/log/ibm/csm/inv", "ufm": { "ib_cable_errors" : "bad_ib_cable_records.txt", "switch_errors" : "bad_switch_records.txt", "ufm_switch_output_file_name" : "ufm_switch_output_file.json", "ufm_switch_input_file_name" : "ufm_switch_output_file.json" } }
csm_inv_log_dir: The absolute path for inventory collection logs.
ufm:
ib_cable_errors: Output file location for records of bad IB cables as detected by CSM.
Relative to the
csm_inv_log_dir.switch_errors: Output file location for records of IB switch errors as detected by CSM.
Relative to the
csm_inv_log_dir.ufm_switch_output_file_name: During inventory collection, CSM calls a ufm restfulAPI. The restfulAPI outputs json. CSM saves the json output to a file. CSM will use this value to name that file.
Relative to the
csm_inv_log_dir.ufm_switch_input_file_name: During inventory collection, CSM needs to read from a json file that contains inventory data. This value is the name of the file to read from. Most of the time it should be the same as the output file above. As step 1 is collect the info and save it, then step 2 is to read that info, parse it, and send it to CSM database. CSM team has seperated these two values to give the system admin an opportunity to read from a different file other than what was collected and saved in step 1.
Relative to the
csm_inv_log_dir.The Network[
net] Block¶The network block defines the hostnames, ports, and other important parameters of the CSM daemon infrastructure. Several subsections are specific to the role of the daemon.
{ "heartbeat_interval" : 15, "local_client_listen" : { "socket" : "/run/csmd.sock", "permissions" : 777, "group" : "" }, "ssl": { "ca_file" : "", "cred_pem" : "" } }General settings available for all daemon roles:
heartbeat_interval: Determines the interval (in seconds) that this daemon will use for any connections to other CSM daemon(s) of the infrastructure. The actual interval of a connection will be the minimum interval of the 2 peers of that connection.
For example, if one daemon initiates a connection with an interval of 60s while the peer daemon is configured to use 15s, both daemons will use a 15s interval for this connection.
Note
It takes about 3 intervals for a daemon to consider a connection as dead. Because each connection’s heartbeat is the minimum one can run different intervals between different daemons if necessary or desired.
local_client_listen: This subsection configures a unix domain socket where the daemon will receive requests from local clients. This subsection is available for all daemon roles.
Note
If you run multiple daemons on the same node, this section needs a dedicated setting for each daemon.
socket: Defines the absolute path to socket file (name included). permissions: Defines the access permissions of the socket. This is one way to limit the ability to call CSM APIs on a particular node. group: Specifies the group owner of the socket file. ssl: This subsection allows the user to enable SSL encryption and authentication between daemons. If any of the two settings below are non-empty, the CSM daemon will enable SSL for daemon-to-daemon connections by using the specified files.
Note
Since there’s only one certificate entry in the configuration, the same certificate has to serve as client and server certificate at the same time. This puts some limitations on the configuration of the certificate infrastructure.
ca_file: Specifies the file whic contains the Certificate Authority to check the validity of certificates.
cred_pem: Specifies the file which contains the signed credentials/the certificate in PEM format.
This certificate is presented to the passive/listening peer to prove that the daemon is allowed to connect to the infrastructure. It is presented to the active/connecting peer to prove that the infrastructure is the one the daemon is looking for.
Note
Note that the heartbeat is not determining the overall health of a peer daemon. The daemon might be able to respond to heartbeats.. while still impeded to respond to API calls. A successful exchange of heartbeats tells the daemon that there’s a functional network connection and the network mgr thread is able to process inbound and outbound messages. To check if a daemon is able to process API calls, you might use the infrastructure health check tool.
Note
The following is an explaination of the heartbeat mechanism to show why it takes about 3 intervals to detect a dead connection.
The heartbeat between daemons works as follows:
- After creating the connection, the daemons negotiate the smallest interval and start the timer.
- Whenever a message arrives at one daemon, the timer is reset.
- If the timer triggers, the daemon sends a heartbeat message to the peer and sets the connection status as UNSURE (as in unsure whether the peer is still alive) and resets the timer.
- If the peer receives the heartbeat, it will reset its timer. After the timer triggers, it will send a heartbeat back.
- If the peer responds, the timer is reset and the connection status is HAPPY.
- If the peer doesn’t respond and the timer triggers again, the daemon will send a second heartbeat, reset the timer, and change the status to MISSING_RECV.
- If the timer triggers without a response, the connection will be considered DEAD and torn down.
Network Destination Blocks¶
The following blocks unilaterally use the following two fields:
host: Determines the hostname or IP address of the listening socket.
Note
To bind a particular interface, it is recommended to use an explicit IP address. Template entries like __MASTER__ and __AGGREGATOR__ are placeholders for the IP or host of a CSM daemon with that role.
A host entry which is set to
NONEwill disable any attempt to connect.port: Specifies the port of a socket, it is used as both a listening and destination port.
{ "aggregator_listen": { "host": "__MASTER__", "port": 9815 }, "utility_listen": { "host": "__MASTER__", "port": 9816 }, "compute_listen": { "host": "__AGGREGATOR__", "port": 9800 }, "master": { "host": "__MASTER__", "port": 9815 }, "aggregatorA" : { "host": "__AGGREGATOR_A__", "port": 9800 }, "aggregatorB" : { "host": "__AGGREGATOR_B__", "port": 9800 } }Possible connection configuration sections:
aggregator_listen: [ master] Specifies the interface and port where the master expects aggregators to connect.utility_listen: [ master] Specifies the interface and port where the master expects utility daemons to connect.compute_listen: [ aggregator] Specifies the interface and port where an aggregator expects compute nodes to connect.master: [ utility,aggregator] Configures the coordinates of the master daemon.aggregatorA: [ compute] Configures the coordinates of the primary aggregator. The primary aggregator must be configured to allow the compute node to work (required to start).aggregatorB: [ compute] Configures the coordinates of the secondary aggregator. Setting thehostof this section toNONEwill disable the compute daemons’ attempt to create and maintain a redundant path through a secondary aggregator.The
ufmBlock¶The ufm block configures the location and access to ufm.
{ "rest_address" : "__UFM_REST_ADDRESS__", "rest_port" : 80, "ufm_ssl_file_path" : "/etc/ibm/csm", "ufm_ssl_file_name" : "csm_ufm_ssl_key.txt" }
rest_address: The hostname of the UFM server.
rest_port: The port UFM is serving the RESTful interface on (generally
80).ufm_ssl_file_path: The path to the SSL file for UFM access.
ufm_ssl_file_name: An SSL file for UFM Access.
May be generated using the following command:
openssl base64 -e <<< ${username}:${password} > /etc/ibm/csm/csm_ufm_ssl_key.txt;The
bdsBlock¶The BDS block configures the access to the Big Data Store.
{ "host" : "__LOGSTASH__", "port" : 10522, "reconnect_interval_max" : 5, "data_cache_expiration" : 600 }
host: Points to the host or IP address of the Logstash service.
If following the configuration section in Logstash this should be
localhost.port: The port that CSM should send entries to on the
host.If following the configuration section in Logstash this should be
10522reconnect_interval_max: Reconnect interval in seconds to the Logstash server.
Limits the frequency of reconnect attempts to the Logstash server in the event the service is down. If the aggregator daemon is unable to connect, it will delay the next attempt for 1s. If the next attempt fails, it will wait 2s before retrying. This retry attempt will continue until
reconnect_interval_maxis reached.data_cache_expiration: The number of seconds the daemon will keep any environmental data that failed to get sent to Logstash. To limit the loss of environmental data, it is recommended to set the expiration to be longer than the maximum reconnect interval.
Note
This block is only leveraged on the Aggregator.
The
recurring_tasksBlock¶{ "enabled" : false, "soft_fail_recovery" : { "enabled" : false, "interval" : "00:01:00", "retry" : 3 } }The recurring tasks configuration block, schedules recurring tasks that are supported by CSM.
enabled: Indicates whether or not recurring tasks will be processed by the daemons.
soft_fail_recovery¶The soft failure recovery task executes the soft_failure_recovery API over the specified interval for the number of retries specified. For s
{ "enabled" : false, "interval" : "00:01:00", "retry" : 3 }
enabled: Indicates whether or not this task will be processed by the daemons. interval: The interval time between recurring tasks, format: HH:mm:ss. retry: The number of times to retry the task on a specific node before placing the node into soft failure, if the daemon is restarted the retry count for the node will be restarted. Attention
This is only defined on the Master Daemon.
The
data_collectionBlock¶The data collection block configures environmental data collection on compute nodes. It has no effect on other daemon roles.
{ "buckets": [ { "execution_interval":"00:10:00", "item_list": ["gpu", "environmental"] }, { "execution_interval":"24:00:00", "item_list": ["ssd"] } ] }
buckets: A json array of buckets for collection of environmental data. Each array element or bucket is configured as follows:
execution_interval: Sets the interval (ISO format) that this bucket is supposed to be collected.
item_list: Specifies a json array of predefined items to collect. Currently available items are:
gpuA set of GPU stats and counters. environmentalA set of CPU and machine stats and counters. ssdA set of SSD wear stats and counters. The
jitter_mitigationblock¶The jitter mitigation block is used to configure how core isolation functions in regards to Allocations. This block will only be required on Compute Node configurations.
"jitter_mitigation" : { "enabled" : true, "blink_enabled" : true, "system_smt" : 0, "irq_affinity" : true, "core_isolation_max" : 4, "socket_order" : "00" }
enabled: Toggle for whether or not the cgroup mitigation should be executed. Default is true (executes cgroup code).
blink_enabled: Toggle for the blink feature when setting SMT mode, which shut downs cores to blink. Default is true (executes the cgroup blink).
system_smt: The SMT mode of the system cgroup, if unset this will use the maximum SMT mode.
Setting this option to
0will maximize the SMT mode. Setting this option higher than the allowed SMT mode will clamp to the maximum SMT mode.irq_affinity: Flag determining the behavior of Allocation Creation in relation to IRQ rebalancing.
If set to true the cores in system cgroup will have all IRQ rebalanced to them and the IRQ Balance Daemon will be shut down.
If no core isolation occurs a rebalance across all cores will be performed and the IRQ Balance Daemon will be reset.
If set to false, no rebalancing occurs.
core_isolation_max: The maximum number of cores allowed on the node to be set aside for the system cgroup. By default this will be set to
4.socket_order: A mask determining the direction which the isolated cores will be allocated for the system cgroup, per socket.
0indicates the cores will be allocated by the cgroup left to right.1indicates that the cores will be allocated by the cgroup right to left.Each character in the mapping string corresponds to a socket on the node. If a socket is not defined by the mapping it will be set to
0.Inventory¶
CSM can store information about your cluster. One category of this information is the physical hardware inventory and statistics of your cluster. Once collected this data is stored in the Database.
CSM supports inventory collection for the following topics:
Network Inventory¶
Overview¶
The network inventoy (such as: switches, switch modules, and cables) can be collected and stored into the Database.
CSM supports inventory collection for the following network hardware:
- Mellanox
Note
If your network hardware is not listed here, then please create an issue on the CAST GitHub page.
One type of network hardware is Mellanox. CSM worked closely with Mellanox to streamline Mellanox integration. CSM created a tool to help collect Mellanox based inventory. You can find documentation on that tool here: CSM standalone inventory collection.
Collectable Inventory¶
Here we describe what CSM is able to detect and collect inventory on in regards to the network.
Switches¶
CSM can collect information about a physical switch and store it the the Database inside the csm_switch table.
Switch Modules¶
CSM can collect information about hardware components of a switch and store them in the Database inside the csm_switch_inventory table.
Examples of hardware components found on a switch are:
- Fans
- Power Supplies
Cables¶
CSM can collect information about the physical cables in your system and store them in the Database inside the csm_ib_cable table.
Note
At this time, only Mellanox IB cables are fully supported by CSM inventory collection.
HCA¶
HCA hardware inventory is collected, but is collected with Node Inventory.
Node Inventory¶
Overview¶
CSM can collect and store hardware information about a node and store it in the Database.
Below is a table outlining what information is collected and where in the Database it is stored:
INFORMATION Database Table Core Node csm_node Dimm csm_dimm GPU csm_gpu HCA csm_hca Processor csm_processor_socket SSD csm_ssd Collection¶
Core Node inventory collection begins when a CSM Daemon is booted on a node.
External Integration¶
CSM can be connected to other products and services for increased productivity. This section is a general purpose guide for connecting CSM to other products and services.
This section is divided into the following subsections:
Mellanox and Infiniband¶
CSM can be integrated with Mellanox to enhance usability of your cluster. CSM can collect inventory on Mellanox hardware and convert Mellanox events into corresponding CSM RAS events.
Credentials¶
For CSM to communicate with Mellanox systems and access the Mellanox UFM restful APIs, a user must have proper credentials. CSM will attempt to connect to UFM via an SSL key. The location of your SSL key can be configured via the
csm_master.cfgfile. Using theufm_ssl_file_pathandufm_ssl_file_namefields. Default values have been reproduced below for reference.{ "ufm" : { "rest_address" : "__UFM_REST_ADDRESS__", "rest_port" : 80, "ufm_ssl_file_path" : "/etc/ibm/csm", "ufm_ssl_file_name" : "csm_ufm_ssl_key.txt" } }An SSL key must be generated and placed in this file or CSM will not be able to communicate with UFM restful APIs.
SSL key generation can be done via the
opensslcommand found in UNIX. Creating a key for the default username ofadminand the default password of123456is shown below:openssl base64 -e <<< admin:123456It should generate a key for you:
YWRtaW46MTIzNDU2Cg==When you generate your key, please use your username and password. It will generate a different key.To simplify steps further, you can also directly pipe the output into your key file.
Example:
openssl base64 -e <<< admin:123456 > /etc/ibm/csm/csm_ufm_ssl_key.txtNetwork Inventory Collection¶
The Network Inventory (such as: switches, switch modules, and cables) can be collected and stored into the Database.
Inventory collection has been modularly developed. We separated the external inventory data collection from the internal CSM Database insertion. Once data has been collected, you can then insert that collected data into the CSM Database by using a CSM API. We do this for ease of future updates, should an external component change the way it collects and presents its data.
Because of this development choice, CSM can easily be adapted to work with multiple external programs and services.
For ease of use, CSM provides a tool: CSM standalone inventory collection which will collect inventory information from Mellanox and insert that data into the CSM Database.
Tools¶
CSM logging tools¶
To use the CSM logging tools run:
opt/csm/tools/API_Statistics.pypython script.This python script parses log files to calculate the start and end time of API calls on the different types of nodes that generate these logs. From the start and end time, the script calculates:
frequencyat which the API was calledmeanrun timemedianrun timeminimumrun timemaximumrun timestandard deviationrun timeThe script also captures job ID collisions when start and end API’s do not match.
Note
Run the script with -h for help.
[root@c650f03p41 tools]# python API_Statistics.py -h usage: API_Statistics.py [-h] [-p path] [-s start] [-e end] [-o order] [-r reverse] A tool for parsing daemon logs for API statistics. optional arguments: -h, --help show this help message and exit -p path The directory path to where the logs are located. Defaults to: '/var/log/ibm/csm' -s start start of search range. Defaults to: '1000-01-01 00:00:00.0000' -e end end of search range. Defaults to: '9999-01-01 00:00:00.0000' -o order order the results by a field. Defaults to alphabetical by API name. Valid values: 0 = alphabetical, 1 = Frequency, 2 = Mean, 3 = Max, 4 = Min, 5 = Std -r reverse reverse the order of the data. Defaults to 0. Set to 1 to turn on.Obtaining Log Statistics¶
Setup¶
This script handles Master, Computer, Utility, and, Aggregator logs. These must be placed under the
opt/csm/tools/Logsdirectory unders their respective types.Note
As of CSM 1.4, the script can be pointed to a directory where the log files are located, and by default the program will use
/var/log/ibm/csm.Running the script¶
There are three ways of running the logs with time formats:
Format: <Start Date> <Start Time> Format: YYYY-MM-DD HH:MM::SS
- Run through the logs in its entirety:
python API_Statistics.py
- Run through the logs with a specific start time:
python API_Statistics.py <Start Date> <Start Time>
- Run through the logs with a specific start and end time:
python API_Statistics.py <Start Date> <Start Time> <End Date> <End Time>Note
As of CSM 1.4 the time ranges of the script has been updated to use flags.
Output¶
Reports will be caluclated and saved to individual files under
opt/csm/tools/Reportsunder their respective log types. (The script will output to the screen as well). The report includes errors and calculated statistics.CSM standalone inventory collection¶
This tool connects to UFM and collects inventory information on all Mellanox hardware in the system. You can find it located at:
/opt/ibm/csm/sbin. This program has a-h, --helpflag to display helpful information and should be viewed to familiarize a user with the program’s features.Setup and Configuration¶
This tool requires a properly set up
csm_master.cfgfile. The system administrator should update the followingufmsection with the properrest_addressandrest_port. Without the address for the UFM server, this tool can not communicate with UFM. For more information about configuration files, look here: CSMD Configuration.{ "ufm" : { "rest_address" : "__UFM_REST_ADDRESS__", "rest_port" : 80, "ufm_ssl_file_path" : "/etc/ibm/csm", "ufm_ssl_file_name" : "csm_ufm_ssl_key.txt" } }The system administrator must also create an SSL key for their UFM username and password. You can read more on how to do that here: Credentials.
A system administrator can also configure this tool’s output. CSM may detect some network hardware that is not Mellanox hardware or may collect incomplete records for Mellanox hardware. If this is the case, CSM will capture what data it can and output those records to a bad_records file. The default location and names of these files are copied from the
csm_master.cfgfile and reproduced below. A system administrator can update thecsm_master.cfgfile to customize or change these filenames should they choose.{ "inventory" : { "csm_inv_log_dir" : "/var/log/ibm/csm/inv", "ufm": { "ib_cable_errors" : "bad_ib_cable_records.txt", "switch_errors" : "bad_switch_records.txt", "ufm_switch_output_file_name" : "ufm_switch_output_file.json", "ufm_switch_input_file_name" : "ufm_switch_output_file.json" } } }
csm_inv_log_dir: The absolute path for inventory collection logs.
ufm:
ib_cable_errors: Output file location for records of bad IB cables as detected by CSM.
Relative to the
csm_inv_log_dir.switch_errors: Output file location for records of IB switch errors as detected by CSM.
Relative to the
csm_inv_log_dir.ufm_switch_output_file_name: During inventory collection, CSM calls a ufm restfulAPI. The restfulAPI outputs json. CSM saves the json output to a file. CSM will use this value to name that file.
Relative to the
csm_inv_log_dir.ufm_switch_input_file_name: During inventory collection, CSM needs to read from a json file that contains inventory data. This value is the name of the file to read from. Most of the time it should be the same as the output file above. As step 1 is collect the info and save it, then step 2 is to read that info, parse it, and send it to CSM database. CSM team has seperated these two values to give the system admin an opportunity to read from a different file other than what was collected and saved in step 1.
Relative to the
csm_inv_log_dir.Note
For CSM 1.7, this tool only supports an
httpconnection to UFM. UFM’sgv.cfgfile must be configured for http connection. Specifically,ws_protocol = http. And also the MLNX-OS section must be set to http. Specifically,protocol = http, andport = 80.Example:
ws_protocol = httpand
# default MLNX-OS access point for all Mellanox switches # important: this section parameters are used for ufm initialization only !!! # Please use ufm GUI/API for editing parameters values. [MLNX_OS] protocol = http port = 80Note
For CSM 1.8, this tool supports http and https connection to the UFM daemon, but still requires the ufmd to communicate to a managed switch via http. Please ensure that the MLNX-OS section is set to http. Specifically,
protocol = http, andport = 80.Example:
# default MLNX-OS access point for all Mellanox switches # important: this section parameters are used for ufm initialization only !!! # Please use ufm GUI/API for editing parameters values. [MLNX_OS] protocol = http port = 80Improper communication settings could result in some of the issues presented in the FAQ - Frequently Asked Questions.
Using the Tool¶
The UFM Inventory collection tool has multiple flags.
For help run the tool with the
-h, --helpflag. This will give useful help for all flags and example values.The first flag is
-c, --config. This flag tells the tool where yourcsm_master.cfgfile is located. If this flag is not provided, then the tool will look in the default location of:/etc/ibm/csm/csm_master.cfg.The second flag is
-t, --type. This flag determines what type of inventory should be collected. 1 = ib cables, 2 = switches, 3 = ib cables and switches. If this flag is not provided, then the tool will default to type 3, collecting information on both ib cables and switches.Another flag,
-i, --input_override, overrides the value forufm_switch_input_file_namedefined in thecsm_master.cfg. This is a direct and literal full path including the filename and extension. This is useful if the tool needs to be passed switch inventory information from a seperate origin source for a single run.Output¶
All output information for this tool is printed to the console. The
-d, --detailsflag can be used to turn on extra information. If there are bad or incomplete records for hardware inventory they will not be copied into the Database and instead placed into the bad_records files specified in thecsm_master.cfgfile.FAQ - Frequently Asked Questions¶
Why ‘bad record’ and ‘N/A’ Serial Numbers?¶
Sometimes CSM can detect a switch in your system that is incomplete. It is missing a serial number, which CSM will consider invalid data, and therefor not insert it into the Database.
Example:
UFM reported 7 switch records. This report from UFM can be found in 'ufm_switch_output_file.json' located at '/var/log/ibm/csm/inv' WARNING: 2 Switches found with 'N/A' serial numbers and have been removed from CSM inventory collection data. These records copied into 'bad_switch_records.txt' located at '/var/log/ibm/csm/inv'This is usually caused by switches not correctly reporting Switch Modules. If the system module is not found, then CSM can not collect the serial number.
Below is an example of JSON data returned from UFM. The first is one missing modules, the second is what we expect in a good case.
Bad case - as you can see the module array is NOT populated. :
[ { "cpus_number": 0, "ip": "10.7.3.2", "ram": 0, "fw_version": "15.2000.2626", "mirroring_template": false, "cpu_speed": 0, "is_manual_ip": true, "technology": "EDR", "psid": "MT_2630110032", "guid": "248a070300fcccd0", "severity": "Warning", "script": "N/A", "capabilities": [ "Provisioning" ], "state": "active", "role": "tor", "type": "switch", "sm_mode": "noSM", "vendor": "Mellanox", "description": "MSB7800", "has_ufm_agent": false, "server_operation_mode": "Switch", "groups": [ "Alarmed_Devices" ], "total_alarms": 1, "temperature": "N/A", "system_name": "c650f03ib-root01-M", "sw_version": "N/A", "system_guid": "248a070300fcccd0", "name": "248a070300fcccd0", "url": "", "modules": [], "cpu_type": "any", "is_managed": true, "model": "MSB7800", "ports": [ "248a070300fcccd0_9", "248a070300fcccd0_8", "248a070300fcccd0_7", "248a070300fcccd0_6", "248a070300fcccd0_5", "248a070300fcccd0_4", "248a070300fcccd0_3", "248a070300fcccd0_2", "248a070300fcccd0_1", "248a070300fcccd0_28", "248a070300fcccd0_29", "248a070300fcccd0_26", "248a070300fcccd0_27", "248a070300fcccd0_24", "248a070300fcccd0_25", "248a070300fcccd0_22", "248a070300fcccd0_23", "248a070300fcccd0_20", "248a070300fcccd0_21", "248a070300fcccd0_37", "248a070300fcccd0_36", "248a070300fcccd0_16", "248a070300fcccd0_15", "248a070300fcccd0_10", "248a070300fcccd0_31", "248a070300fcccd0_30", "248a070300fcccd0_33", "248a070300fcccd0_32", "248a070300fcccd0_35", "248a070300fcccd0_34", "248a070300fcccd0_19", "248a070300fcccd0_18" ] } ]How you would see this JSON represented in the bad_records files of CSM. Notice the missing modules section.
CSM switch inventory collection File created: Fri Feb 28 13:40:59 2020 The following records are incomplete and can not be inserted into CSM database. Switch: 2 ip: 10.7.3.2 fw_version: 15.2000.2626 total_alarms: 1 psid: MT_2630110032 guid: 248a070300fcccd0 state: active role: tor type: switch vendor: Mellanox description: MSB7800 has_ufm_agent: false server_operation_mode: Switch sm_mode: noSM system_name: c650f03ib-root01-M sw_version: N/A system_guid: 248a070300fcccd0 name: 248a070300fcccd0 modules: ??? serial_number: N/A model: MSB7800Good case - as you can see the module array is populated. :
[ { "cpus_number": 0, "ip": "10.7.4.2", "ram": 0, "fw_version": "15.2000.2626", "mirroring_template": false, "cpu_speed": 0, "is_manual_ip": true, "technology": "EDR", "psid": "MT_2630110032", "guid": "248a070300fd6100", "severity": "Info", "script": "N/A", "capabilities": [ "ssh", "sysinfo", "reboot", "mirroring", "sw_upgrade", "Provisioning" ], "state": "active", "role": "tor", "type": "switch", "sm_mode": "noSM", "vendor": "Mellanox", "description": "MSB7800", "has_ufm_agent": false, "server_operation_mode": "Switch", "groups": [], "total_alarms": 0, "temperature": "56", "system_name": "c650f04ib-leaf02-M", "sw_version": "3.8.2102-X86_64", "system_guid": "248a070300fd6100", "name": "248a070300fd6100", "url": "", "modules": [ { "status": "OK", "sw_version": "N/A", "hw_version": "MSB7800-ES2F", "name": "248a070300fd6100_4000_01", "hosting_system_guid": "248a070300fd6100", "number_of_chips": 0, "description": "MGMT - 1", "max_ib_ports": 0, "module_index": 1, "temperature": "N/A", "device_type": "Switch", "serial_number": "MT1706X02692", "path": "default(86) / Switch: c650f04ib-leaf02-M / MGMT 1", "device_name": "c650f04ib-leaf02-M", "type": "MGMT", "severity": "Info" }, { "status": "OK", "sw_version": "N/A", "hw_version": "MTEF-PSF-AC-A", "name": "248a070300fd6100_2005_01", "hosting_system_guid": "248a070300fd6100", "number_of_chips": 0, "description": "PS - 1", "max_ib_ports": 0, "module_index": 1, "temperature": "N/A", "device_type": "Switch", "serial_number": "MT1706X07347", "path": "default(86) / Switch: c650f04ib-leaf02-M / PS 1", "device_name": "c650f04ib-leaf02-M", "type": "PS", "severity": "Info" }, { "status": "OK", "sw_version": "3.8.2102-X86_64", "hw_version": "MSB7800-ES2F", "name": "248a070300fd6100_1007_01", "hosting_system_guid": "248a070300fd6100", "number_of_chips": 0, "description": "SYSTEM", "max_ib_ports": 0, "module_index": 1, "temperature": "56", "device_type": "Switch", "serial_number": "MT1706X02692", "path": "default(86) / Switch: c650f04ib-leaf02-M / system 1", "device_name": "c650f04ib-leaf02-M", "type": "SYSTEM", "severity": "Info" }, { "status": "OK", "sw_version": "N/A", "hw_version": "MTEF-PSF-AC-A", "name": "248a070300fd6100_2005_02", "hosting_system_guid": "248a070300fd6100", "number_of_chips": 0, "description": "PS - 2", "max_ib_ports": 0, "module_index": 2, "temperature": "N/A", "device_type": "Switch", "serial_number": "MT1706X07348", "path": "default(86) / Switch: c650f04ib-leaf02-M / PS 2", "device_name": "c650f04ib-leaf02-M", "type": "PS", "severity": "Info" }, { "status": "OK", "sw_version": "N/A", "hw_version": "MTEF-FANF-A", "name": "248a070300fd6100_4001_03", "hosting_system_guid": "248a070300fd6100", "number_of_chips": 0, "description": "FAN - 3", "max_ib_ports": 0, "module_index": 3, "temperature": "N/A", "device_type": "Switch", "serial_number": "MT1706X08121", "path": "default(86) / Switch: c650f04ib-leaf02-M / FAN 3", "device_name": "c650f04ib-leaf02-M", "type": "FAN", "severity": "Info" }, { "status": "OK", "sw_version": "N/A", "hw_version": "MTEF-FANF-A", "name": "248a070300fd6100_4001_02", "hosting_system_guid": "248a070300fd6100", "number_of_chips": 0, "description": "FAN - 2", "max_ib_ports": 0, "module_index": 2, "temperature": "N/A", "device_type": "Switch", "serial_number": "MT1706X08119", "path": "default(86) / Switch: c650f04ib-leaf02-M / FAN 2", "device_name": "c650f04ib-leaf02-M", "type": "FAN", "severity": "Info" }, { "status": "OK", "sw_version": "N/A", "hw_version": "MTEF-FANF-A", "name": "248a070300fd6100_4001_01", "hosting_system_guid": "248a070300fd6100", "number_of_chips": 0, "description": "FAN - 1", "max_ib_ports": 0, "module_index": 1, "temperature": "N/A", "device_type": "Switch", "serial_number": "MT1706X08117", "path": "default(86) / Switch: c650f04ib-leaf02-M / FAN 1", "device_name": "c650f04ib-leaf02-M", "type": "FAN", "severity": "Info" }, { "status": "OK", "sw_version": "N/A", "hw_version": "MTEF-FANF-A", "name": "248a070300fd6100_4001_04", "hosting_system_guid": "248a070300fd6100", "number_of_chips": 0, "description": "FAN - 4", "max_ib_ports": 0, "module_index": 4, "temperature": "N/A", "device_type": "Switch", "serial_number": "MT1706X08120", "path": "default(86) / Switch: c650f04ib-leaf02-M / FAN 4", "device_name": "c650f04ib-leaf02-M", "type": "FAN", "severity": "Info" } ], "cpu_type": "any", "is_managed": true, "model": "MSB7800", "ports": [ "248a070300fd6100_33", "248a070300fd6100_1", "248a070300fd6100_3", "248a070300fd6100_2", "248a070300fd6100_5", "248a070300fd6100_4", "248a070300fd6100_7", "248a070300fd6100_6", "248a070300fd6100_9", "248a070300fd6100_8", "248a070300fd6100_15", "248a070300fd6100_14", "248a070300fd6100_17", "248a070300fd6100_16", "248a070300fd6100_11", "248a070300fd6100_10", "248a070300fd6100_13", "248a070300fd6100_12", "248a070300fd6100_37", "248a070300fd6100_19", "248a070300fd6100_18", "248a070300fd6100_36", "248a070300fd6100_35", "248a070300fd6100_34", "248a070300fd6100_20", "248a070300fd6100_21", "248a070300fd6100_23", "248a070300fd6100_24", "248a070300fd6100_26", "248a070300fd6100_27" ] } ]Modules will sometimes not be reported via UFM. One of the most common causes of this is a communication issue with the ufm daemon,
ufmd. See What is a CONNECTOR_ACCESS fail? for more information.What is a CONNECTOR_ACCESS fail?¶
If CSM standalone inventory collection reports a
connector_access failthen it probably failed to connect to theufmd.For example, a system administrator may see:
Response returned with status code 403 INV_IB_CONNECTOR_ACCESS failedor
Response returned with status code 400 INV_SWITCH_CONNECTOR_ACCESS failedIf CSM standalone inventory collection reports an error connecting to the
ufmdor an error in the 400s range, then it may be a communication issue. CSM tries to anticipate the multiple forms of communication, but sometimes a system admin will need to tweak the configuration file for ufm and restart theufmd.On the server running
ufmdthe system administrator should look to find the ufm config file,gv.cfg. It should be located at/opt/ufm/conf. In that file the system administrator may need to configure a few fields.The first field to check is
ws_protocol. This is how external programs, like CSM, communicate withufmd. It should be set tohttpsby default. But if it isn’t working, then try setting it tohttp.Example:
ws_protocol = httpIf CSM seems to be communicating with the
ufmdfine, but some of the managed switches are still not reporting modules, then the system administrator needs to look at another section of the ufm config file,gv.cfg. The next section to look at is[MLNX_OS]. This section deals with the OS that runs on managed switches.# default MLNX-OS access point for all Mellanox switches # important: this section parameters are used for ufm initialization only !!! # Please use ufm GUI/API for editing parameters values. [MLNX_OS] protocol = https port = 443 user = admin credentials = admin timeout = 10It has two fields that deal with how
ufmdcommunicates with the Mellanox OS. If , then try changing the protocol and port tohttpand80.protocol = http port = 80CSM should be able to openly communicate with UFM at this point. But as this is a system administrator and configuration issue, and not a CSM issue, please consult Mellanox and System Administrator support for resolution of this issue.
![digraph G {
DB_INIT -> DB_RECV_PRI [color="#993300" labelfontcolor="#993300" label="Privileged"];
DB_INIT -> DB_RECV_DB;
DB_RECV_PRI -> DB_RECV_DB;
DB_RECV_DB -> DB_DONE;
}](_images/graphviz-6ab376e306c41bf74467c8b0603d291ff48c0ecd.png)
![digraph G {
"Soft Failure" -> "Soft Failure" [label=" Retry"];
"Soft Failure" -> "In Service" [labelfontcolor="#009900" label="Recovery\nSuccess" color="#009900"];
"Soft Failure" -> "Hard Failure" [label=" Recovery\nFailure" color="#993300"];
"In Service" -> "Soft Failure" [label="Intermittent\nError" color="#993300"];
}](_images/graphviz-c7d1d9b87cdea675862015070dd4df0fd75f3584.png)
![digraph G {
User -> Utility;
Utility -> Master;
Master -> Utility;
Master -> Master;
Master -> "CSM Database";
"CSM Database" -> Master
Master -> Aggregator;
Aggregator -> Master;
Aggregator -> Compute;
Compute -> Aggregator;
User [shape=Mdiamond];
"CSM Database" [shape=cylinder];
}](_images/graphviz-c1e5f1105da4332847e27f7d6a201fe4d5701fe6.png)
Burst Buffer¶
The Burst Buffer is an I/O data caching technology which can improve I/O performance for a large class of high-performance computing applications without requirement of intermediary hardware. Using an SSD drive per compute node and NVMe over Fabrics, the burst buffer can asynchronously transfer data to or from the drive before the application reads a file or after it writes a file. The result is that the application benefits from native SSD performance for a portion of its I/O requests. Applications can create, read, and write data on the burst buffer using standard Linux file I/O system calls.
Burst Buffer provides:
- A fast storage tier between compute nodes and the traditional parallel file system
- Overlapping job stage-in and stage-out of data for checkpoint and restart
- Scratch volumes
- Extended memory I/O workloads
- Usage and SSD endurance monitoring
Table of Contents
Burst Buffer Installation¶
Preface¶
The document has been updated to reflect installing into Red Hat Enterprise Linux v8.1.
After the general outline of the install is a discussion of using supplied ansible playbooks to handle install, starting, stopping, and uninstalling burst buffer across the involved computing nodes.
When updating, clear the common metadata directory in the shared file system. A section with more details describes this.
Clear Metadata Directory on Updates¶
When updating the burst buffer installation and after the bbserver service is stopped, clear the metadata directory in the parallel file system
The metadata directory is “–metadata=<directory in parallel file system> as used in the bbactivate script. Searching for metadata in /etc/ibm/bb.cfg on the nodes with bbserver would show the path. For example: grep meta /etc/ibm/bb.cfg
“metadata” : “/gpfs/gpfs0/bbmetadata”,“bbserverMetadataPath” : “/gpfs/gpfs0/bbmetadata”,
where “metadata” is the value passed on bbactivate and “bbserverMetadataPath” is the bbserver services’ parallel file system path.
Pre-requisites¶
Red Hat Enterprise Linux v8.1 or later for POWER9 installed on the nodes.
- ibm-burstbuffer-1.x.y-z.ppc64le.rpm
- ibm-burstbuffer-lsf-1.x.y-z.ppc64le.rpm
- ibm-burstbuffer-mn-1.x.y-z.ppc64le.rpm
- ibm-csm-core-1.x.y-z.ppc64le.rpm
- ibm-export_layout-1.x.y-z.ppc64le.rpm
- ibm-flightlog-1.x.y-z.ppc64le.rpm
Security Certificates¶
The connection between bbProxy and bbServer is secured via a X.509 certificate. To create a certificate, the openssl tool can be used. For convenience, a provided bash script can be used: /opt/ibm/bb/scripts/mkcertificate.sh
This command will generate two files and only needs to be run on a single node:
-rw-r--r-- 1 root root cert.pem -rw------- 1 root root key.pemThe key.pem file is the private key and should be kept secret. We recommend copying this same file to /etc/ibm/key.pem on each of the bbServer nodes.
The cert.pem file should be copied to all bbServer and compute nodes. The cert.pem can be deployed to the compute nodes in a variety of ways. For example,
- cert.pem could be placed in shared GPFS storage.
- cert.pem could be placed in the xCAT compute image.
- cert.pem could be rsync’d/scp’d to each compute node after boot.
ESS I/O node VM setup¶
RPM installation¶
On each ESS I/O Node VM (or equivalent), install these RPMs:
- ibm-burstbuffer-1.x.y-z.ppc64le.rpm
- ibm-flightlog-1.x.y-z.ppc64le.rpm
The NVMe driver must be built with RDMA-enabled. Mellanox MOFED driver can do this via:
% mlnxofedinstall --with-nvmfSecurity Files¶
The cert.pem and key.pem files should ideally be placed in the /etc/ibm directory on each of the bbServer nodes. This can be done after the VM has been booted or during image creation.
Starting BB Services¶
The burst buffer server can be started through the following command issued on each ESS I/O node VM (or equivalent):
/opt/ibm/bb/scripts/bbactivate --serverThis command will use the default BB configuration file in the RPM (unless overridden by –config) and start the burst buffer server. It will also add the NVMe over Fabrics block device pattern to the global_filter in /etc/lvm/lvm.conf (unless the global filter line has already been modified)
Compute Node setup¶
RPM installation¶
On each Compute Node, install these RPMs:
- ibm-burstbuffer-1.x.y-z.ppc64le.rpm
- ibm-flightlog-1.x.y-z.ppc64le.rpm
- ibm-export_layout-1.x.y-z.ppc64le.rpm
- ibm-csm-core-1.x.y-z.ppc64le.rpm
The NVMe driver must be built with RDMA-enabled. Mellanox MOFED driver can do this via:
% mlnxofedinstall --with-nvmfSecurity Files¶
The cert.pem file should ideally be placed in the /etc/ibm directory on each of the compute nodes. This can be done after the node has been booted or during image creation. The private key (key.pem) should not be placed on the compute node.
Compute Node and ESS list generation¶
The burst buffer has a static assignment of compute nodes to bbServers. This relationship is defined by two files that are specified via the bbactivate tool.
The first file (nodelist) is a list of the xCAT names for all compute nodes – one compute node per line. E.g.,:
c650f07p23 c650f07p25 c650f07p27This nodelist could be generated via the xCAT commands: lsdef all | grep “Object name:” | cut -f 3 -d ‘ ‘
The second file (esslist) contains a list of IP addresses and ports for each bbServer. In the planned configuration, this would be the ESS I/O node VM IP address plus a well-known port (e.g., 9001). To express ESS redundancy, place the two ESS’s I/O nodes within the same ESS should be placed on the same line. E.g.,
20.7.5.1:9001 20.7.5.2:9001 20.7.5.3:9001 20.7.5.4:9001The esslist can also explicitly list the primary node first and then its backup. E.g.,
20.7.5.100:9001 backup=20.7.5.101:9001 20.7.5.101:9001 backup=20.7.5.100:9001
Starting BB Services¶
On each compute node, run the bbactivate tool:
$ /opt/ibm/bb/scripts/bbactivateRunning the bbServer on a different node than bbProxy requires a networked block device to be configured. If no block device is configured, the bbactivate script will attempt to establish an NVMe over Fabrics connection between the two nodes when bbProxy is started.
Whenever a compute node is rebooted or SSD is replaced, rerun the bbactivate tool.
Launch/Login Node setup¶
RPM installation¶
On each Launch/Login Node, install these RPMs: * ibm-burstbuffer-1.x.y-z.ppc64le.rpm * ibm-flightlog-1.x.y-z.ppc64le.rpm * ibm-csm-core-1.x.y-z.ppc64le.rpm * ibm-burstbuffer-lsf-1.x.y-z.ppc64le.rpm
The burstbuffer-lsf RPM also permits relocation:
$ rpm --relocate /opt/ibm/bb/scripts=$LSF_SERVERDIR …LSF Setup¶
Further LSF configuration should be performed to setup the data transfer queues. Please refer to the LSF installation documents for details. https://www.ibm.com/support/knowledgecenter/en/SSWRJV_10.1.0/lsf_csm/lsf_csm_burst_buffer_config.html
It is also recommended to add the following parameter to the lsf.conf file so that the burst buffer esub.bb and epsub.bb scripts are executed on job submission to setup key environment variables for $BBPATH and BSCFS: LSB_ESUB_METHOD=bb
BB Configuration¶
A directory is used to store job-specific bscfs metadata between job execution and job stage-out. Create a path in parallel file system for bscfs temporary files. The workpath should be accessible to all users.
A path is also needed to specify temporary storage for job-related metadata between the job submission through job stageout. It must be a location that can be written by the user and read by root, and accessible by nodes used for job submission and launch. It does not need to be accessible by the compute nodes. If the user home directories are readable by root, –envdir=HOME can be used.
For LSF configuration, several scripts need to be copied into $LSF_SERVERDIR. The files that need to be copied from /opt/ibm/bb/scripts are: esub.bb, epsub.bb, esub.bscfs, epsub.bscfs, bb_pre_exec.sh, and bb_post_exec.sh. The bbactivate script can automatically copy these files. Alternatively, the burstbuffer-lsf RPM is relocatable.
$. /opt/ibm/bb/scripts/bbactivate –ln –bscfswork=$BSCFSWORK –envdir=HOME –lsfdir=$LSF_SERVERDIR
Management Node setup (optional)¶
RPM installation¶
On the CSM Management Node, install this RPM: * ibm-burstbuffer-mn-1.x.y-z.ppc64le.rpm
Adding burst buffer RAS into CSM Database¶
RAS definitions for the Burst Buffer can be added to CSM postgres tables via the following command:
$ /opt/ibm/csm/db/csm_db_ras_type_script.sh -l csmdb /opt/ibm/bb/scripts/bbras.csvThis command should be executed on the CSM management node. The ibm-burstbuffer-mn RPM must also be installed on the management node.
If the RAS definitions are not added, the bbProxy log will show errors posting any RAS messages; however the errors are benign.
Stopping the Services¶
Stopping the burst buffer processes can be done via:
$ /opt/ibm/bb/scripts/bbactivate --shutdownTo teardown all NVMe over Fabrics connections, from each I/O Node use:
$ nvme disconnect –n burstbufferUsing BB Administrator Failover¶
There may be times in which the node running bbServer needs to be taken down for scheduled maintenance. The burst buffer provides a mechanism to dynamically change and migrate transfers to a backup bbServer. The backup bbServer is defined in the configuration file under backupcfg.
To switch to the backup server on 3 compute nodes cn1,cn2,cn3:
xdsh cn1,cn2,cn3 /opt/ibm/bb/scripts/setServer –server=backupTo switch back to the primary server on 3 compute nodes cn1,cn2,cn3:
xdsh cn1,cn2,cn3 /opt/ibm/bb/scripts/setServer –server=primaryIf submitting the switchover via an LSF job that runs as root, the –hosts parameter can be removed as setServer will use the compute nodes assigned by LSF.
Optional Configurations¶
Single node loopback (optional)¶
The bbProxy and bbServer can run on the same node, although this is development/bringup configuration (e.g., a bbAPI-using application development). In the ESS I/O node list would contain a line specifying loopback address (127.0.0.1:9001) for each compute node. Both lists need to have the same number of lines.
Configuring bbProxy without CSM (optional)¶
bbProxy can update CSM on the state of the logical volumes and emit RAS via CSM interfaces. This is automatically configured via the bbactivate tool.
/opt/ibm/bb/scripts/bbactivate --csm /opt/ibm/bb/scripts/bbactivate --nocsmThe default is to enable CSM
Configuring without Health Monitor (optional)¶
The burst buffer has an external process that can monitor the bbProxy->bbServer connection. If the connection becomes offline, the health monitor will either attempt to re-establish the connection, or (if defined) establish a connection with the backup server.
By default, bbactivate will start the burst buffer health monitor. This behavior can be changed via the –nohealth option to bbactivate:
/opt/ibm/bb/scripts/bbactivate --nohealthAnsible playbooks for burstbuffer¶
Install ibm-burstbuffer-ansible RPM on the machine where ansible-playbook will be run. The localhost needs to have connections to all the nodes involved in the cluster. Copy all the CAST RPMs into a directory in a parallel file system with the same mount across all the nodes in the cluster.
Inventory¶
Need an ansible inventory of hosts naming nodes by grouping: compute, where bbproxy daemon will reside with a local nvme drive and applications run; server, where bbserver daemon will run and conduct transfers between the compute nvme drive and GPFS; launch, where lsf jobs will be submitted and communication will take place with the compute node bbproxy daemons; and management, where management csm daemons reside.
An example inventory file: [compute] c650f06p25 c650f06p27 c650f06p29
[server] gssio1vm-hs backup=gssio2vm-hs gssio2vm-hs backup=gssio1vm-hs
[management] c650mnp03
[launch] c650mnp03 <EOF>
Install by ansible-playbook¶
Advice is to do these in order:
export RPMPATH=/gpfs/CAST/RPM export Inventory=/root/hosts export KEYFILE=/root/key.pem export CERTFILE=/root/cert.pem sudo ansible-playbook -f 16 -i $Inventory -e BBRPMDIR=$RPMPATH -e CSMRPMDIR=$RPMPATH /opt/ibm/bb/ansible/nodelist.yml sudo ansible-playbook -f 16 -i $Inventory -e BBRPMDIR=$RPMPATH -e CSMRPMDIR=$RPMPATH /opt/ibm/bb/ansible/bbserverIPlist.yml sudo ansible-playbook -f 16 -i $Inventory -e BBRPMDIR=$RPMPATH -e CSMRPMDIR=$RPMPATH /opt/ibm/bb/ansible/bbInstall.yml sudo ansible-playbook -f 16 -i $Inventory -e FQP_KEYFILE=$KEYFILE -e FQP_CERTFILE=$CERTFILE /opt/ibm/bb/ansible/certificates.yml
Activation by ansible-playbook¶
sudo ansible-playbook -f 16 -i $Inventory /opt/ibm/bb/ansible/bbStart.yml
Stop by ansible-playbook¶
sudo ansible-playbook -f 16 -i $Inventory /opt/ibm/bb/ansible/bbStop.yml
Uninstall playbooks¶
sudo ansible-playbook -f 16 -i $Inventory /opt/ibm/bb/ansible/bbUninstall.yml
Burst Buffer API¶
The burst buffer API is the interface between users and the burst buffer service. It allows users to define, start, cancel, and query information on their transfers. The API is also intended to be consistent with the bbCmd utility component that executes on the front-end nodes, allowing for inspection and modification of the burst buffer transfers during all stages of the job.
Burst Buffer Shared Checkpoint File System (BSCFS) uses the Burst Buffer APIs to allow shared (N:1 or N:M) checkpoints across multiple nodes to leverage node-local non-volatile storage.
Compilation¶
Adding the following options to the compile command-line should include bbAPI headers and library, as well as setting rpath to point to the bbAPI library. -I/opt/ibm -Wl,–rpath /opt/ibm/bb/lib -L/opt/ibm/bb/lib -lbbAPI
An example testcase can be built via: $ mpicc /opt/ibm/bb/tests/test_basic_xfer.c -o test_basic_xfer -I/opt/ibm -L/opt/ibm/bb/lib -Wl,–rpath=/opt/ibm/bb/lib -lbbAPI
Burst Buffer
BB_AddFiles¶
NAME¶
BB_AddFiles - Adds files to a transfer definition.
SYNOPSIS¶
#include <bb/include/bbapi.h>
int BB_AddFiles(BBTransferDef_t *transfer, const char *source, const char *target, BBFILEFLAGS flags)
DESCRIPTION¶
The BB_AddFiles routine adds a file or a directory to the transfer definition BB_StartTransfer() BB_StartTransfer() If source and target reside on the local SSD, may perform a synchronous ‘cp’. If source and target reside on GPFS, bbServer may perform a server-side ‘cp’ command rather than an NVMe over Fabrics transfer. All parent directories in the target must exist prior to call.
When adding a directory, all contents of the directory will be transferred to the target location. If BBRecursive flags is specified, then any subdirectories will be added. Only files present in the directories at the time of the BB_AddFiles call will be added to the transfer definition. Error code
param¶ transfer = Transfer definition
source = Full path to the source file location
target = Full path to the target file location
flags = Any flags for this file. (See BBFILEFLAGS for possible values.)
retval¶ 0 = Success
errno = Positive non-zero values correspond with errno. strerror() can be used to interpret.
BB_AddKeys¶
NAME¶
BB_AddKeys - Adds identification keys to a transfer definition.
SYNOPSIS¶
#include <bb/include/bbapi.h>
int BB_AddKeys(BBTransferDef_t *transfer, const char *key, const char *value)
DESCRIPTION¶
The BB_AddKeys routine allows the user to add a custom key-value to the transfer. Keys for the same tag are merged on the bbServer. If a key is a duplicate, the result is non-deterministic as to which value will prevail. Error code
param¶ transfer = Transfer definition
key = Pointer to string with the key name
value = Pointer to string with the key’s value
retval¶ 0 = Success
errno = Positive non-zero values correspond with errno. strerror() can be used to interpret.
BB_CancelTransfer¶
NAME¶
BB_CancelTransfer - Cancels an active file transfer.
SYNOPSIS¶
#include <bb/include/bbapi.h>
int BB_CancelTransfer(BBTransferHandle_t handle, BBCANCELSCOPE scope)
DESCRIPTION¶
The BB_CancelTransfer routine cancels an existing asynchronous file transfers specified by the transfer handle. When the call returns, the transfer has been stopped or an error has occurred. As part of the cancel, any parts of the files that have been transferred will have been deleted from the PFS target location. Error code
param¶ handle = Transfer handle from BB_StartTransfer. All transfers matching the tag will be canceled.
scope = Specifies the scope of the cancel. (See BBCANCELSCOPE for possible values.)
retval¶ 0 = Success
errno = Positive non-zero values correspond with errno. strerror() can be used to interpret.
BB_CreateTransferDef¶
NAME¶
BB_CreateTransferDef - Create storage for a transfer definition.
DESCRIPTION¶
BB_CreateTransferDef() The BB_CreateTransferDef routine creates storage for a transfer definition. The caller provides storage for BBTransferDef_t* and will allocate and initialize storage for BBTransferDef_t. Error code
param¶ transfer = User provides storage for BBTransferDef_t*
retval¶ 0 = Success
errno = Positive non-zero values correspond with errno. strerror() can be used to interpret.
BB_GetDeviceUsage¶
NAME¶
BB_GetDeviceUsage - Get NVMe SSD device usage.
SYNOPSIS¶
#include <bb/include/bbapi.h>
int BB_GetDeviceUsage(uint32_t devicenum, BBDeviceUsage_t *usage)
DESCRIPTION¶
The BB_GetDeviceUsage routine returns the NVMe device statistics. Error code
param¶ devicenum = The index of the NVMe device on the compute node
usage = The current NVMe device statistics
retval¶ 0 = Success
errno = Positive non-zero values correspond with errno. strerror() can be used to interpret.
BB_GetLastErrorDetails¶
NAME¶
BB_GetLastErrorDetails - Obtain error details of the last bbAPI call.
SYNOPSIS¶
#include <bb/include/bbapi.h>
int BB_GetLastErrorDetails(BBERRORFORMAT format, size_t *numAvailBytes, size_t buffersize, char *bufferForErrorDetails)
DESCRIPTION¶
The BB_GetLastErrorDetails routine provides contextual details of the last API call to help the caller determine the failure. The failure information is returned in a C string in the format specified by the caller. The last error details are . Each thread has its separate and distinct copy of a “last error” string. A thread invoking a burst buffer API will get a different “last error” string than another thread invoking burst buffer APIs. thread local
Only details from the last bbAPI call performed on that software thread are returned. If the process is multi-threaded, the error information is tracked separately between the threads. Error code
param¶ format = Format of data to return. (See BBERRORFORMAT for possible values.)
numAvailBytes = Number of bytes available to return
buffersize = Size of buffer
in/out] = bufferForErrorDetails Pointer to buffer
retval¶ 0 = Success
errno = Positive non-zero values correspond with errno. strerror() can be used to interpret.
BB_GetThrottleRate¶
NAME¶
BB_GetThrottleRate - Gets the transfer rate for a given tag.
SYNOPSIS¶
#include <bb/include/bbapi.h>
int BB_GetThrottleRate(const char *mountpoint, uint64_t *rate)
DESCRIPTION¶
The BB_GetThrottleRate routine retrieves the throttled transfer rate for the specified transfer handle. Actual transfer rate may vary based on file server load, congestion, other BB transfers, etc. Error code
param¶ mountpoint = compute node mountpoint to retrieve the throttle rate
rate = Current transfer rate throttle, in bytes-per-second
retval¶ 0 = Success
errno = Positive non-zero values correspond with errno. strerror() can be used to interpret.
BB_GetTransferHandle¶
NAME¶
BB_GetTransferHandle - Retrieves a transfer handle.
SYNOPSIS¶
#include <bb/include/bbapi.h>
int BB_GetTransferHandle(BBTAG tag, uint64_t numcontrib, uint32_t contrib[], BBTransferHandle_t *handle)
DESCRIPTION¶
The BB_GetTransferHandle routine retrieves a transfer handle based upon the input criteria. If this is the first request made for this job using the input tag and contrib values, a transfer handle will be generated and returned. Subsequent requests made for the job using the same input tag and contrib values will return the prior generated value as the transfer handle.
Transfer handles are associated with the current jobid and jobstepid. If numcontrib==1 and contrib==NULL, the invoker’s contributor id is assumed. Error code
param¶ tag = User-specified tag
numcontrib = Number of entries in the contrib[] array
contrib = Array of contributor indexes
handle = Opaque handle to the transfer
retval¶ 0 = Success
errno = Positive non-zero values correspond with errno. strerror() can be used to interpret.
BB_GetTransferInfo¶
NAME¶
BB_GetTransferInfo - Gets the status of an active file transfer.
SYNOPSIS¶
#include <bb/include/bbapi.h>
int BB_GetTransferInfo(BBTransferHandle_t handle, BBTransferInfo_t *info)
DESCRIPTION¶
The BB_GetTransferInfo routine gets the status of an active file transfer, given the transfer handle. If multiple files are being transferred within a tag, tags are tracked for the life of the associated job, and purged when the logical volume is removed.
Error code
param¶ handle = Transfer handle
info = Information on the transfer identified by the handle. Caller provides storage for BBTransferInfo_t.
retval¶ 0 = Success
errno = Positive non-zero values correspond with errno. strerror() can be used to interpret.
BB_GetTransferKeys¶
NAME¶
BB_GetTransferKeys - Gets the identification keys for a transfer handle.
SYNOPSIS¶
#include <bb/include/bbapi.h>
int BB_GetTransferKeys(BBTransferHandle_t handle, size_t buffersize, char *bufferForKeyData)
DESCRIPTION¶
The BB_GetTransferKeys routine allows the user to retrieve the custom key-value pairs for a transfer. The invoker of this API provides the storage for the returned data using the bufferForKeyData parameter. The buffersize parameter is input as the size available for the returned data. If not enough space is provided, then the API call fails. The format for the returned key-value pairs is JSON. Error code
param¶ handle = Opaque handle to the transfer
buffersize = Size of buffer
in/out] = bufferForKeyData Pointer to buffer
retval¶ 0 = Success
-1 = Failure
-2 = Key data not returned because additional space is required to return the data
BB_GetTransferList¶
NAME¶
BB_GetTransferList - Obtain the list of transfers.
SYNOPSIS¶
#include <bb/include/bbapi.h>
int BB_GetTransferList(BBSTATUS matchstatus, uint64_t *numHandles, BBTransferHandle_t array_of_handles[], uint64_t *numAvailHandles)
DESCRIPTION¶
The BB_GetTransferList routine obtains the list of transfers within the job that match the status criteria. BBSTATUS values are powers-of-2 so they can be bitwise OR’d together to form a mask (matchstatus). For each of the job’s transfers, this mask is bitwise AND’d against the status of the transfer and if non-zero, the transfer handle for that transfer is returned in the array_of_handles.
Transfer handles are associated with a jobid and jobstepid. Only those transfer handles that were generated for the current jobid and jobstepid are returned. If array_of_handles==NULL, then only the matching numHandles is returned. Error code
param¶ matchstatus = Only transfers with a status that match matchstatus will be returned. matchstatus can be a OR’d mask of several BBSTATUS values.
numHandles = Populated with the number of handles returned. Upon entry, contains the number of handles allocated to the array_of_handles.
array_of_handles = Returns an array of handles that match matchstatus. The caller provides storage for the array_of_handles and indicates the number of available elements in numHandles.
param¶ numAvailHandles = Populated with the number of handles available to be returned that match matchstatus.
retval¶ 0 = Success
errno = Positive non-zero values correspond with errno. strerror() can be used to interpret.
BB_GetUsage¶
NAME¶
BB_GetUsage - Get SSD Usage.
DESCRIPTION¶
The BB_GetUsage routine returns the SSD usage for the given logical volume on the compute node. When the LSF job exits, all logical volumes created under that LSF job ID will be queried to provide a summary SSD usage for the compute node. Error code
retval¶ 0 = Success
errno = Positive non-zero values correspond with errno. strerror() can be used to interpret.
BB_GetVersion¶
NAME¶
BB_GetVersion - Fetch the expected version string.
DESCRIPTION¶
The BB_GetVersion routine returns the expected version string for the API. This routine is intended for version mismatch debug. It is not intended to generate the string to pass into BB_InitLibrary. Error code
param¶ size = The amount of space provided to hold APIVersion
APIVersion = The string containing the bbAPI’s expected version.
retval¶ 0 = Success
errno = Positive non-zero values correspond with errno. strerror() can be used to interpret.
BB_InitLibrary¶
NAME¶
BB_InitLibrary - Initialize bbAPI.
SYNOPSIS¶
#include <bb/include/bbapi.h>
int BB_InitLibrary(uint32_t contribId, const char *clientVersion)
DESCRIPTION¶
The BB_InitLibrary routine performs basic initialization of the library. During initialization, it opens a connection to the local bbProxy. BBAPI_CLIENTVERSIONSTR Error code
param¶ contribId = Contributor Id
clientVersion = bbAPI header version used when the application was compiled.
retval¶ 0 = Success
errno = Positive non-zero values correspond with errno. strerror() can be used to interpret.
BB_SetThrottleRate¶
NAME¶
BB_SetThrottleRate - Sets the maximum transfer rate for a given tag.
SYNOPSIS¶
#include <bb/include/bbapi.h>
int BB_SetThrottleRate(const char *mountpoint, uint64_t rate)
DESCRIPTION¶
The BB_SetThrottleRate routine sets the upper bound on the transfer rate for the provided transfer handle. Actual transfer rate may vary based on file server load, congestion, other BB transfers, etc. Multiple concurrent transfer handles can each have their own rate, which are additive from a bbServer perspective. The bbServer rate won’t exceed the configured maximum transfer rate. Setting the transfer rate to zero will have the effect of pausing the transfer. Error code
param¶ mountpoint = compute node mountpoint to set a maximum rate
rate = New transfer rate, in bytes-per-second
retval¶ 0 = Success
errno = Positive non-zero values correspond with errno. strerror() can be used to interpret.
BB_SetUsageLimit¶
NAME¶
BB_SetUsageLimit - Sets the usage threshold.
SYNOPSIS¶
#include <bb/include/bbapi.h>
int BB_SetUsageLimit(const char *mountpoint, BBUsage_t *usage)
DESCRIPTION¶
The BB_SetUsageLimit routine sets the SSD usage threshold. When either usage->totalBytesRead or usage->totalBytesWritten is non-zero and exceeds the current threshold for the specified mount point, a RAS event will be generated. Error code
param¶ mountpoint = The path to the mount point that will be monitored
usage = The SSD activity limits that should be enforced
retval¶ 0 = Success
errno = Positive non-zero values correspond with errno. strerror() can be used to interpret.
BB_StartTransfer¶
NAME¶
BB_StartTransfer - Starts transfer of a file.
SYNOPSIS¶
#include <bb/include/bbapi.h>
int BB_StartTransfer(BBTransferDef_t *transfer, BBTransferHandle_t handle)
DESCRIPTION¶
The BB_StartTransfer routine starts an asynchronous transfer between the parallel file system and local SSD for the specified transfer definition. BB_StartTransfer will fail if the contribid for a process has already contributed to this tag. BB_StartTransfer will fail if the bbAPI process has an open file descriptor for one of the specified files. Error code
param¶ transfer = Pointer to the structure that defines the transfer
handle = Opaque handle to the transfer
retval¶ 0 = Success
errno = Positive non-zero values correspond with errno. strerror() can be used to interpret.
Burst Buffer Shared Checkpoint File System (BSCFS) APIs
BSCFS_AwaitLocalTransfer¶
NAME¶
BSCFS_AwaitLocalTransfer - Wait for a previously-started transfer to complete.
SYNOPSIS¶
#include <bscfs/include/bscfsAPI.h>
static int BSCFS_AwaitLocalTransfer(BBTransferHandle_t handle)
DESCRIPTION¶
BSCFS_AwaitLocalTransfer waits for a previously-started flush or prefetch operation to complete. The handle should be one that was returned by a prior call to BSCFS_StartLocalFlush or BSCFS_StartLocalPrefetch.
A successful call to BSCFS_AwaitLocalTransfer indicates that the current compute node’s contribution to a shared file has been incorporated into the actual file and associated mapfile on the PFS, or that the shared-file content directed to the local compute node is now available for reading. In either case, the completion refers only to file content transferred from or to the current node. It says nothing about other nodes’ transfers. Prefetches by different nodes are essentially independent, so there is never a need to coordinate them globally, but the story is different for flush operations. The application is responsible for ensuring that all nodes’ contributions to a shared file are transferred successfully before declaring the file complete. For a flush operation, BSCFS_AwaitLocalTransfer will fail with an error indication if the target file is in any state other than one of the FLUSHING-related states. It will also report an error if the transfer fails for any reason. BSCFS_AwaitLocalTransfer leaves the file in FLUSH_COMPLETED state after waiting for the local transfer to complete. For a prefetch operation, BSCFS_AwaitLocalTransfer will wait for the local transfer to complete and will then change the state of the target file from PREFETCHING to STABLE (unless it was already changed by a prior call). PREFETCHING and STABLE are the only states allowed by BSCFS_AwaitLocalTransfer for a prefetch. Prefetching differs from flushing in that there is no prefetching analog of the FLUSH_COMPLETED state. There is no requirement for global synchronization for prefetches, so the target file is considered STABLE as soon as the local prefetch completes. Error code
param¶ handle = handle that represents the awaited transfer
BSCFS_Forget¶
NAME¶
BSCFS_Forget - Release all resources associated with a BSCFS file.
DESCRIPTION¶
BSCFS_Forget releases all resources associated with the BSCFS file named pathname, and returns the file to INACTIVE state.
BSCFS_Forget attempts to clean up no matter the state in which it finds the pathname file. It will free any data buffers associated with the file, as well as the in-memory index, and it will unlink the SSD data and index files if they exist. If the file is FLUSHING or PREFETCHING, BSCFS_Forget will attempt to cancel the outstanding burst-buffer transfer. If the file is in FLUSH_PENDING state, its planned post-job flush will be suppressed. Error code
param¶ pathname = BSCFS file to be forgotten
BSCFS_GlobalFlushCompleted¶
NAME¶
BSCFS_GlobalFlushCompleted - Inform BSCFS that a flush operation has completed globally.
SYNOPSIS¶
#include <bscfs/include/bscfsAPI.h>
static int BSCFS_GlobalFlushCompleted(const char *pathname)
DESCRIPTION¶
BSCFS_GlobalFlushCompleted informs the local BSCFS instance that the transfer of the BSCFS file named pathname to the PFS has been completed by all participating nodes.
The application is responsible for ensuring that all its compute nodes’ contributions to a shared file are individually transferred and incorporated into the actual file in the PFS. Once it has done so, it must make a BSCFS_GlobalFlushCompleted call on every node to let the BSCFS instances know that the shared file is available for reading. The first call to BSCFS_GlobalFlushCompleted for a given file on any node should find the file in FLUSH_COMPLETED state. The call will change the state to STABLE, and subsequent calls, if any, will succeed without actually doing anything. BSCFS_GlobalFlushCompleted will fail with an error indication if the target file is found to be in INACTIVE, MODIFIED, FLUSH_PENDING, FLUSHING, or PREFETCHING state. Error code
param¶ pathname = BSCFS file to be prefetched
BSCFS_InstallInternalFiles¶
NAME¶
BSCFS_InstallInternalFiles - Activate a BSCFS file using the provided set of internal files.
SYNOPSIS¶
#include <bscfs/include/bscfsAPI.h>
static int BSCFS_InstallInternalFiles(const char *pathname, size_t files_length, const char *files, int state)
DESCRIPTION¶
BSCFS_InstallInternalFiles provides the names of a set of internal files that are to be associated with the BSCFS file named pathname. Files is an array of files_length bytes that holds a NULL-separated list of file names. The list should be terminated with a double NULL. The routine activates the target file in the given state.
The pathname file is expected to be INACTIVE when this call is made. For the initial implementation, files is expected to hold exactly two file names, an index file and a data file, in that order. BSCFS will incorporate the two internal files and activate the target file in the specified state, which should be either MODIFIED or STABLE. If the state is MODIFIED, the situation will be the same as if the application had written the data file content on the local compute node and not flushed it to the PFS. If the state is STABLE, the situation will be the same as if the application had prefetched the data file content from the PFS (or written and globally flushed it). WARNING: It is the responsibility of the caller to provide internal files that are properly formatted and internally consistent, and also to provide files that are consistent across nodes. For example, it would be an (undetected) error to establish a target file as MODIFIED on one node and STABLE on another. Error code
param¶ pathname = BSCFS file to be activated
files_length = size (in bytes) of the files array
files = space for provided file names
state = state of the activated file
BSCFS_PrepareLocalFlush¶
NAME¶
BSCFS_PrepareLocalFlush - Prepare for a transfer of a BSCFS file to the parallel file system.
SYNOPSIS¶
#include <bscfs/include/bscfsAPI.h>
static int BSCFS_PrepareLocalFlush(const char *pathname, const char *mapfile, const char *cleanup_script)
DESCRIPTION¶
BSCFS_PrepareLocalFlush prepares for, but does not initiate, a transfer to the PFS of any content cached locally for the BSCFS file named pathname, with information about this node’s contribution to the shared file to be added to mapfile. It causes transfer to be initiated from the FEN if this flush operation is still pending when the application terminates, and in that case it also causes cleanup_script to be invoked on the FEN when the transfer eventually completes.
The arguments and operation of BSCFS_PrepareLocalFlush are identical to those of BSCFS_StartLocalFlush defined in the previous section, except that the background transfer of the target file is not actually started and no handle is returned. The transfer will remain pending until either the target file is “forgotten” (see BSCFS_Forget) or the application terminates. In the latter case, the BSCFS stage-out script running on the FEN will initiate the transfer and invoke the cleanup script when it completes. BSCFS_PrepareLocalFlush leaves the target file in FLUSH_PENDING state, unless it was already in FLUSHING or FLUSH_COMPLETED state. Multiple calls to BSCFS_StartLocalFlush and BSCFS_PrepareLocalFlush for the same target file are allowed. The mapfile and cleanup_script provided with the first such call are the only ones that count. These parameters will be ignored for the second and subsequent calls for the same file. A call to BSCFS_StartLocalFlush can be used to initiate a pending transfer that was previously set up by BSCFS_PrepareLocalFlush. Error code
param¶ pathname = BSCFS file to be flushed
mapfile = mapfile to be created for this flush
cleanup_script = script to be executed on the FEN
BSCFS_QueryInternalFiles¶
NAME¶
BSCFS_QueryInternalFiles - Return the set of internal files associated with a BSCFS file.
SYNOPSIS¶
#include <bscfs/include/bscfsAPI.h>
static int BSCFS_QueryInternalFiles(const char *pathname, size_t files_length, char *files, int *state_p)
DESCRIPTION¶
BSCFS_QueryInternalFiles returns the names of the set of internal files associated with the BSCFS file named pathname. Files is an array of files_length bytes that is to be filled in with a NULL-separated list of file names. The list will be terminated with a double NULL. The routine also returns the current state of the file via the state_p pointer.
The pathname file should be in MODIFIED or STABLE state, or in any of the FLUSHING-related states. If necessary, any partially-filled data block will be appended to the SSD data file associated with the target file, and the index will be written out as a separate SSD file. The names of the index and data files, in that order, are copied into the files character array, assuming they fit in the space provided. The names are separated by a NULL character and terminated with a double NULL. Note that while the interface allows for an arbitrary number of internal files to be returned for a given target, in the initial implementation there will always be exactly two, and they will be listed with the index file first and the data file second. The current state of the target file (one of the states listed above) will be stored in the location indicated by state_p if the pointer is non-null. WARNING: It is the responsibility of the caller to ensure that the application does not write to the target file before the caller finishes accessing the internal files. Error code
param¶ pathname = BSCFS file to be queried
files_length = size (in bytes) of the files array
files = space for returned file names
state_p = returned state of the queried file
BSCFS_StartLocalFlush¶
NAME¶
BSCFS_StartLocalFlush - Initiate a transfer of a BSCFS file to the parallel file system.
SYNOPSIS¶
#include <bscfs/include/bscfsAPI.h>
static int BSCFS_StartLocalFlush(const char *pathname, const char *mapfile, const char *cleanup_script, BBTransferHandle_t *handle_p)
DESCRIPTION¶
BSCFS_StartLocalFlush initiates a transfer to the PFS of any content cached locally for the BSCFS file named pathname, and adds information about this node’s contribution to the shared file to mapfile. It causes cleanup_script to be invoked on the FEN if this flush is still in progress when the application terminates. It returns a handle via handle_p that can be used to query the transfer status.
Pathname should refer to a file in BSCFS, while mapfile should name a file in the PFS. Mapfile may be null, in which case no mapping information for this node will be recorded for this transfer. Mapfile will be created if it is not null and does not already exist. All nodes involved in a given flush operation should specify the same mapfile. Otherwise multiple, incomplete mapfiles will be created. The value returned in the location to which handle_p points can later be passed to BSCFS_AwaitLocalTransfer when the process needs to wait for the transfer to finish. The returned handle can also be used directly with burst-buffer infrastructure routines defined in <bbAPI.h> to modify or query the transfer. The pathname file must not be open in any process on the local compute node when the transfer is initiated. Typically, the file will be in MODIFIED state, and BSCFS_StartLocalFlush will change its state to FLUSHING. At this point BSCFS will append any partially-filled data block to the data file in the SSD, and it will write out the in-memory index as a separate SSD file. It will then initiate a transfer of the data and index files to the PFS by presenting the pair to the burst-buffer infrastructure as a BSCFS-type transfer bundle. If the target file is already in any of the FLUSHING-related states, the routine will simply return the handle representing the transfer that was already set up. It will first initiate the pending transfer and change the state to FLUSHING if the initial state was FLUSH_PENDING. It may seem logical to do nothing for a flush request that targets an INACTIVE file (because there is no local content that needs flushing), but in fact BSCFS will create an empty data file and index and then proceed to flush the empty files normally. The reason for this choice is that it allows a node to participate in the flush protocol even when it did not actually have anything to contribute to the shared file. Without this choice, the application would have to handle the “no contribution” situation as a special case, which might complicate its algorithm. Of course, the application is free to avoid unnecessary flushes if it is able to do so. A flush request that targets a PREFETCHING or STABLE file will fail with an error indication. If cleanup_script is not NULL, it should name a user-supplied program, accessible on the FEN, that may be invoked by the stage-out script after the job terminates. The script will be executed if and only if the transfer of the target file is still in progress when the application exits. If it is needed, cleanup_script will be invoked after all nodes’ outstanding flushes for the given target file are complete. It will be called with three arguments, the PFS names of the newly-transferred shared file and the associated mapfile, and a return code indicating whether the global transfer completed successfully. It is expected that all nodes will name the same cleanup script for a given target file, but if different scripts are named, each script will be invoked exactly once. Error code
param¶ pathname = BSCFS file to be flushed
mapfile = mapfile to be created for this flush
cleanup_script = script to be executed on the FEN
handle_p = handle that represents this flush
BSCFS_StartLocalPrefetch¶
NAME¶
BSCFS_StartLocalPrefetch - Initiate a prefetch of a BSCFS file from the parallel file system.
SYNOPSIS¶
#include <bscfs/include/bscfsAPI.h>
static int BSCFS_StartLocalPrefetch(const char *pathname, const char *mapfile, BBTransferHandle_t *handle_p)
DESCRIPTION¶
BSCFS_StartLocalPrefetch initiates a prefetch of the BSCFS file named pathname from the PFS to the local node, using mapfile to determine what parts of the file to transfer. It returns a handle via handle_p that can be used to query the transfer status.
Pathname should refer to a file in BSCFS, while mapfile should name a file in the PFS. The value returned in the location pointed to by handle_p can later be passed to BSCFS_AwaitLocalTransfer when the process needs to wait for the transfer to finish. The pathname file must not be open in any process on the local compute node when the BSCFS_StartLocalPrefetch call is issued. Typically, the file will be in INACTIVE state or already PREFETCHING, and it will be in PREFETCHING state as a result of the call. Initiating a prefetch on a STABLE file is not permitted, except in the case that a prefetch for the file has already been started AND awaited. In that case, the handle for the completed prefetch is returned, and the file remains STABLE. Prefetching a MODIFIED target file or one that is in any stage of FLUSHING is not permitted. To initiate a prefetch, BSCFS will construct a transfer bundle (of type “BSCFS”) that names the shared file and the specified mapfile as source files, and names local data and index files as targets. It will submit the bundle to the burst-buffer infrastructure and return the handle that represents the transfer to the caller. Note that a call to BSCFS_StartLocalPrefetch results only in the transfer of shared-file content destined for the local compute node, as specified by the named mapfile. Separate transfers must be initiated on each compute node to which content is directed. For prefetching, there is no requirement that the same mapfile be used on all compute nodes. Error code
param¶ pathname = BSCFS file to be prefetched
mapfile = mapfile to be used to direct this prefetch
handle_p = handle that represents this prefetch
Burst Buffer Commands¶
The Burst Buffer services can be accessed from the Front End Node (FEN) via the bbcmd tool. It allows checkpoint libraries, such as SCR, to dynamically determine which file(s) to transfer between GPFS and the compute node’s local SSD and to start/stop/query transfers. It also allows for privileged users to manage SSD logical volumes and query hardware state.
Tools
bbcmd¶
NAME¶
bbcmd - perform burst buffer user commands
SYNOPSIS¶
bbcmd [COMMAND] …
DESCRIPTION¶
The Burst Buffer services can be accessed from the Launch and Login nodes via the bbCmd tool. It allows checkpoint libraries, such as SCR, to dynamically determine which file(s) to transfer between GPFS and the compute node’s local SSD and to start/stop/query transfers. It also allows for privileged users to manage SSD logical volumes and query hardware state.
OUTPUT¶
The bbCmd tool will wait until a response is received from the service. For each command, multiple types of data may be returned from the call. Since higher levels of software, such as SCR, plan to provide additional tooling that may depend on responses from bbCmd, it is important to ensure that the output from bbCmd is easily machine parseable. By default, the output from bbCmd will be returned in JSON format. The toplevel hierarchy of the JSON output will be a target identifier sufficiently precise to identify individual job or job step components. This allows for multiple job components (e.g. MPI ranks) to be targeted by a single command, and yet keep the returned data separate for subsequent parsing. If desired, bbCmd can alternatively output in XML format (–xml) or a more human-readable pretty printed format (–pretty). All commands will return an attribute called ‘rc’. This contains the result code of the operation. Zero indicates success and a non zero value indicates command failure.
- –help
Helptext display for commands and options
- –config
Path to the JSON configuration file
- –jobid
Job ID with respect to the workload manager
- –jobstepid
Job step ID with respect to the workload manager
- –contribid
(internal) The contributor ID of the local bbcmd.
- –target
List of ranks that the command will target. The rank number determines the target compute node. The –target field can take a comma-separated list of indices. Start/Stop ranges can also be specified.
Examples:
—target=0,1 –target=0,1,2,3 –target=0-3 –target=0,1,4-7 –target=0-
- –hostlist
Comma-seperated list of hostnames.
- –pretty
Output in human-readable format
- –xml
Output in XML formatCommands¶
cancel¶
The cancel command takes a transfer handle and cancels the transfer.
- –scope
Scope of the cancel:
BBSCOPETAG = Cancel impacts all transfers associated by the tag,
BBSCOPETRANSFER = Cancel only impacts the local contribution
- –handle
Transfer handle to be cancelledchmod¶
The chmod command takes a path to a file and changes the file permissions.
- –path
Path of the file to chmod
- –mode
New chmod modechown¶
The chown command takes a path to a file and changes the file’s owner and group.
- –path
Path of the file to chown
- –user
Specifies the file’s new owner
- –group
Specifies the file’s new groupcopy¶
The copy command takes a filelist and starts a copy on the target nodes specified by –target. The filelist points to a tab delimited file with the following format:
- –filelist
Path to a file descripting the source and target paths for the transfer. The file contains 1 line per source/target path pair in the following format:
<source> <destination> <flags>
- –handle
Transfer handle to associate with the transfercreate¶
The create command takes a mount point, size, and options to create a logical volume. A file system is created on the logical volume and mounted. Requires super user credentials.
- –mount
Path to the mountpoint
- –size
Size is in units of megabytes unless specified in the suffix. A size suffix of B for bytes, S for sectors, M for megabytes, G for gigabytes, T for terabytes, P for petabytes or E for exabytes is optional.
- –coptions
LV creation options: BBEXT4, BBXFS, BBFSCUSTOM1, BBFSCUSTOM2, BBFSCUSTOM3, BBFSCUSTOM4getdeviceusage¶
The getdeviceusage command takes the device index and returns NVMe specific data on the state of the SSD.
- –device
The NVMe device index to be queried on the compute node.getfileinfo¶
Returns active file transfers for a bbproxy daemon. Requires super user credentials.
getstatus¶
The getstatus command takes a transfer handle and returns details about the current status of the specified transfer.
- –handle
Transfer handle to be queriedgetthrottle¶
The getthrottle command takes a mount point and returns the goal transfer rate. The goal transfer rate refers to the bbServer rate that demand fetches or writes will be issued to the parallel file system.
- –mount
Mount point to be queried for the throttle rate (in bytes per second)gettransferkeys¶
The gettransferkeys command takes a transfer handle and returns all of the associated transfer keys.
- –handle
Transfer handle to be queried
- –buffersize
Maximum buffer size to retrievegettransfers¶
The gettransfers command takes a comma separated list of transfer statuses and returns all the transfer handles that currently have a status in the list. Only transfer handles associated with the job will be returned.
- –matchstatus
Match status values: BBNOTSTARTED = Transfer not started, BBINPROGRESS = Transfer in-progress, BBPARTIALSUCCESS = Partially successful transfer, BBFULLSUCCESS = Successful transfer, BBCANCELED = Canceled transfer, BBFAILED = Failed transfer, BBSTOPPED = Stopped transfer, BBALL = All transfers
- –numhandles
Number of handles to retrievegetusage¶
The getusage command takes a mount point and returns the current statistics of I/O activity performed to that mount point.
- –mount
Mount point to query for usage statisticsremove¶
The remove command takes a mount point and removes the logical volume. This returns the associated storage for the logical volume back to the burst buffer volume group. Requires super user credentials.
- –mount
Mount point to removeremovejobinfo¶
The removejobinfo command removes the metadata associated with a job from the bbServers. Requires super user credentials.
resize¶
The resize command takes a mount point, new size, and options to resize a logical volume and its file system. Requires super user credentials.
- –mount
Mount point to resize
- –size
Size is in units of megabytes unless specified in the suffix. A size suffix of B for bytes, S for sectors, K for kilobytes, M for megabytes, G for gigabytes, T for terabytes, P for petabytes or E for exabytes is optional. A leading ‘-’ or ‘+’ sign makes the resize operation relative to the current size and not absolute.
- –roptions
The parameter is optional. If not specified, roptions will default to BB_NONE.
BB_NONE BB_DO_NOT_PRESERVE_FS
resizelglvol¶
The resizelglvol command takes a logical volume name and new size to resize a logical volume. It can be used to further shrink a logical volume whose file system was unmounted and not preserved by a previous resize command.
Requires super user credentials.
- –lglvol
LV logical volume name.
- –size
Size is in units of megabytes unless specified in the suffix. A size suffix of B for bytes, S for sectors, K for kilobytes, M for megabytes, G for gigabytes, T for terabytes, P for petabytes or E for exabytes is optional. A leading ‘-’ or ‘+’ sign makes the resize operation relative to the current size and not absolute.setthrottle¶
The setthrottle command takes a transfer handle and sets the goal transfer rate. The goal transfer rate refers to the bbServer rate that demand fetches or writes will be issued to the parallel file system.
- –mount
Mount point to be modified
- –rate
Maximum transfer rate (in bytes per second) for the mount pointsetusagelimit¶
The setusagelimit command takes a mount point and read and/or write limits and monitors the SSD. If the activity exceeds the set limit, a RAS event will be generated. Requires super user credentials.
- –mount
Mount point to monitor
- –rl
The read limit
- –wl
The write limitbbactivate¶
NAME¶
bbactivate - setup burst buffer on the node
SYNOPSIS¶
/opt/ibm/bb/scripts/bbactivate –cn
/opt/ibm/bb/scripts/bbactivate –ln –bscfswork=/gpfs/gpfs0/bscfswork –envdir=HOME –lsfdir=$LSF_SERVERDIR
/opt/ibm/bb/scripts/bbactivate –server –metadata=/gpfs/gpfs0/bbmetadata
DESCRIPTION¶
For a compute node (–cn), it will setup an NVMe over Fabrics target, configuration files, and start bbProxy. bbProxy will then attempt to connect to either its primary or backup bbServer.
For a server node (–server), it will setup the configuration files and start bbServer
For a launch node (–ln), it will setup the configuration files for bbcmd.
Files:¶
bbactivate will by default generate a configuration file in /etc/ibm/bb.cfg. This configuration file will be consumed by burst buffer services when the service is started.
- esslist (Compute Node)
The esslist file contains a list of IP addresses and ports for each bbServer. In the planned configuration, this would be the ESS I/O node VM IP address plus a well-known port (e.g., 9001). To express ESS redundancy, place the two ESS’s I/O nodes within the same ESS should be placed on the same line. The default location for the esslist file is /etc/ibm/esslist. The default can be overridden using the –esslist option.
- nodelist (Compute Node)
The nodelist file is a list of the xCAT names for all compute nodes - one compute node per line. The default location for the nodelist file is /etc/ibm/nodelist. The default can be overridden using the –nodelist option.
- X.509 Security Certificate (Compute and I/O nodes)
An X.509 certificate file (e.g., cert.pem) must be placed on all bbServer and compute nodes. The default location for the certificate file is /etc/ibm/cert.pem. The default can be overridden using the –sslcert option.
- X.509 Security Private Key (I/O nodes)
An X.509 private key must be placed on all bbServer nodes to authenticate incomming requests from the compute node(s). The default location for the private key is /etc/ibm/key.pem. The default can be overridden using the –sslpriv option.Generic options:¶
- –configtempl
Path to a file containing a customized bb.cfg template. The default path is /opt/ibm/bb/scripts/bb.cfg
- –outputconfig
Path to the location file to write the burst buffer configuration file. The default path is /etc/ibm/bb.cfg
- –[no]csm
Enable or disable utilizing CSM infrastructure. CSM agents must be active on the node in order to use CSM.
On login/launch node, CSM infrastructure will be used to send bbcmd rather than using passwordless ssh. On bbProxy, volume group and logical volumes will be tracked in CSM databases. RAS messages will also be sent to CSM.
- –shutdown
Shutdown all burst buffer services running on the node.
- –sslcert
Path to the X.509 security certificate used to authenticate the connection between bbProxy and bbServer.
- –sslpriv
Path to the X.509 security private key used to authenticate the connection between bbProxy and bbServer.
- –skip
This parameter allow skipping one or more steps of the bbactivate sequence, comma-separated. Steps: config,lsf,lvm,nvme,start,health,cleanup
- –dryrun
bbactivate will output the commands that it would run, but it will not modify the system state. Configuration files that would have been written are instead sent to stdout unless –drypath is specified.
- –drypath
When used in combination with –dryrun, the file system changes will be written to file(s) in the directory specified by –drypath instead of the actual file locations.
- –scriptpath
Specifies an alternative path for the default configuration file locations.
- –help
Displays the bbactivate man pageCompute Node specific options:¶
- –[no]cn
Specifies bbactivate should configure burst buffer on the compute node.
- –nodelist
Path to a file containing a list of compute nodes in the cluster. This node list will be used with the esslist to statically assign the primary and backup bbServer nodes for the compute node that is executing bbactivate.
The format of the nodelist should be a xCAT hostname per line.
The default path is /etc/ibm/nodelist
- –esslist
Path to a file containing a list of bbServer IP addresses in the cluster. This ESS list will be used with the nodelist to statically assign the primary and backup bbServer nodes for the compute node that is executing bbactivate.
The format of the esslist should be one or two IP address per line. Multiple addresses on the line are treated as redundant backups to each other.
The default path is /etc/ibm/esslist
- –nvmetempl
Path to a file containing a customized NVMe over Fabrics JSON template. The default path is /opt/ibm/bb/scripts/nvmet.json
- –[no]offload
Enable or disable NVMe over Fabrics hardware target offload support. Target offload is disabled by default.
- –[no]health
Specifies bbactivate should configure burst buffer health monitor on the compute node.Server node options:¶
- –[no]server
Specifies bbactivate should configure burst buffer on the server node.
- –metadata
Specifies the metadata directory used by the bbServer instances. All bbServer nodes in the cluster must point to the same directory.Login/Launch node options:¶
- –[no]ln
Specifies bbactivate should configure burst buffer on the login/launch node.
- –envdir
Specifies the scratch directory to store user temporary files used for communicating between stage-in, running, and stage-out phases of an LSF job. The path should be accessible by both the user and root. If –envdir=HOME, then the user’s home directory (as indicated by getpwnam) will be used.
- –lsfdir
When specified, bbactivate will update the LSF’s etc/ directory with the esub/epsub and bb pre/post exec scripts. Normally, this would be –lsfdir=$LSF_SERVERDIR
- –bscfswork
Specifies the scratch directory for BSCFS temporary files for communicating between the job on the compute node with the BSCFS stage-out scripts regarding pending transfers.bbconnstatus¶
NAME¶
bbconnstatus - display bbProxy active connection
SYNOPSIS¶
/opt/ibm/bb/scripts/bbconnstatus
DESCRIPTION¶
Command that can be executed on the compute node in order to determine the current status of the bbProxy->bbServer connection. The output from the command will be either primary, backup, no_connection, bbProxy_might_be_down, or unknownServer. Optimal burst buffer performance should occur when the active connection is at primary. Backup indicates that the node is in a failover state. No connection indicates that the burst buffer service is not currently functional. Unknown could occur if the administrator fails over to a bbServer other than the designated primary or backup. This is an unusual situation.
- -v
Enables verbose outputsetServer¶
NAME¶
setServer - modifies the current active bbServer used by bbProxy
SYNOPSIS¶
/opt/ibm/bb/scripts/setServer
DESCRIPTION¶
The burst buffer setServer utility provides a means to change the connection between bbProxy and bbServer. This can be used for defining
- –server
This option sets the name of the server. For non-drain, setServer will switch bbProxy to the server. For drain, it will switch-away from the server if needed.
- –[no]drain
Drain will move any bbProxy that is currently using the specified ‘server’ to switch away onto its backup (or return to primary, if backup is already active)
- -v
Enables verbose outputDaemons
bbProxy¶
NAME¶
bbProxy - burst buffer proxy process for the compute nodes
SYNOPSIS¶
bbProxy [–help] [–whoami=string] [–instance=value] [–config=path]
DESCRIPTION¶
The bbProxy is a burst buffer component that runs on each compute node. It connects all the programs running on the compute node using the bbAPI to bbServer processes running on the ESS I/O nodes.
- –help
Display the help text
- –whoami
Identifies the name of the bbProxy configuration.
- –instance
Unused
- –config
Path to the JSON configuration file.bbServer¶
NAME¶
bbServer - burst buffer server process for the I/O nodes
SYNOPSIS¶
bbServer [–help] [–whoami=string] [–instance=value] [–config=path]
DESCRIPTION¶
The bbServer is a persistent process running on each of the ESS I/O nodes. The role of the bbServer is to push or pull traffic from the SSDs, track status of transfers, and to handle requests from the bbProxy or other bbServers.
- –help
Display the help text
- –whoami
Identifies the name of the bbServer configuration.
- –instance
Unused
- –config
Path to the JSON configuration file.bbhealth¶
NAME¶
bbhealth - monitor bbProxy on the compute nodes
DESCRIPTION¶
bbhealth is a utility that runs in the background and monitors the health of the bbProxy connection to its active bbServer. If the connection were to close or fail, bbhealth will react by attempting to repeatedly alternate re-connection attempts to either its primary or backup bbServer. The primary and backup bbServers are designated in the burst buffer configuration file.
bbhealth will periodically poll the bbProxy connection. This poll rate is settable via the –pollrate option. Each query will be executed at the poll interval at the start of the second.
- –pollrate
Specifies the polling rate that bbhealth uses to query bbProxy’s connection status. The pollrate is in seconds, the default is 30. During multiple consecutive failures, the delay between polls is exponentially increased until –maxsleep is reached.
- –maxsleep
Specifies the maximum delay between polling events that bbhealth uses to query bbProxy’s connection status. –maxsleep is in seconds, the default is 3600.
- -v
Enables verbose output
Big Data Store¶
CAST supports the integration of the ELK stack as a Big Data solution. Support for this solution is bundled in the csm-big-data rpm in the form of suggested configurations and support scripts.
Configuration order is not strictly enforced for the ELK stack, however, this resource generally assumes the components of the stack are installed in the following order:
- Elasticsearch
- Kibana
- Logstash
This installation order minimizes the likelihood of improperly ingested data being stored in elasticsearch.
Warning
If the index mappings are not created properly timestamp data may be improperly stored. If this occurs the user will need to reindex the data to fix the problem. Please read the elasticsearch section carefully before ingesting data.
Attention
It is recommended to review Common Big Data Store Problems before installing the stack.
Elasticsearch¶
Elasticsearch is a distributed analytics and search engine and the core component of the ELK stack. Elastic search ingests structured data (typically JSON or key value pairs) and stores the data in distributed index shards.
In the CAST design the more Elasticsearch nodes the better. Generally speaking nodes with attached storage or large numbers of drives are prefered.
Configuration¶
Note
This guide has been tested using Elasticsearch 6.8.1, the latest RPM may be downloaded from the Elastic Site.
The following is a brief introduction to the installation and configuration of the elasticsearch service. It is generally assumed that elasticsearch is to be installed on multiple Big Data Nodes to take advantage of the distributed nature of the service. Additionally, in the CAST configuration data drives are assumed to be JBOD.
CAST provides a set of sample configuration files in the repository at csm_big_data/elasticsearch/
If the ibm-csm-bds-*.noarch.rpm rpm as been installed the sample configurations may be found
in /opt/ibm/csm/bigdata/elasticsearch/.
- Install the elasticsearch rpm and java 1.8.1+ (command run from directory with elasticsearch rpm):
yum install -y elasticsearch-*.rpm java-1.8.*-openjdk
Copy the Elasticsearch configuration files to the /etc/elasticsearch directory.
It is recommended that the system administrator review these configurations at this phase.
jvm.options: jvm options for the Elasticsearch service. elasticsearch.yml: Configuration of the service specific attributes, please see elasticsearch.yml for details. Make an ext4 filesystem on each hard drive designated to be in the Elasticsearch JBOD.
The mounted names for these file systems should match the names specified in path.data. Additionally, these mounted file systems should be owned by the
elasticsearchuser and in theelasticsearchgroup.Start Elasticsearch:
systemctl enable elasticsearch
systemctl start elasticsearch
- Run the index template creator script:
/opt/ibm/csm/bigdata/elasticsearch/createIndices.sh
Note
This is technically optional, however, data will have limited use. This script configures Elasticsearch to properly parse timestamps.
Elasticsearch should now be operational. If Logstash was properly configured there should already be data being written to your index.
Tuning Elasticsearch¶
The process of tuning and configuring Elasticsearch is incredibly dependent on the volume and type of data ingested the Big Data Store. Due to the nuance of this process it is STRONGLY recommended that the system administrator familiarize themselves with Configuring Elasticsearch.
The following document outlines the defaults and recommendations of CAST in the configuration of the Big Data Store.
elasticsearch.yml¶
Note
The following section outline’s CAST’s recommendations for the Elasticsearch configuration it is STRONGLY recommended that the system administrator familiarize themselves with Configuring Elasticsearch.
The Elasticsearch configuration sample shipped by CAST marks fields that need to be set by a system administrator. A brief rundown of the fields to modify is as follows:
| cluster.name: | The name of the cluster. Nodes may only join clusters with the name in this field. Generally it’s a good idea to give this a descriptive name. |
|---|---|
| node.name: | The name of the node in the elasticsearch cluster.
CAST defaults to ${HOSTNAME}. |
| path.log: | The logging directory, needs elasticsearch read write access. |
| path.data: | A comma separated listing of data directories, needs elasticsearch read write access. CAST recommends a JBOD model where each disk has a file system. |
| network.host: | The address to bind the Elasticsearch model to.
CAST defaults to _site_. |
| http.port: | The port to bind Elasticsearch to.
CAST defaults to 9200. |
| discovery.zen.ping.unicast.hosts: | |
A list of nodes likely to be active, comma delimited array.
CAST defaults to cast.elasticsearch.nodes. |
|
| discovery.zen.minimum_master_nodes: | |
Number of nodes with the node.master setting set to true that must be connected to
before starting.
Elastic search recommends (master_eligible_nodes/2)+1. |
|
| gateway.recover_after_nodes: | |
| Number of nodes to wait for before begining recovery after cluster-wide restart. | |
| xpack.ml.enabled: | |
| Enables/disables the Machine Learning utility in xpack, this should be disabled on ppc64le installations. | |
| xpack.security.enabled: | |
| Enables/disables security in elasticsearch. | |
| xpack.license.self_generated.type: | |
Sets the license of xpack for the cluster, if the user has no license it should be set to basic. |
|
jvm.options¶
The configuration file for the Logstash JVM. The supplied settings are CAST’s recommendation, however, the efficacy of these settings entirely depends on your elasticsearch node.
Generally speaking the only field to be changed is the heap size:
-Xms[HEAP MIN]
-Xmx[HEAP MAX]
Indices¶
| Elasticsearch Templates: | |
|---|---|
| /opt/ibm/csm/bigdata/elasticsearch/templates/cast-*.json | |
CAST has specified a suite of data mappings for use in separate indices. Each of these indices is documented below, with a JSON mapping file provided in the repository and rpm.
CAST uses cast-<class>-<description>-<date> naming schema for indices to leverage templates when creating
the indices in Elasticsearch. The class is one of the three primary classifications determined
by CAST: log, counters, environmental. The description is typically a one to two word description
of the type of data: syslog, node, mellanox-event, etc.
A collection of templates is provided in ibm-csm-bds-*.noarch.rpm which sets up aliases and data type mappings.
These temlates do not set sharding or replication factors, as these settings should be tuned to
the user’s data retention and index sizing needs.
The specified templates match indices generated in the data aggregators documentation. As different data sources produce different volumes of data in different environments, this document will make no recommendation on sharding or replication.
Note
These templates may be found on the git repo at csm_big_data/elasticsearch/mappings/templates.
Note
Cast has elected to use lowercase and - characters to separate words. This is not mandatory for your index naming and creation.
scripts¶
| Elasticsearch Index Scripts: | |
|---|---|
| /opt/ibm/csm/bigdata/elasticsearch/ | |
CAST provides a set of scripts which allow the user to easily manipulate the elasticsearch indices from the command line.
createIndices.sh¶
A script for initializing the templates defined by CAST. When executed it with attempt to
target the elasticsearch server running on ${HOSTNAME}:9200. If the user supplies
either a hostname or ip address this will be targeted in lieu of ${HOSTNAME}. This script
need only be run once on a node in the elasticsearch cluster.
removeIndices.sh¶
A script for removing all elasticsearch templates created by createIndices.sh.
When executed it with attempt to target the elasticsearch server running on ${HOSTNAME}:9200.
If the user supplies either a hostname or ip address this will be targeted in lieu of ${HOSTNAME}.
This script need only be run once on a node in the elasticsearch cluster.
reindexIndices.py¶
Attention
This script is currently not supported, a future release of CSM BDS will have a script matching this description.
A tool for performing in place reindexing of an elasticsearch index.
Warning
This script should only be used to reindex a handful of indices at a time as it is slow and can result in partial reindexing.
usage: reindexIndices.py [-h] [-t hostname:port]
[-i [index-pattern [index-pattern ...]]]
A tool for reindexing a list of elasticsearch indices, all indices will be
reindexed in place.
optional arguments:
-h, --help show this help message and exit
-t hostname:port, --target hostname:port
An Elasticsearch server to reindex indices on. This
defaults to the contents of environment variable
"CAST_ELASTIC".
-i [index-pattern [index-pattern ...]], --indices [index-pattern [index-pattern ...]]
A list of indices to reindex, this should use the
index pattern format.
cast-log¶
| Elasticsearch Templates: | |
|---|---|
| /opt/ibm/csm/bigdata/elasticsearch/templates/cast-log*.json | |
The cast-log- indices represent a set of logging indices produced by CAST supported data sources.
cast-log-syslog¶
| alias: | cast-log-syslog |
|---|
The syslog index is designed to capture generic syslog messages. The contents of the syslog index is considered by CAST to be the most useful data points for syslog analysis. CAST supplies both an rsyslog template and Logstash pattern, for details on these configurations please consult the data aggregators documentation.
The mapping for the index contains the following fields:
| Field | Type | Description |
|---|---|---|
| @timestamp | date | The timestamp of the message, generated by the syslog utility. |
| host | text | The host of the relay host. |
| hostname | text | The hostname of the syslog origination. |
| program_name | text | The name of the program which generated the log. |
| process_id | long | The process id of the program which generated the log. |
| severity | text | The severity level of the log. |
| message | text | The body of the message. |
| tags | text | Tags containing additional metadata about the message. |
Note
Currently mmfs and CAST logs will be stored in the syslog index (due to similarity of the data mapping).
cast-log-mellanox-event¶
| alias: | cast-log-mellanox-event |
|---|
The mellanox event log is a superset of the cast-log-syslog index, an artifact of the event log being transmitted through syslog. In the CAST Big Data Pipeline this log will be ingested and parsed by the Logstash service then transmitted to the Elasticsearch index.
| Field | Type | Description |
|---|---|---|
| @timestamp | date | When the message was written to the event log. |
| hostname | text | The hostname of the ufm aggregating the events. |
| program_name | text | The name of the generating program, should be event_log |
| process_id | long | The process id of the program which generated the log. |
| severity | text | The severity level of the log, pulled from message. |
| message | text | The body of the message (unstructured). |
| log_counter | long | A counter tracking the log number. |
| event_id | long | The unique identifier for the event in the mellanox event log. |
| event_type | text | The type of event (e.g. HARDWARE) in the event log. |
| category | text | The categorization of the error in the event log typing |
| tags | text | Tags containing additional metadata about the message. |
cast-log-console¶
| alias: | cast-log-console |
|---|
CAST recommends the usage of the goconserver bundled in the xCAT dependicies, documented in xCat-GoConserver. Configuration of the goconserver should be performed on the xCAT service nodes in the cluster. CAST has created a limited configuration guide <ConsoleDataAggregator>, please consult for a basic rundown on the utility.
The mapping for the console index is provided below:
| Field | Type | Description |
|---|---|---|
| @timestamp | date | When console event occured. |
| type | text | The type of the event (typically console). |
| message | text | The console event data, typically a console line. |
| hostname | text | The hostname generating the console. |
| tags | text | Tags containing additional metadata about the console log. |
cast-csm¶
| Elasticsearch Templates: | |
|---|---|
| /opt/ibm/csm/bigdata/elasticsearch/templates/cast-csm*.json | |
The cast-csm- indices represent a set of metric indices produced by CSM. Indices matching this pattern will be created unilaterally by the CSM Daemon. Typically records in this type of index are generated by the Aggregator Daemon.
cast-csm-dimm-env¶
| alias: | cast-csm-dimm-env |
|---|
The mapping for the cast-csm-dimm-env index is provided below:
| Field | Type | Description |
|---|---|---|
| @timestamp | date | Ingestion time of the dimm environment counters. |
| timestamp | date | When environment counters were gathered. |
| type | text | The type of the event (csm-dimm-env). |
| source | text | The source of the counters. |
| data.dimm_id | long | The id of dimm being aggregated. |
| data.dimm_temp | long | The temperature of the dimm. |
| data.dimm_temp_max | long | The max temperature of the dimm over the collection period. |
| data.dimm_temp_min | long | The min temperature of the dimm over the collection period. |
cast-csm-gpu-env¶
| alias: | cast-csm-gpu-env |
|---|
The mapping for the cast-csm-gpu-env index is provided below:
| Field | Type | Description |
|---|---|---|
| @timestamp | date | Ingestion time of the gpu environment counters. |
| timestamp | date | When environment counters were gathered. |
| type | text | The type of the event (csm-gpu-env). |
| source | text | The source of the counters. |
| data.gpu_id | long | The id of the GPU record being aggregated. |
| data.gpu_mem_temp | long | The memory temperature of the GPU. |
| data.gpu_mem_temp_max | long | The max memory temperature of the GPU over the collection period. |
| data.gpu_mem_temp_min | long | The min memory temperature of the GPU over the collection period. |
| data.gpu_temp | long | The temperature of the GPU. |
| data.gpu_temp_max | long | The max temperature of the GPU over the collection period. |
| data.gpu_temp_min | long | The min temperature of the GPU over the collection period. |
cast-csm-node-env¶
| alias: | cast-csm-node-env |
|---|
The mapping for the cast-csm-node-env index is provided below:
| Field | Type | Description |
|---|---|---|
| @timestamp | date | Ingestion time of the node environment counters. |
| timestamp | date | When environment counters were gathered. |
| type | text | The type of the event (csm-node-env). |
| source | text | The source of the counters. |
| data.system_energy | long | The energy of the system at ingestion time. |
cast-csm-gpu-counters¶
| alias: | cast-csm-gpu-counters |
|---|
A listing of DCGM counters.
| Field | Type | Description |
|---|---|---|
| @timestamp | date | Ingestion time of the gpu environment counters. |
Note
The data fields have been separated for compactness.
| Data Field | Type | Description |
|---|---|---|
| nvlink_recovery_error_count_l1 | long | Total number of NVLink recovery errors. |
| sync_boost_violation | long | Throttling duration due to sync-boost constraints (in us) |
| gpu_temp | long | GPU temperature (in C). |
| nvlink_bandwidth_l2 | long | Total number of NVLink bandwidth counters. |
| dec_utilization | long | Decoder utilization. |
| nvlink_recovery_error_count_l2 | long | Total number of NVLink recovery errors. |
| nvlink_bandwidth_l1 | long | Total number of NVLink bandwidth counters. |
| mem_copy_utilization | long | Memory utilization. |
| gpu_util_samples | double | GPU utilization sample count. |
| nvlink_replay_error_count_l1 | long | Total number of NVLink retries. |
| nvlink_data_crc_error_count_l1 | long | Total number of NVLink data CRC errors. |
| nvlink_replay_error_count_l0 | long | Total number of NVLink retries. |
| nvlink_bandwidth_l0 | long | Total number of NVLink bandwidth counters. |
| nvlink_data_crc_error_count_l3 | long | Total number of NVLink data CRC errors. |
| nvlink_flit_crc_error_count_l3 | long | Total number of NVLink flow-control CRC errors. |
| nvlink_bandwidth_l3 | long | Total number of NVLink bandwidth counters. |
| nvlink_replay_error_count_l2 | long | Total number of NVLink retries. |
| nvlink_replay_error_count_l3 | long | Total number of NVLink retries. |
| nvlink_data_crc_error_count_l0 | long | Total number of NVLink data CRC errors. |
| nvlink_recovery_error_count_l0 | long | Total number of NVLink recovery errors. |
| enc_utilization | long | Encoder utilization. |
| power_usage | double | Power draw (in W). |
| nvlink_recovery_error_count_l3 | long | Total number of NVLink recovery errors. |
| nvlink_data_crc_error_count_l2 | long | Total number of NVLink data CRC errors. |
| nvlink_flit_crc_error_count_l2 | long | Total number of NVLink flow-control CRC errors. |
| serial_number | text | The serial number of the GPU. |
| power_violation | long | Throttling duration due to power constraints (in us). |
| xid_errors | long | Value of the last XID error encountered. |
| gpu_utilization | long | GPU utilization. |
| nvlink_flit_crc_error_count_l0 | long | Total number of NVLink flow-control CRC errors. |
| nvlink_flit_crc_error_count_l1 | long | Total number of NVLink flow-control CRC errors. |
| mem_util_samples | double | The sample rate of the memory utilization. |
| thermal_violation | long | Throttling duration due to thermal constraints (in us). |
cast-counters¶
| Elasticsearch Templates: | |
|---|---|
| /opt/ibm/csm/bigdata/elasticsearch/templates/cast-ccounters*.json | |
A class of index representing counter aggregation from non CSM data flows. Generally indices following this naming pattern contain data from standalone data aggregation utilities.
cast-counters-gpfs¶
| alias: | cast-counters-gpfs |
|---|
A collection of counter data from gpfs. The script outlined in the data aggregators documentation leverages zimon to perform the collection. The following is the index generated by the default script bundled in the CAST rpm.
| Field | Type | Description |
|---|---|---|
| @timestamp | date | Ingestion time of the gpu environment counters. |
Note
The data fields have been separated for compactness.
| Data Field | Type | Description |
|---|---|---|
| cpu_system | long | The system space usage of the CPU. |
| cpu_user | long | The user space usage of the CPU. |
| mem_active | long | Active memory usage. |
| gpfs_ns_bytes_read | long | Networked bytes read. |
| gpfs_ns_bytes_written | long | Networked bytes written. |
| gpfs_ns_tot_queue_wait_rd | long | Total time spent waiting in the network queue for read operations. |
| gpfs_ns_tot_queue_wait_wr | long | Total time spent waiting in the network queue for write operations. |
cast-counters-ufm¶
| alias: | cast-counters-ufm |
|---|
Due to the wide variety of counters that may be gathered checking the data aggregation script is strongly recommended.
The mapping for the cast-counters-ufm index is provided below:
| Field | Type | Description |
|---|---|---|
| @timestamp | date | Ingestion time of the ufm environment counters. |
| timestamp | date | When environment counters were gathered. |
| type | text | The type of the event (cast-counters-ufm). |
| source | text | The source of the counters. |
cast-db¶
CSM history tables are archived in Elasticsearch as separate indices. CAST provides a document on configuring CSM database data archival <DataArchiving>.
The mapping shared between the indices is as follows:
| Field | Type | Description |
|---|---|---|
| @timestamp | date | When archival event occured. |
| tags | text | Tags about the archived data. |
| type | text | The originating table, drives index assignment. |
| data | doc | The mapping of table columns, contents differ for each table. |
Attention
These indicies will match CSM database history tables, contents not replicated for brevity.
cast-ibm-crasssd-bmc-alerts¶
While not managed by CAST crassd will ship bmc alerts to the big data store.
Kibana¶
Kibana is an open-sourced data visualization tool used in the ELK stack.
CAST provides a utility plugin for multistep searches of CSM jobs in Kibana dashboards.
Configuration¶
Note
This guide has been tested using Kibana 6.8.1, the latest RPM may be downloaded from the Elastic Site.
The following is a brief introduction to the installation and configuration of the Kibana service.
At the current time CAST does not provide a configuration file in its RPM.
- Install the Kibana rpm:
yum install -y kibana-*.rpm
- Configure the Kibana YAML file (/etc/kibana/kibana.yml)
CAST recommends the following four values be set before starting Kibana:
| Setting | Description | Sample Value |
|---|---|---|
| server.host | The address the kibana server will bind on, needed for external access. | “10.7.4.30” |
| elasticsearch.url | The URL of an elasticsearch service, this should include the port number (9200 by default). | “http://10.7.4.13:9200” |
| xpack.security.enabled | The xpack security setting, set to false if not being used. | false |
| xpack.ml.enabled | Sets the status of xpack Machine Learning. Please note this must be set to false on ppc64le installations. | false |
- Install the CAST Search rpm:
rpm -ivh ibm-csm-bds-kibana-*.noarch.rpm
- Start Kibana:
systemctl enable kibana.service
systemctl start kibana.service
Kibana should now be running and fully featured. Searchs may now be performed on the Discover tab.
CAST Search¶
CAST Search is a React plugin designed for interfacing with elastic search an building filters for Kibana Dashboards. To maxmize the value of the plugin the cast-allocation index pattern should be specified.
Logstash¶
Logstash is an open-source data processing pipeline used in the ELK stack. The core function of this service is to process unstructured data, typically syslogs, and then pass the newly structured text to the elasticsearch service.
Typically, in the CAST design, the Logstash service is run on the service nodes in the xCAT infrastructure. This design is to reduce the number of servers communicating with each instance of Logstash, distributing the workload. xCAT service nodes have failover capabilities removing the need for HAProxies to reduce the risk of data loss. Finally, in using the service node the total cost of the Big Data Cluster is reduced as the need for a dedicated node for data processing is removed.
CAST provides an event correlator for Logstash to assist in the generation of RAS events for specific messages.
Installation and Configuration¶
Installation¶
Note
This guide has been tested using Logstash 6.8.1, the latest RPM may be downloaded from the Elastic Site.
For the official install guide of Logstash in the ELK stack go to: Installing Logstash
The following is a brief guide to the installation of Logstash with relation to CAST. The user should use the offical ELK documentation above as the main reference of information for installing Logstash.
CAST provides a set of sample configuration files in the repository at csm_big_data/logstash/.
If the ibm-csm-bds-*.noarch.rpm rpm has been installed the sample configurations may be found
in /opt/ibm/csm/bigdata/logstash/.
- Install the logstash rpm and java 1.8.1+ (command run from directory with logstash rpm):
yum install -y logstash-*.rpm java-1.8.*-openjdk
Copy the Logstash pipeline configuration files to the appropriate directories.
This step is ultimately optional, however it is recommended that these files be reviewed and modified by the system administrator at this phase:
Target file Repo Dir RPM Dir logstash.yml(see note) config/ config/ jvm.options config/ config/ conf.d/logstash.conf config/ config/ patterns/ibm_grok.conf patterns/ patterns/ patterns/mellanox_grok.conf patterns/ patterns/ patterns/events.yml patterns/ patterns/
Note
Target files are relative to /etc/logstash. Repo Directories are relative to csm_big_data/logstash. RPM Directories are relative to /opt/ibm/csm/bigdata/logstash/.
- Install the CSM Event Correlator
rpm -ivh ibm-csm-bds-logstash*.noarch.rpm
Note
This change is effective in the 1.3.0 release of the CAST rpms.
Please refer to CSM Event Correlator for more details.
Note
The bin directory is relative to your logstash install location.
Configuration¶
Note
The conf.d/logstash.conf file requires the ELASTIC-INSTANCE field be replaced with your cluster’s Elasticsearch nodes.
Note
logstash.yml is not shipped with this version of the RPM please use the following config for logstash.
# logstash.yml
---
path.data: /var/lib/logstash
path.config: /etc/logstash/conf.d/*conf
path.logs: /var/log/logstash
pipeline.workers: 2
pipeline.batch.size: 2000 # This is the MAXIMUM, to prevent exceedingly long waits a delay is supplied.
pipeline.batch.delay: 50 # Maximum time to wait to execute an underfilled queue in milliseconds.
queue.type: persisted
...
Tuning logstash is highly dependant on your use case and environment. What follows is a set of recommendations based on the research and experimentation of the CAST Big Data team.
Here are some useful resources for learning more about profiling and tuning logstash:
logstash.yml¶
This configuration file specifies details about the Logstash service:
- Path locations (as a rule of thumb these files should be owned by the logstash user).
- Pipeline details (e.g. workers, threads, etc.)
- Logging levels.
For more details please refer to the Logstash settings file documentation.
jvm.options¶
The configuration file for the Logstash JVM. The supplied settings are CAST’s recommendation, however, the efficacy of these settings entirely depends on your Logstash node.
logstash.conf¶
The logstash.conf is the core configuration file for determining the behavior of the Logstash pipeline in the default CAST configuration. This configuration file is split into three components: input, filter and output.
The input section defines how the pipeline may ingest data. In the CAST sample only the tcp input plugin is used. CAST currently uses different ports to assign tagging to facilitate simpler filter configuration. For a more in depth description of this section please refer to the configuration file structure in the official Logstash documentation.
The default ports and data tagging are as follows:
| Default Port Values | |
|---|---|
| Tag | Port Number |
| syslog | 10515 |
| json_data | 10522 |
| transactions | 10523 |
The filter section defines the data enrichment step of the pipeline. In the CAST sample the following operations are performed:
- Unstructured events are parsed with the grok utility.
- Timestamps are reformatted (as needed).
- Events with JSON formatting are parsed.
- CSM Event Correlator is invoked on properly ingested logs.
Generally speaking care must be taken in this section to leverage branch prediction. Additionally, it is easy to malform the grok plugin to result in slow downs in the pipeline performance. Please consult configuration file structure in the official Logstash documentation for more details.
The output section defines the target for the data processed through the pipeline. In the CAST sample the elasticsearch plugin is used, for more details please refer to the linked documentation.
The user must replace _ELASTIC_IP_PORT_LIST_ with a comma delimited list of hostname:port string pairs refering to the nodes in the elasticsearch cluster. Generally if using the default configuration the port should be 9200. An example of this configuration is as follows:
hosts => [ "10.7.4.14:9200", "10.7.4.15:9200", "10.7.4.19:9200" ]
grok¶
Logstash provides a grok utility to perform regular expression pattern recognition and extraction. When writing grok patterns several rules of thumb are recommended by the CAST team:
- Profile your patterns, Do you grok Grok? discusses a mechanism for profiling.
- Grok failure can be expensive, use anchors (^ and $) to make string matches precise to reduce failure costs.
- _groktimeout tagging can set an upper bound time limit for grok operations.
- Avoid DATA and GREEDYDATA if possible.
Starting Logstash¶
Now that every thing has been installed and configured. You can start Logstash.
systemctl enable logstash
systemctl start logstash
Logstash should now be operational. At this point data aggregators should be configured to point to your Logstash node as appropriate.
Note
In ELK 6.8.1, Logstash may not start and run on Power, due to an arch issue. Please see: Logstash Not Starting
CSM Event Correlator¶
CSM Event Correlator (CEC) is the CAST solution for event correlation in the logstash pipeline. CEC is written in ruby to leverage the existing Logstash plugin system. At its core CEC is a pattern matching engine using grok to handle pattern matching.
A sample configuration of CEC is provided as the events.yml file described in the Configuration section of the document.
There’s an extensive asciidoc for usage of the CSM Event Correlator plugin. The following documentation is an abridged version.
Common Big Data Store Problems¶
The following document outlines some common sources of error for the Big Data Store and how to best resolve the described issues.
Beats Not Starting¶
There was a typo in a previous version of CAST. The field “close_removed” is a bool in the ELK config. This typo caused beats to not start up correctly. The CAST team has updated the config file to address this issue.
Logstash Not Starting¶
In ELK 6.8.1, Logstash may not start and run on Power, due to an arch issue.
[2019-05-03T10:41:38,701][ERROR][org.logstash.Logstash ]
java.lang.IllegalStateException: Logstash stopped processing because of an error:
(LoadError) load error: ffi/ffi -- java.lang.NullPointerException: null
The CAST team was able to trace the bug to jruby/lib/ruby/stdlib/ffi/platform/powerpc64-linux/. It looks as though the platform.conf file was not created for this platform. Copying the types.conf file to platform.conf appears to resolve the problem.
GitHub Issue: https://github.com/elastic/logstash/issues/10755
IBM and the CAST team have made a script to fix this packaging issue.
The patch can be found in the CAST repo at: https://github.com/IBM/CAST/blob/master/csm_big_data/logstash/patches/csm_logstash_6-8-1_patch.sh and in the install dir at: /opt/ibm/csm/bigdata/logstash/patches/csm_logstash_6-8-1_patch.sh.
Run this patch before starting Logstash.
Timestamps¶
Timestamps are generally the number one source of problems in the ELK Stack. This is due to a wide variety of precisions and timestamp formats that may come from different data sources.
Elasticsearch will try its best to parse dates, as outlined in the ELK Date documentation. If a date doesn’t match the default formats (a usual culprit is epoch time or microseconds) the administrator will need to take action.
CAST has two prescribed resolution patterns for this problem:
The administrator may apply one or more resolution patterns to resolve the issue.
Attention
Timestamps created by CSM will generally attempt to ship timestamps in the correct format, however, Elasticsearch will only automatically parse up to millisecond. The default ISO 8601 format of Postgresql has precision up to microseconds, requiring postgres generated timestamps to use a parsing strategy.
Note
If any indices have been populated with data not interpreted as dates, those indices will need to be reindexed.
Fixing Timestamps in Elasticsearch¶
This is the preferred methodology for resolving issues in the timestamp. CAST supplies
a utility in ibm-csm-bds-*.noarch.rpm for generating mappings that fix the timestamps in
data sources outlined in Data Aggregation.
The index mapping script is present at /opt/ibm/csm/bigdata/elasticsearch/createIndices.sh. When executed the script will make a request to the Elasticsearch server (determined by the input to the script) which creates all of the mappings defined in the /opt/ibm/csm/bigdata/elasticsearch/templates directory. If the user wishes to clear existing templates/mappings the /opt/ibm/csm/bigdata/elasticsearch/removeIndices.sh is provided to delete indices made through the creation script.
If adding a new index, the following steps should be taken to repair timestamps or any other invalid data types on a per index or index pattern basis:
Create a json file to store the mapping. CAST recommends naming the file <template-name>.json
Populate the file with configuration settings.
{ "index_patterns": ["<NEW INDEX PATTERN>"], "order" : 0, "settings" : { "number_of_shards" : <SHARDING COUNT>, "number_of_replicas" : <REPLICA COUNT> }, "mappings" : { "_doc": { "properties" : { "<SOME TIMESTAMP>" : { "type" : "date" }, }, "dynamic_date_formats" : [ "strict_date_optional_time|yyyy/MM/dd HH:mm:ss Z|| yyyy/MM/dd Z||yyyy-MM-dd HH:mm:ss.SSSSSS"] } } }
Attention
The dynamic_date_formats section is most relevant to the context of this entry.
Note
To resolve timestamps with microseconds (e.g. postgres timestamps) yyyy-MM-dd HH:mm:ss.SSSSSS serves as a sample.
Ship the json file to elasticsearch. There are two mechanisms to achieve this:
- Place the file in the /opt/ibm/csm/bigdata/elasticsearch/templates/ directory and run
the /opt/ibm/csm/bigdata/elasticsearch/createIndices.sh script.
Curl the file to Elasticsearch.
curl -s -o /dev/null -X PUT "${HOST}:9200/_template/${template_name}?pretty"\ -H 'Content-Type: application/json' -d ${json-template-file}
Attention
If the template is changed the old template must be removed first!
To remove a template the admin may either run the /opt/ibm/csm/bigdata/elasticsearch/removeIndices.sh script, which removes templates by the file names in /opt/ibm/csm/bigdata/elasticsearch/templates/.
The other option is to remove a template specifically with a curl command:
curl -X DELETE "${HOST}:9200/_template/${template_name}?pretty"
The above documentation is a brief primer on how to modify templates, a powerful elasticsearch utility. If the user needs more information please consult the official elastic template documentation.
Fixing Timestamps in Logstash¶
If the elasticsearch methodology doesn’t apply to the use case, logstash timestamp manipulation might be the correct solution.
Note
The following section performs modifications to the logstash.conf file that should be placed in /etc/logstash/conf.d/logstash.conf if following the Logstash configuration documentation.
The CAST solution uses the date filter plugin to achieve these results. In the shipped configuration the following sample is provided:
if "ras" in [tags] and "csm" in [tags] {
date {
match => ["time_stamp", "ISO8601","YYYY-MM-dd HH:mm:ss.SSS" ]
target => "time_stamp"
}
}
The above sample parses the time_stamp field for the ISO 8601 standard and converts it to something that is definitely parseable by elasticsearch. For additional notes about this utility please refer to the official date filter plugin documentation.
Data Aggregation¶
Data Aggregation in CAST utilizes the logstash pipeline to process events and pass it along to Elasticsearch.
Note
In the following documentation, examples requiring replacement will be annotated with the bash style ${variable_name} and followed by an explanation of the variable.
Logs¶
The default configuration of the CAST Big Data Store has support for a number of logging types, most of which are processed through the syslog utility and then enriched by Logstash and the CAST Event Correlator.
Syslog¶
| Logstash Port: | 10515 |
|---|
Syslog is generally aggregated through the use of the rsyslog daemon.
Most devices are capable of producing syslogs, and it is suggested that syslogs should be sent to Logstash via a redirection hierarchy outlined in the diagram below:
![digraph G {
Logstash [shape=square];
"Service Node" -> Logstash
"IB/Ethernet" -> Logstash
PDUs -> Logstash
"Compute Node" -> "Service Node"
"Utility Node" -> "Service Node"
"UFM Server" -> "Service Node"
}](_images/graphviz-b6eac302d7f4afb595ab862443862bd1d14dbc7c.png)
Syslog Redirection¶
Warning
This step should not be performed on compute nodes in xCAT clusters!
To redirect a syslog so it is accepted by Logstash the following must be added to the /etc/rsyslog.conf file:
$template logFormat, "%TIMESTAMP:::date-rfc3339% %HOSTNAME% %APP-NAME% \
%PROCID% %syslogseverity-text% %msg%\n"
*.*;cron.none @@${logstash_node}:${syslog_port};logFormat
The rsyslog utility must then be restarted for the changes to take effect:
/bin/systemctl restart rsyslog.service
Field Description
| logstash_node: | Replace with the hostname or IP address of the Logstash Server, on service nodes this is typically localhost. |
|---|---|
| syslog_port: | Replace with the port set in the Logstash Configuration File [ default: 10515 ]. |
Format
The format of the syslog is parsed in the CAST model by Logstash. CAST provides a grok for this syslog format in the pattern list provided by the CAST repository and rpm. The grok pattern is reproduced below with the types matching directly to the types in the syslog elastic documentation.
RSYSLOGDSV ^(?m)%{TIMESTAMP_ISO8601:timestamp} %{HOSTNAME:hostname} \
%{DATA:program_name} %{INT:process_id} %{DATA:severity} %{GREEDYDATA:message}$
Note
This pattern has a 1:1 relationship with the template given above and a 1:many relationship with the index data mapping. Logstash appends some additional fields for metadata analysis.
GPFS¶
To redirect the GPFS logging data to the syslog please do the following on the Management node for GPFS:
/usr/lpp/mmfs/bin/mmchconfig systemLogLevel=notice
After completing this process the gpfs log should now be forwarded to the syslog for the configured node.
Note
Refer to Syslog Redirection for gpfs log forwarding, the default syslog port is recommended (10515).
Note
The systemLogLevel attribute will forward logs of the specified level and higher to the
syslog. It supports the following options: alert, critical, error, warning,
notice, configuration, informational, detail, and debug.
Note
This data type will inhabit the same index as the syslog documents due to data similarity.
UFM¶
Note
This document assumes that the UFM daemon is up and running on the UFM Server.
The Unified Fabric Manager (UFM) has several distinct data logs to aggregate for the big data store.
System Event Log¶
| Logstash Port: | 10515 |
|---|
The System Event Log will report various fabric events that occur in the UFM’s network:
- A link coming up.
- A link going down.
- UFM module problems.
A sample output showing a downed link can be seen below:
Oct 17 15:56:33 c931hsm04 eventlog[30300]: WARNING - 2016-10-17 15:56:33.245 [5744] [112]
WARNING [Hardware] IBPort [default(34) / Switch: c931ibsw-leaf01 / NA / 16]
[dev_id: 248a0703006d40f0]: Link-Downed counter delta threshold exceeded.
Threshold is 0, calculated delta is 1. Peer info: Computer: c931f03p08 HCA-1 / 1.
Note
The above example is in the Syslog format.
To send this log to the Logstash data aggregation the /opt/ufm/files/conf/gv.cfg file must be modified and /etc/rsyslog.conf should be modified as described in Syslog Redirection.
CAST recommends setting the following attributes in /opt/ufm/files/conf/gv.cfg:
[Logging]
level = INFO
syslog = true
event_syslog = true
[CSV]
write_interval = 30
ext_ports_only = yes
max_files = 10
[MonitoringHistory]
history_configured = true
Note
write_interval and max_files were set as a default, change these fields as needed.
After configuring /opt/ufm/files/conf/gv.cfg restart the ufm daemon.
/etc/init.d/ufmd restart
Format
CAST recommends using the same syslog format as shown in Syslog Redirection, however, the message
in the case of the mellanox event log has a consistent structure which may be parsed by Logstash.
The pattern and substitutions are used below. Please note that the timestamp, severity and
message fields are all overwritten from the default syslog pattern.
Please consult the event log table in the elasticsearch documentation <melElastic> for details on the message fields.
MELLANOXMSG %{MELLANOXTIME:timestamp} \[%{NUMBER:log_counter}\] \[%{NUMBER:event_id}\] \
%{WORD:severity} \[%{WORD:event_type}\] %{WORD:category} %{GREEDYDATA:message}
Console¶
Note
This document is designed to configure the xCAT service nodes to ship goconserver output to logstash (written using xCAT 2.13.11).
| Logstash Port: | 10522 |
|---|---|
| Relevant Directories: | |
/etc/goconserver
|
|
CSM recommends using the goconserver bundled in the xCAT dependencies and documented in xCat-GoConserver. A limited configuration guide is provided below, but for gaps or more details please refer to the the xCAT read the docs.
- Install the goconserver and start it:
yum install goconserver
systemctl stop conserver.service
makegocons
- Configure the /etc/goconserver to send messages to the Logstash server associated with the
- service node (generally localhost):
# For options above this line refer to the xCAT read-the-docs
logger:
tcp:
- name: Logstash
host: <Logstash-Server>
port: 10522 # This is the port in the sample configuration.
timeout: 3 # Default timeout time.
- Restart the goconserver:
service goconserver restart
Format
The goconserver will now start sending data to the Logstash server in the form of JSON messages:
{
"type" : "console"
"message" : "c650f04p23 login: jdunham"
"node" : "c650f04p23"
"date" : "2018-05-08T09:49:36.530886-04"
}
The CAST logstash filter then mutates this data to properly store it in the elasticsearch backing store:
| Field | New Field |
|---|---|
| node | hostname |
| date | @timestamp |
Cumulus Switch¶
Attention
The CAST documentation was written using Cumulus Linux 3.5.2, please ensure the switch is at this level or higher.
Cumulus switch logging is performed through the usage of the rsyslog service. CAST recommends placing Cumulus logging in the syslog-log indices at this time.
Configuration of the logging on the switch can be achieved through the net command:
net add syslog host ipv4 ${logstash_node} port tcp ${syslog_port}
net commit
This command will populate the /etc/rsyslog.d/11-remotesyslog.conf file with a rule to export the syslog to the supplied hostname and port. If using the default CAST syslog configuration this file will need to be modified to have the CAST syslog template:
vi /etc/rsyslog.d/11-remotesyslog.conf
$template logFormat, "%TIMESTAMP:::date-rfc3339% %HOSTNAME% %APP-NAME% %PROCID% \
%syslogseverity-text% %msg%\n"
*.*;cron.none @@${logstash_node}:${syslog_port};logFormat
sudo service rsyslog restart
Note
For more configuration details please refer to the official Cumulus Linux User Guide.
Counters¶
The default configuration of the CAST Big Data Store has support for a number of counter types, most of which are processed through Logstash and the CAST Event Correlator.
GPFS¶
In order to collect counters from the GPFS file system CAST leverages the zimon utility. A python
script interacting with this utility is provided in the ibm-csm-bds-*.noarch.rpm.
The following document assumes that the cluster’s service nodes be running the pmcollector service and any nodes requiring metrics be running pmsensors.
Collector¶
| rpms: |
|
|---|---|
| config: | /opt/IBM/zimon/ZIMonCollector.cfg |
In the CAST architecture a pmcollector should be run on each of the service node in federated mode. To configure federated mode on the collector add all of the nodes configured as collectors to the /opt/IBM/zimon/ZIMonCollector.cfg this configuration should be then propagated to all of the collector nodes in the cluster.
peers = {
host = "collector1"
port = "9085"
},
{
host = "collector2"
port = "9085"
},
{
host = "collector3"
port = "9085"
}
After configuring the collector start and enable the pmcollectors.
systemctl start pmcollector
systemctl enable pmcollector
Sensors¶
| RPMs: | gpfs.gss.pmsensors.ppc64le (Version 5.0 or greater) |
|---|---|
| Config: | /opt/IBM/zimon/ZIMonSensors.cfg |
It is recommended to use the GPFS managed configuration file through use of the mmperfmon command. Before setting the node to do performance monitoring it’s recommended that at least the following command be run:
/usr/lpp/mmfs/bin/mmperfmon config generate --collectors ${collectors}
/usr/lpp/mmfs/bin/mmperfmon config update GPFSNode.period=0
It’s recommended to specify at least two collectors defined in the zimon.collector section of this document. The pmsensor service will attempt to distribute the load and account for failover in the event of a downed collector.
After generating the sensor configuration the nodes must then be set to perfmon:
$ /usr/lpp/mmfs/bin/mmchnode --perfmon -N ${nodes}
Assuming /opt/IBM/zimon/ZIMonSensors.cfg has been properly distributed the sensors may then be started on the nodes.
$ systemctl start pmsensors
$ systemctl enable pmsensors
Attention
To detect failures of the power hardware the following must be prepared on the management node of the GPFS cluster.
$ vi /var/mmfs/mmsysmon/mmsysmonitor.conf
[general]
powerhw_enabled=True
$ mmsysmoncontrol restart
Python Script¶
| CAST RPM: | ibm-csm-bds-*.noarch.rpm |
|---|---|
| Script Location: | |
| /opt/ibm/csm/bigdata/data-aggregators/zimonCollector.py | |
| Dependencies: | gpfs.base.ppc64le (Version 5.0 or greater) |
CAST provides a script for easily querying zimon, then sending the results to Big Data Store. The zimonCollector.py python script leverages the python interface to zimon bundled in the gpfs.base rpm. The help output for this script is duplicated below:
A tool for extracting zimon sensor data from a gpfs collector node and shipping it in a json
format to logstash. Intended to be run from a cron job.
Options:
Flag | Description < default >
==================================|============================================================
-h, --help | Displays this message.
--collector <host> | The hostname of the gpfs collector. <127.0.0.1>
--collector-port <port> | The collector port for gpfs collector. <9084>
--logstash <host> | The logstash instance to send the JSON to. <127.0.0.1>
--logstash-port <port> | The logstash port to send the JSON to. <10522>
--bucket-size <int> | The size of the bucket accumulation in seconds. <60>
--num-buckets <int> | The number of buckets to retrieve in the query. <10>
--metrics <Metric1[,Metric2,...]> | A comma separated list of zimon sensors to get metrics from.
| <cpu_system,cpu_user,mem_active,gpfs_ns_bytes_read,
| gpfs_ns_bytes_written,gpfs_ns_tot_queue_wait_rd,
| gpfs_ns_tot_queue_wait_wr>
CAST expects this script to be run from a service node configured for both logstash and zimon collection. In this release this script need only be executed on one service node in the cluster to gather sensor data.
The recommended cron configuration for this script is as follows:
*/10 * * * * /opt/ibm/csm/bigdata/data-aggregators/zimonCollector.py
The output of this script is a newline delimited list of JSON designed for easy ingestion by the logstash pipeline. A sample from the default script configuration is as follows:
{
"type": "zimon",
"source": "c650f99p06",
"data": {
"gpfs_ns_bytes_written": 0,
"mem_active": 1769963,
"cpu_system": 0.015,
"cpu_user": 0.004833,
"gpfs_ns_tot_queue_wait_rd": 0,
"gpfs_ns_bytes_read": 0,
"gpfs_ns_tot_queue_wait_wr": 0
},
"timestamp": 1529960640
}
In the default configuration of this script records will be shipped as JSONDataSources.
UFM¶
| CAST RPM: | ibm-csm-bds-*.noarch.rpm |
|---|---|
| Script Location: | |
| /opt/ibm/csm/bigdata/data-aggregators/ufmCollector.py | |
CAST provides a python script to gather UFM counter data. The script is intended to be run from either a service node running logstash or the UFM node as a cron job. A description of the script from the help functionality is reproduced below:
Purpose: Simple script that is packaged with BDS. Can be run individually and
independantly when ever called upon.
Usage:
- Run the program.
- pass in parameters.
- REQUIRED [--ufm] : This tells program where UFM is (an IP address)
- REQUIRED [--logstash] : This tells program where logstash is (an IP address)
- OPTIONAL [--logstash-port] : This specifies the port for logstash
- OPTIONAL [--ufm_restAPI_args-attributes] : attributes for ufm restAPI
- CSV
Example:
- Value1
- Value1,Value2
- OPTIONAL [--ufm_restAPI_args-functions] : functions for ufm restAPI
- CSV
- OPTIONAL [--ufm_restAPI_args-scope_object] : scope_object for ufm restAPI
- single string
- OPTIONAL [--ufm_restAPI_args-interval] : interval for ufm restAPI
- int
- OPTIONAL [--ufm_restAPI_args-monitor_object] : monitor_object for ufm restAPI
- single string
- OPTIONAL [--ufm_restAPI_args-objects] : objects for ufm restAPI
- CSV
FOR ALL ufm_restAPI related arguments:
- see ufm restAPI for documentation
- json format
- program provides default value if no user provides
The recommended cron configuration for this script is as follows:
*/10 * * * * /opt/ibm/csm/bigdata/data-aggregators/ufmCollector.py
The output of this script is a newline delimited list of JSON designed for easy ingestion by the logstash pipeline. A sample from the default script configuration is as follows:
{
"type": "counters-ufm",
"source": "port2",
"statistics": {
...
},
"timestamp": 1529960640
}
In the default configuration of this script records will be shipped as JSONDataSources.
JSON Data Sources¶
| Logstash Port: | 10522 |
|---|---|
| Required Field: | type |
| Recommended Fields: | |
| timestamp | |
Attention
This section is currently a work in progress.
CAST recommends JSON data sources be shipped to Logstash to leverage the batching and data enrichment tool. The default logstash configuration shipped with CAST will designate port 10522. JSON shipped to this port should have the type field specified. This type field will be used in defining the name of the index.
Data Aggregators shipping to this port will generate indices with the following name format: cast-%{type}-%{+YYYY.MM.dd}
crass bmc alerts¶
While not bundled with CAST the crass daemon is used to monitor BMC events and counters. The following document is written assuming you have access to an ibm-crassd-*.ppc64le rpm.
- Install the rpm:
yum install -y ibm-crassd-*.ppc64le.rpm
- Edit the configuration file located at /opt/ibm/ras/etc/ibm-crassd.config:
This file neds the [logstash] configuration section configured and logstash=True in the [notify] section.
- Start crassd:
systemctl start ibm-crassd
Attention
The above section is a limited rundown of crassd configuration, for greater detail consult the official documentation for crassd.
CAST Data Sources¶
csmd syslog¶
| Logstash Port: | 10515 |
|---|
CAST has enabled the boost syslog utility through use of the csmd configuration file.
"csm" : {
...
"log" : {
...
"sysLog" : true,
"server" : "127.0.0.1",
"port" : "514"
}
...
}
By default enabling syslog will write to the localhost syslog port using UDP. The target may be changed by the server and port options.
The syslog will follow the RFC 3164 syslog protocol. After being filtered through the Syslog Redirection template the log will look something like this:
2018-05-17T11:17:32-04:00 c650f03p37-mgt csmd 1032 debug csmapi; TIMING: 1525910812,17,2,1526570252507364568,1526570252508039085,674517
2018-05-17T11:17:32-04:00 c650f03p37-mgt csmd 1032 info csmapi; [1525910812]; csm_allocation_query_active_all end
2018-05-17T11:17:32-04:00 c650f03p37-mgt csmd 1032 info csmapi; CSM_CMD_allocation_query_active_all[1525910812]; Client Recv; PID: 14921; UID:0; GID:0
Please note csmd is stored in the APP-NAME field of rsyslog and 1031 is stored in the PROCID. csmapi represents the CSM subcomponent, this is included in the msg field of rsyslog.
These logs will then stored in the cast-log-syslog index using the default CAST configuration.
CSM Buckets¶
| Logstash Port: | 10522 |
|---|
CSM provides a mechanism for running buckets to aggregate environmental and counter data from a variety of sources in the cluster. This data will be aggregated and shipped by the CSM aggregator to a logstash server (typically the local logstash server).
Format
Each run of a bucket will be encapsulated in a JSON document with the following pattern:
{
"type": "type-of-record",
"source": "source-of-record",
"timestamp": "timestamp-of-record",
"data": {
...
}
}
| type: | The type of the bucket, used to determine the appropriate index. |
|---|---|
| source: | The source of the bucket run (typically a hostname, but can depend on the bucket). |
| timestamp: | The timestamp of the collection |
| data: | The actual data from the bucket run, varies on bucket specification. |
Note
Each JSON document is newline delimited.
CSM Configuration¶
Compute
Refer to :ref`CSMD_datacollection_Block` for proper compute configuration.
This configuration will run data collection at specified intervals in one or more buckets. This must be configured on each compute node (compute nodes may have different buckets).
Aggregator
Refer to :ref`CSMD_BDS_Block` for proper aggregator configuration.
This will ship the environmental data to the specified ip and port. Officially CAST suggests the use of logstash for this feature and suggests targeting the local logstash instance running on the service node.
Attention
For users not employing logstash in their solution the output of this feature is a newline delimited list of JSON documents formatted as seen above.
Logstash Configuration¶
CAST uses a generic port (10522) for processing data matching the JSONDataSources pattern. The default logstash configuration file specifies the following in the input section of the configuration file:
tcp {
port => 10522
codec => "json"
}
Default Buckets¶
CSM supplies several default buckets for environmental collection:
| Bucket Type | Source | Description |
|---|---|---|
| csm-env-gpu | Hostname | Environmental counters about the node’s GPUs. |
| csm-env-mem | Hostname | Environmental counters about the node’s Memory. |
Database Archiving¶
| Logstash Port: | 10523 |
|---|---|
| Script Location: | |
| /opt/ibm/csm/db/csm_db_history_archive.sh | |
| Script RPM: | csm-db-*.rpm |
CAST supplies a command line utility for archiving the contents of the CSM database history tables. When run the utility (csm_db_history_archive.sh) will append to a daily JSON dump file (<table>.archive.<YYYY>-<MM>-<DD>.json) the contents of all history tables and the RAS event action table. The content appended is the next n records without a archive time as provided to the command line utility.Any records archived in this manner are then marked with an archive time for their eventual removal from the database. The utility should be executed on the node running the CSM Postgres database.
Each row archived in this way will be converted to a JSON document with the following pattern:
{
"type": "db-<table-name>",
"data": { "<table-row-contents>" }
}
| type: | The table in the database, converted to index in default configuration. |
|---|---|
| data: | Encapsulates the row data. |
CAST recommends the use of a cron job to run this archival. The following sample runs every five minutes, gathers up to 100 unarchived records from the csmdb tables, then appends the JSON formatted records to the daily dump file in the /var/log/ibm/csm/archive directory.
$ crontab -e
*/5 * * * * /opt/ibm/csm/db/csm_db_history_archive.sh -d csmdb -n 100 -t /var/log/ibm/csm/archive
CAST recommends ingesting this data through the filebeats utility. A sample log configuration is given below:
filebeat.inputs:
- type: log
enabled: true
paths:
- "/var/log/ibm/csm/archive/*.json"
# CAST recommends tagging all filebeats input sources.
tags: ["archive"]
Note
For the sake of brevity further filebeats configuration documentation will be omitted. Please refer to the filebeats documentation for more details.
To configure logstash to ingest the archives the beats input plugin must be used, CAST recommends port 10523 for ingesting beats records as shown below:
input
{
beats {
port => 10523
codec=>"json"
}
}
filter
{
mutate {
remove_field => [ "beat", "host", "source", "offset", "prospector"]
}
}
output
{
elasticsearch {
hosts => [<elastic-server>:<port>]
index => "cast-%{type}-%{+YYYY.MM.dd}"
http_compression =>true
document_type => "_doc"
}
}
In this sample configuration the archived history will be stored in the cast-db-<table_name> indices.
CSM Filebeat Logs¶
| Logstash Port: | 10523 |
|---|
Note
CSM only ships these logs to a local file, a utility such as Filebeats or a local Logstash service would be needed to ship the log to a Big Data Store.
Transaction Log¶
CAST offers a transaction log for select CSM API events. Today the following events are tracked:
- Allocation create/delete/update
- Allocation step begin/end
This transaction log represents a set of events that may be assembled to create the current state of an event in a Big Data Store.
In the CSM design these transactions are intended to be stored in a single elasticsearch index each transaction should be identified by a uid in the index.
Each transaction record will follow the following pattern:
Format
{
"type": "<transaction-type>",
"@timestamp" : "<timestamp>",
"data": { <table-row-contents>},
"traceid":<traceid-api>,
"uid": <unique-id>
}
| type: | The type of the transaction, converted to index in default configuration. |
|---|---|
| data: | Encapsulates the transactional data. |
| traceid: | The API’s trace id as used in the CSM API trace functionality. |
| uid: | A unique identifier for the record in the elasticsearch index. |
| @timestamp: | The timestamp in ISO 8601. |
Allocation Metrics¶
The CSM Daemon has the ability to report special Allocation metrics on Allocation Delete operations. This data includes per gpu usage and per cpu usage metrics.
Format
{
"type": "<metric-type>",
"data": { <metric data> },
"@timestamp" : "<timestamp>"
}
| type: | The type of the allocation metric, converted to index in default configuration. |
|---|---|
| data: | Encapsulates the allocation metric data. |
| @timestamp: | The timestamp in ISO 8601. |
GPU Data Sample
{
"type":"allocation-gpu",
"source":"c650f99p18",
"@timestamp" : "4/17/2018T09:42:42Z",
"data":
{
"allocation_id":1,
"gpu_id":0,
"gpu_usage":33520365,
"max_gpu_memory":29993467904
}
}
| allocation_id: | The allocation where collection occured. |
|---|---|
| gpu_id: | The gpu id on the system. |
| gpu_usage: | The usage of the GPU(microseconds) over the allocation. |
| max_gpu_memory: | Maximum GPU memory usage over the allocation. |
CPU Data Sample
{
"type":"allocation-cpu",
"source":"c650f99p18",
"@timestamp" : "4/17/2018T09:42:42Z",
"data":
{
"allocation_id":1,
"cpu_0":777777000000,
"cpu_1":777777000001
// ...
}
}
| allocation_id: | The allocation where collection occured. |
|---|---|
| cpu_x: | The individual CPU usage (nanoseconds) over the allocation. |
CSM Configuration¶
To enable the transaction and allocation metricslogging mechanism the following configuration settings must be specified in the CSM master configuration file:
"log" :
{
"transaction" : true,
"transaction_file" : "/var/log/ibm/csm/csm_transaction.log",
"transaction_rotation_size" : 1000000000,
"allocation_metrics" : true,
"allocation_metrics_file" : "/var/log/ibm/csm/csm_allocation_metrics.log",
"allocation_metrics_rotation_size" : 1000000000
}
| transaction: | Enables the mechanism transaction log mechanism. |
|---|---|
| transaction_file: | |
| Specifies the location the transaction log will be saved to. | |
| transaction_rotation_size: | |
| The size of the file (in bytes) to rotate the log at. | |
| allocation: | Enables the mechanism allocation metrics log mechanism. |
| allocation_file: | |
| Specifies the location the allocation metrics log will be saved to. | |
| allocation_rotation_size: | |
| The size of the file (in bytes) to rotate the log at. | |
Note
Please review The log block for additional context.
Filebeats Configuration¶
CAST recommends ingesting this data through the filebeats utility. A sample log configuration is given below:
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/ibm/csm/csm_transaction.log
tags: ["transaction"]
- type: log
enabled: true
paths:
- /var/log/ibm/csm/csm_allocation_metrics.log
tags: ["allocation","metrics"]
Note
For the sake of brevity further filebeats configuration documentation will be omitted. Please refer to the filebeats documentation for more details.
Warning
Filebeats has some difficulty with rollover events.
Logstash Configuration¶
To configure logstash to ingest the archives the beats input plugin must be used, CAST recommends port 10523 for ingesting beats records. Please note that this configuration only creates one index for each transaction log type, this is to prevent transactions that span days from duplicating logs.
input
{
beats {
port => 10523
codec=>"json"
}
}
filter
{
mutate {
remove_field => [ "beat", "host", "source", "offset", "prospector"]
}
}
output
{
elasticsearch {
hosts => [<elastic-server>:<port>]
action => "update"
index => "cast-%{type}"
http_compression =>true
doc_as_upsert => true
document_id => "%{uid}"
document_type => "_doc"
}
}
The resulting indices for this configuration will be one per transaction type with each document corresponding to the current state of a set of transactions.
Supported Transactions¶
The following transactions currently tracked by CSM are as follows:
| type | uid | data |
|---|---|---|
| allocation | <allocation_id> | Superset of csmi_allocation_t. Adds running-start-timestamp and running-end-timestamp. Failed allocation creates have special state: reverted. |
| allocation-step | <allocation_id>-<step_id> | Direct copy of csmi_allocation_step_t. |
Beats¶
| Official Documentation: | |
|---|---|
| Beats Reference | |
Beats are a collection of open source data shippers. CAST employs a subset of these beats to facilitate data aggregation.
Filebeats¶
| Official Documentation: | |
|---|---|
| Filebeats Reference | |
Filebeats is used to ship the CSM transactional log to the big data store. It was selected for its high reliabilty in data transmission and existing integration in the elastic stack.
Installation¶
The following installation guide will deal with configuring filebeats for the CSM transaction log for a more generalized installation guide please consult the official Filebeats Reference.
- Install the filebeats rpm on the node:
rpm -ivh filebeat-*.rpm
- Configure the /etc/filebeat/filebeat.yml file:
CAST ships a sample configuration file in the ibm-csm-bds-*.noarch rpm at /opt/ibm/csm/bigdata/beats/config/filebeat.yml. This file is preconfigured to point at the CSM database archive files and the csm transaction logs. Users will need to replace two keywords before using this configuration:
| _KIBANA_HOST_PORT_: | |
|---|---|
A string containing the “hostname:port” pairing of the Kibana server. |
|
| _LOGSTASH_IP_PORT_LIST_: | |
A list of “hostname:port” pairs pointing to Logstash servers to ingest the data (current CAST recommendation is a single instance of Logstash). |
|
- Start the filebeats service.
systemctl start filebeat.service
Filebeats should now be sending injested data to the Logstash instances specified in the configuation file.
Python Guide¶
Elasticsearch API¶
CAST leverages the Elasticsearch API python library to interact with Elasticsearch. If the API is being run on a node with internet access the following process may be used to install this library.
A requirements file is provided in the RPM:
pip install -r /opt/ibm/csm/bigdata/python/requirements.txt
If the node doesn’t have access to the internet please refer to the official python documentation for the installation of wheels: Installing Packages.
Big Data Use Cases¶
CAST offers a collection of use case scripts designed to interact with the Big Data Store through the elasticsearch interface.
findJobTimeRange.py¶
This use case may be considered a building block for the remaining ones. This use case demonstrates the use of the cast-allocation transactional index to get the time range of a job.
The usage of this use case is described by the –help option.
findJobKeys.py¶
This use case represents two comingled use cases. First when supplied a job identifier (allocation id or job id) and a keyword (regular expression case insensitive) the script will generate a listing of keywords and their occurrence rates on records associated with the supplied job. Association is filtered on by the time range of the jobs and hostnames that participated on the job.
A secondary usecase is presented in the verbose flag, allowing the user to see a list of all entries matching the keyword.
usage: findJobKeys.py [-h] [-a int] [-j int] [-s int] [-t hostname:port]
[-k [key [key ...]]] [-v] [--size size]
[-H [host [host ...]]]
A tool for finding keywords in the "message" field during the run time of a job.
optional arguments:
-h, --help show this help message and exit
-a int, --allocationid int
The allocation ID of the job.
-j int, --jobid int The job ID of the job.
-s int, --jobidsecondary int
The secondary job ID of the job (default : 0).
-t hostname:port, --target hostname:port
An Elasticsearch server to be queried. This defaults
to the contents of environment variable
"CAST_ELASTIC".
-k [key [key ...]], --keywords [key [key ...]]
A list of keywords to search for in the Big Data
Store. Case insensitive regular expressions (default :
.*). If your keyword is a phrase (e.g. "xid 13")
regular expressions are not supported at this time.
-v, --verbose Displays any logs that matched the keyword search.
--size size The number of results to be returned. (default=30)
-H [host [host ...]], --hostnames [host [host ...]]
A list of hostnames to filter the results to (filters on the "hostname" field, job independent).
findJobsRunning.py¶
A use case for finding all jobs running at the supplied timestamp. This usecase will display a list of jobs for which the start time is less than the supplied time and have either no end time or an end time greater than the supplied time.
usage: findJobsRunning.py [-h] [-t hostname:port] [-T YYYY-MM-DDTHH:MM:SS]
[-s size] [-H [host [host ...]]]
A tool for finding jobs running at the specified time.
optional arguments:
-h, --help show this help message and exit
-t hostname:port, --target hostname:port
An Elasticsearch server to be queried. This defaults
to the contents of environment variable
"CAST_ELASTIC".
-T YYYY-MM-DDTHH:MM:SS, --time YYYY-MM-DDTHH:MM:SS
A timestamp representing a point in time to search for
all running CSM Jobs. HH, MM, SS are optional, if not
set they will be initialized to 0. (default=now)
-s size, --size size The number of results to be returned. (default=1000)
-H [host [host ...]], --hostnames [host [host ...]]
A list of hostnames to filter the results to.
findJobMetrics.py¶
Leverages the built in Elasticsearch statistics functionality. Takes a list of fields and a job identifier then computes the min, max, average, and standard deviation of those fields. The calculations are computed against all records for the field during the running time of the job on the nodes that participated.
This use case also has the ability to generate correlations between the fields specified.
usage: findJobMetrics.py [-h] [-a int] [-j int] [-s int] [-t hostname:port]
[-H [host [host ...]]] [-f [field [field ...]]]
[-i index] [--correlation]
A tool for finding metrics about the nodes participating in the supplied job
id.
optional arguments:
-h, --help show this help message and exit
-a int, --allocationid int
The allocation ID of the job.
-j int, --jobid int The job ID of the job.
-s int, --jobidsecondary int
The secondary job ID of the job (default : 0).
-t hostname:port, --target hostname:port
An Elasticsearch server to be queried. This defaults
to the contents of environment variable
"CAST_ELASTIC".
-H [host [host ...]], --hostnames [host [host ...]]
A list of hostnames to filter the results to.
-f [field [field ...]], --fields [field [field ...]]
A list of fields to retrieve metrics for (REQUIRED).
-i index, --index index
The index to query for metrics records.
--correlation Displays the correlation between the supplied fields
over the job run.
findUserJobs.py¶
Retrieves a list of all jobs that the the supplied user owned. This list can be filtered to a time range or on the state of the allocation. If the –commonnodes argument is supplied a list nodes will be displayed where the node participated in more nodes than the supplied threshold. The colliding nodes will be sorted by number of jobs they participated in.
usage: findUserJobs.py [-h] [-u username] [-U userid] [--size size]
[--state state] [--starttime YYYY-MM-DDTHH:MM:SS]
[--endtime YYYY-MM-DDTHH:MM:SS]
[--commonnodes threshold] [-v] [-t hostname:port]
A tool for finding a list of the supplied user's jobs.
optional arguments:
-h, --help show this help message and exit
-u username, --user username
The user name to perform the query on, either this or
-U must be set.
-U userid, --userid userid
The user id to perform the query on, either this or -u
must be set.
--size size The number of results to be returned. (default=1000)
--state state Searches for jobs matching the supplied state.
--starttime YYYY-MM-DDTHH:MM:SS
A timestamp representing the beginning of the absolute
range to look for failed jobs, if not set no lower
bound will be imposed on the search.
--endtime YYYY-MM-DDTHH:MM:SS
A timestamp representing the ending of the absolute
range to look for failed jobs, if not set no upper
bound will be imposed on the search.
--commonnodes threshold
Displays a list of nodes that the user jobs had in
common if set. Only nodes with collisions exceeding
the threshold are shown. (Default: -1)
-v, --verbose Displays all retrieved fields from the `cast-
allocation` index.
-t hostname:port, --target hostname:port
An Elasticsearch server to be queried. This defaults
to the contents of environment variable
"CAST_ELASTIC".
findWeightedErrors.py¶
An extension of the findJobKeys.py use case. This use case will query elasticsearch for a job then run a predefined collection of mappings to assist in debugging a problem with the job.
usage: findWeightedErrors.py [-h] [-a int] [-j int] [-s int]
[-t hostname:port] [-k [key [key ...]]] [-v]
[--size size] [-H [host [host ...]]]
[--errormap file]
A tool which takes a weighted listing of keyword searches and presents
aggregations of this data to the user.
optional arguments:
-h, --help show this help message and exit
-a int, --allocationid int
The allocation ID of the job.
-j int, --jobid int The job ID of the job.
-s int, --jobidsecondary int
The secondary job ID of the job (default : 0).
-t hostname:port, --target hostname:port
An Elasticsearch server to be queried. This defaults
to the contents of environment variable
"CAST_ELASTIC".
-v, --verbose Displays the top --size logs matching the --errormap mappings.
--size size The number of results to be returned. (default=10)
-H [host [host ...]], --hostnames [host [host ...]]
A list of hostnames to filter the results to.
--errormap file A map of errors to scan the user jobs for, including
weights.
JSON Mapping Format¶
This use case utilizes a JSON mapping to define a collection of keywords and values to query the elasticsearch cluster for. These values can leverage the native elasticsearch boost feature to apply weights to the mappings allowing a user to quickly determine high priority items using scoring.
The format is defined as follows:
[
{
"category" : "A category, used for tagging the search in output. (Required)",
"index" : "Matches an index on the elasticsearch cluster, uses elasticsearch syntax. (Required)",
"source" : "The hostname source in the index.",
"mapping" : [
{
"field" : "The field in the index to check against(Required)",
"value" : "A value to query for; can be a phrase, regex or number. (Required)",
"boost" : "The elasticsearch boost factor, may be thought of as a weight. (Required)",
"threshold" : "A range comparison operator: 'gte', 'gt', 'lte', 'lt'. (Optional)"
}
]
}
]
When applied to a real configuration a mapping file will look something like this:
[
{
"index" : "*syslog*",
"source" : "hostname",
"category": "Syslog Errors" ,
"mapping" : [
{
"field" : "message",
"value" : "error",
"boost" : 50
},
{
"field" : "message",
"value" : "kdump",
"boost" : 60
},
{
"field" : "message",
"value" : "kernel",
"boost" : 10
}
]
},
{
"index" : "cast-zimon*",
"source" : "source",
"category" : "Zimon Counters",
"mapping" : [
{
"field" : "data.mem_active",
"value" : 12000000,
"boost" : 100,
"threshold" : "gte"
},
{
"field" : "data.cpu_system",
"value" : 10,
"boost" : 200,
"threshold" : "gte"
}
]
}
]
Note
The above configuration was designed for demonstrative purposes, it is recommended that users create their own mappings based on this example.
UFM Collector¶
A tool interacting with the UFM collector is provided in ibm-csm-bds-*.noarch.rpm.
This script performs 3 key operations:
- Connects to the UFM monitoring snapshot RESTful interface.
- This connection specifies a collection attributes and functions to execute against the
- interface.
- Processes and enriches the output of the REST connection.
- Adds a type, timestamp and source field to the root of the JSON document.
- Opens a socket to a target logstash instance and writes the payload.
Beats¶
The following scripts are bundled in the /opt/ibm/csm/bigdata/beats/ directory. They
are generally used to regenerate logs for filebeat ingestion.
csmTransactionRebuild.py¶
| Script Location: | |
|---|---|
/opt/ibm/csm/bigdata/beats/csmTransactionRebuild.py |
|
| RPM: | ibm-csm-bds-*.noarch.rpm |
This script is used to regenerate the CSM transaction log from the postgresql databse. It is recommended when using this script for the first time to back up your original transactional logs.
The core objective of this script is to repair issues with the transactional index that were
exposed in the transitory steps of the CSM Big Data development. As such, this script should only
be run in clusters which were running pre 1.5.0 level code.
usage: csmTransactionRebuild.py [-h] [-d db] [-u user] [-o output]
A tool for regenerating the csm transactional logs from the database.
optional arguments:
-h, --help show this help message and exit
-d db, --database db Database to archive tables from. Default: csmdb
-u user, --user user The database user. Default: postgres
-o output, --output output
The output file, overwrites existing file. Default:
csm-transaction.log
Transition scripts¶
Note
The following scripts are NOT shipped in the RPMs.
Sometimes between major versions fields may be renamed in the Big Data Store (this is generally
only performed in the event of a major bug). When CSM performs such a change a transition-script
will be provided on the GitHub repository in the csm_big_data/transition-scripts directory.
metric-transaction_140-150.py¶
Performs the transition from the 1.4.0 metric and transaction logs to 1.5.0.
# ./metric-transaction_140-150.py -h
usage: metric-transaction_140-150.py [-h] -f file-glob [--overwrite]
A tool for converting 1.4.0 CSM BDS logs to 1.5.0 CSM BDS logs.
optional arguments:
-h, --help show this help message and exit
-f file-glob, --files file-glob
A file glob containing the bds logs to run the fix
operations on.
--overwrite If set the script will overwrite the old files.
Default writes new file *.fixed.
The following commands will migrate the old logs to the new format:
./metric-transaction_140-150.py -f '/var/log/ibm/csm/csm_transaction.log*' --overwrite
./metric-transaction_140-150.py -f '/var/log/ibm/csm/csm_allocation_metrics.log*' --overwrite
Note
If performing this transition, the old data may need to be purged from BDS (in the case of the metrics log especially).
CSM Event Correlator Filter Plugin¶
Attention
The following document is a work in progress! The CSM Event Correlator is currently under development and the interface is subject to change.
Parses arbitrary text and structures the results of the parse into actionable events.
The CSM Event Correlator is a utility by which a system administrator may specify a collection of patterns (grok style), grouping by context (e.g. syslog, event log, etc.), which trigger actions (ruby scripts).
Installation¶
The CSM Event Correlator comes bundled in the ibm-csm-bds-logstash-*.noarch.rpm rpm.
When installing the rpm, any old versions of the plugin will be removed and the bundled version
will be installed.
CSM Event Correlator Pipeline Configuration Options¶
This plugin supports the following configuration options:
| Setting | Input type | Required |
|---|---|---|
| events_dir | string | No |
| patterns_dir | array | No |
| named_captures_only | boolean | No |
Please refer to common-options for options supported in all Logstash filter plugins.
This plugin is intended to be used in the filter block of the logstash configuration file. A sample configuration is reproduced below:
filter {
csm_event_correlator {
events_dir => "/etc/logstash/patterns/events.yml"
patterns_dir => "/etc/logstash/patterns/*.conf"
}
}
events_dir¶
| Value type: | string |
|---|---|
| Default value: | /etc/logstash/conf.d/events.yml |
The configuration file for the event correlator, see CSM Event Correlator Event Configuration File for details on the contents of this file.
This file is loaded on pipeline creation.
Attention
This field will use an array in future iterations to specify multiple configuration files. This change should not impact existing configurations.
patterns_dir¶
| Value type: | array |
|---|---|
| Default value: | [] |
A directory, file or filepath with a glob. The listing of files will be parsed for grok patterns which may be used in writing patterns for event correlation. If no glob is specified in the path * is used.
Configuration with a file glob:
patterns_dir => "/etc/logstash/patterns/*.conf" # Retrieves all .conf files in the directory.
Configuration with multiple files:
patterns_dir => ["/etc/logstash/patterns/mellanox_grok.conf", "/etc/logstash/patterns/ibm_grok.conf"]
CSM Event Correlator will load the default Logstash patterns regardless of the contents of this field.
Pattern files are plain text with the following format:
NAME PATTERN
For example:
GUID [0-9a-f]{16}
The patterns are loaded on pipeline creation.
named_captures_only¶
| Value type: | boolean |
|---|---|
| Default value: | true |
If true only store captures that have been named for grok. Anonymous captures are considered named.
CSM Event Correlator Event Configuration File¶
CSM Event Correlator uses a YAML file for configuration. The YAML configuration is
heirarchical with 3 major groupings:
This is a sample configuration of this file:
---
# Metadata
ras_create_url: "/csmi/V1.0/ras/event/create"
csm_target: "localhost"
csm_port: 4213
data_sources:
# Data Sources
syslog:
ras_location: "syslogHostname"
ras_timestamp: "timestamp"
event_data: "message"
category_key: "programName"
categories:
# Categories
NVRM:
- tag: "XID_GENERIC"
pattern: "Xid(%{DATA:pciLocation}): %{NUMBER:xid:int},"
ras_msg_id: "gpu.xid.%{xid}"
action: 'unless %{xid}.between?(1, 81); ras_msg_id="gpu.xid.unknown" end; .send_ras;'
mlx5_core:
- tag: "IB_CABLE_PLUG"
pattern: "mlx5_core %{MLX5_PCI}.*module %{NUMBER:module}, Cable (?<cableEvent>(un)?plugged)"
ras_msg_id: "ib.connection.%{cableEvent}"
action: ".send_ras;"
mmsysmon:
- tag: "MMSYSMON_CLEAN_MOUNT"
pattern: "filesystem %{NOTSPACE:filesystem} was (?<mountEvent>(un)?mounted)"
ras_msg_id: "spectrumscale.fs.%{mountEvent}"
action: ".send_ras;"
- tag: "MMSYSMON_UNMOUNT_FORCED"
pattern: "filesystem %{NOTSPACE:filesystem} was.*forced.*unmount"
ras_msg_id: "spectrumscale.fs.unmount_forced"
action: ".send_ras;"
...
Metadata¶
The metadata section may be thought of as global configuration options that will apply to all events in the event correlator.
| Field | Input type | Required |
|---|---|---|
| ras_create_url | string | Yes <Initial Release> |
| csm_target | string | Yes <Initial Release> |
| csm_port | integer | Yes <Initial Release> |
| data_sources | map | Yes |
ras_create_url¶
| Value type: | string |
|---|---|
| Sample value: | /csmi/V1.0/ras/event/create |
Specifies the REST create resource on the node runnning the CSM REST Daemon. This path will be used by the .send_ras; utility.
Attention
In a future release /csmi/V1.0/ras/event/create will be the default value.
csm_target¶
| Value type: | string |
|---|---|
| Sample value: | 127.0.0.1 |
A server running the CSM REST daemon. This server will be used to generate ras events with the .send_ras; utility.
Attention
In a future release 127.0.0.1 will be the default value.
csm_port¶
| Value type: | integer |
|---|---|
| Sample value: | 4213 |
The port on the server running the CSM REST daemon. This port will be used to connect by the .send_ras; utility.
Attention
In a future release 4213 will be the default value.
data_sources¶
| Value type: | map |
|---|
A mapping of data sources to event correlation rules. The key of the data_sources field matches type field of the logstash event processed by the filter plugin. The type field may be set in the input section of the logstash configuration file.
Below is an example of setting the type of all incoming communication on the 10515 tcp port to have the syslog type:
input {
tcp {
port => 10515
type => "syslog"
}
}
The YAML configuration file for the syslog data source would then look something like this:
syslog:
# Event Data Sources configuration settings.
# More data sources.
The YAML configuration uses this structure to reduce the pattern space for event matching. If the user doesn’t configure a type in this data_sources map CSM will discard events of that type for consideration in event correlation.
Data Sources¶
Event data sources are entries in the data_sources map. Each data source has a set of configuration options which allow the event correlator to parse the structured data of the logstash event being checked for event corelation/action generation.
This section has the following configuration fields:
| Field | Input type | Required |
|---|---|---|
| ras_location | string | Yes <Initial release> |
| ras_timestamp | string | Yes <Initial release> |
| event_data | string | Yes |
| category_key | string | Yes |
| categories | map | Yes |
ras_location¶
| Value type: | string |
|---|---|
| Sample value: | syslogHostname |
Specifies a field in the logstash event received by the filter. The contents of this field are then used to generate the ras event spawned with the .send_ras; utility.
The referenced data is used in the location_name of the of the REST payload sent by .send_ras;.
For example, assume an event is being processed by the filter. This event has the field syslogHostname populated at some point in the pipeline’s execution to have the value of cn1. It is determined that this event was worth responding to and a RAS event is created. Since ras_location was set to syslogHostname the value of cn1 is POSTed to the CSM REST daemon when creating the RAS event.
ras_timestamp¶
| Value type: | string |
|---|---|
| Sample value: | timestamp |
Specifies a field in the logstash event received by the filter. The contents of this field are then used to generate the ras event spawned with the .send_ras; utility.
The referenced data is used in the time_stamp of the of the REST payload sent by .send_ras;.
For example, assume an event is being processed by the filter. This event has the field timestamp populated at some point in the pipeline’s execution to have the value of Wed Feb 28 13:51:19 EST 2018. It is determined that this event was worth responding to and a RAS event is created. Since ras_timestamp was set to timestamp the value of Wed Feb 28 13:51:19 EST 2018 is POSTed to the CSM REST daemon when creating the RAS event.
event_data¶
| Value type: | string |
|---|---|
| Sample value: | message |
Specifies a field in the logstash event received by the filter. The contents of this field are matched against the specified patterns.
Attention
This is the data checked for event correlation once the event list has been selected, make sure the correct event field is specified.
category_key¶
| Value type: | string |
|---|---|
| Sample value: | programName |
Specifies a field in the logstash event received by the filter. The contents of this field are used to select the category in the categories map.
categories¶
| Value type: | map |
|---|
A mapping of data sources categories to event correlation rules. The key of the categories field matches field specified by category_key. In the included example this is the program name of a syslog event.
This mapping exists to reduce the number of pattern matches performed per event. Events that don’t have a match in the categories map are ignored when performing further pattern matches.
Each entry in this map is an array of event correlation rules with the schema described in Event Categories. Please consult the sample for formatting examples for this section of the configuration.
Event Categories¶
Event categories are entries in the categories map. Each category has a list of tagged configuration options which specify an event correlation rule.
This section has the following configuration fields:
| Field | Input type | Required |
|---|---|---|
| tag | string | No |
| pattern | string | Yes <Initial Release> |
| action | string | Yes <Initial Release> |
| extract | boolean | No |
| ras_msg_id | string | No <Needed for RAS> |
tag¶
| Value type: | string |
|---|---|
| Sample value: | XID_GENERIC |
A tag to identify the event correlation rule in the plugin. If not specified an internal identifier will be specified by the plugin. Tags starting with . will be rejected at the load phase as this is a reserved pattern for internal tag generation.
Note
In the current release this mechanism is not fully implemented.
pattern¶
| Value type: | string |
|---|---|
| Sample value: | mlx5_core %{MLX5_PCI}.*module %{NUMBER:module}, Cable (?<cableEvent>(un)?plugged) |
A grok based pattern, follows the rules specified in Grok Primer. This pattern will save any pattern match extractions to the event travelling through the pipeline. Additionally, any extractions will be accessible to the action to drive behavior.
action¶
| Value type: | string |
|---|---|
| Sample value: | unless %{xid}.between?(1, 81); ras_msg_id=”gpu.xid.unknown” end; .send_ras; |
A ruby script describing an action to take in response to an event. The action is taken when an event is matched. The plugin will compile these scripts at load time, cancelling the startup if invalid scripts are specified.
This script follows the rules specified in CSM Event Correlator Action Programming.
extract¶
| Value type: | boolean |
|---|---|
| Default value: | false |
By default the Event Correlator doesn’t save the extract pattern matches in pattern to the final event shipped to elastic search or your big data platform of choice. To save the pattern extraction this field must be set to true.
Note
This field does not impact the writing of action scripts.
ras_msg_id¶
| Value type: | string |
|---|---|
| Sample value: | gpu.xid.%{xid} |
A string representing the ras message id in event creation. This string may specify fields in the event object through use of the %{FIELD_NAME} pattern. The plugin will attempt to populate the string using this formatting before passing to the action processor.
For example, if the event has a field xid with value 42 the pattern gpu.xid.%{xid} will resolve to gpu.xid.42.
Grok Primer¶
CSM Event Correlator uses grok to drive pattern matching.
Grok is a regular expression pattern checking utility. A typical grok pattern has the following syntax: %{PATTERN_NAME:EXTRACTED_NAME}
PATTERN_NAME is the name of a grok pattern specified in a pattern file or in the default Logstash pattern space. Samples include NUMBER, IP and WORD.
EXTRACTED_NAME is the identifier to be assigned to the text in the event context. The EXTRACTED_NAME will be accessible in the action through use of the %{EXTRACTED_NAME} pattern as described later. EXTRACTED_NAME identifiers are added to the big data record in elasticsearch. The EXTRACTED_NAME section is optional, patterns without the EXTRACTED_NAME are matched, but not extracted.
For specifying custom patterns refer to custom patterns.
A grok pattern may also use raw regular expressions to perform non-extracting pattern matches. Anonymous extraction patterns may be specified with the following syntax: (?<EXTRACTED_NAME>REGEX)
EXTRACTED_NAME in the anonymous extraction pattern is identical to the named pattern. REGEX is a standard regular expression.
CSM Event Correlator Action Programming¶
Programming actions is a central part of the CSM Event Correlator. This plugin supports action scripting using ruby. The action script supplied to the pipeline is converted to an anonymous function which is invoked when the event is processed.
Default Variables¶
The action script has a number of variables which are acessible to action writers:
| Variable | Type | Description |
|---|---|---|
| event | LogStash::Event | The event the action is generated for, getters provided. |
| ras_msg_id | string | The ras message id, formatted. |
| ras_location | string | The location the RAS event originated from, parsed from event. |
| ras_timestamp | string | The timestamp to assign to the RAS event. |
| raw_data | string | The raw data which generated the action. |
The user may directly influence any of these fields in their action script, however it is recommended that the user take caution when manipulating the event as the contents of this field are ultimately written to any Logstash targets. The event members may be accessed using the %{field} syntax.
The ras_msg_id, ras_location, ras_timestamp, and raw_data fields are used with the .send_ras; action keyword.
Accessing Event Fields¶
Event fields are commonly used to drive event actions. These fields may be specified by the event corelation rule or other Logstash plugins. Due to the importance of this pattern the CSM Event Correlator provides a special syntaxtic sugar for field access %{FIELD_NAME}.
This syntax is interpreted as event.get(FIELD_NAME) where the field name is a field in the event. If the field was not present the field will be interpreted as nil.
Action Keywords¶
Several action keywords are provided to abstract or reduce the code written in the actions. Action keywords always start with a . and end with a ;.
.send_ras;¶
Creates a ras event with msg_id == ras_msg_id, location_name == ras_location, time_stamp == ras_timestamp, and raw_data == raw_data.
Currently only issues RESTful create requests. Planned improvements add local calls.
Attention
A clarification for this section will be provided in the near future. (5/18/2018 jdunham@us.ibm.com)
Sample Action¶
- Using the above tools an action may be written that:
Processes a field in the event, checking to see it’s in a valid range.
unless %{xid}.between?(1, 81);
Sets the message id to a default value if the field is not within range.
ras_msg_id="gpu.xid.unknown" end;
Generate a ras message with the new id.
.send_ras;
All together it becomes:
unless %{xid}.between?(1, 81); ras_msg_id="gpu.xid.unknown" end; .send_ras;
This action script is then compiled and stored by the plugin at load time then executed when actions are triggered by events.
Debugging Issues¶
Perform the following checks in order, when a matching condition is found, exit the debug process and handle that condition. Numbered sequences assume that the user performs each step in order.
RAS Event Not Firing¶
If RAS events haven’t been firing for conditions matching .send_ras perform the following diagnostic steps:
Check the `/var/log/logstash/logstash-plain.log`
Search for the phrase “Unable send RAS event” :
This indicates that the corelator was unable to connect to the CSM REST Daemon. Verify that Daemon is running on the specified hostname and port.
Search for the phrase “Posting ras message” :
This indicates that the corelator connected to the CSM REST Daemon, but the RAS events were malconfigured. Verify that the message id sent has an analog in the list of RAS events registered in CSM.
The RAS mesage id may be checked using the following utility:
csm_ras_msg_type_query -m "MESSAGE_ID"Neither of these strings were found:
Cast Search¶
The cast search mechanism is a GUI utility for searching for allocations in the Big Data Store.
Installation¶
Installation of the CAST Search plugin is performed through the ibm-csm-bds-kibana-*.noarch.rpm rpm:
rpm -ivh ibm-csm-bds-kibana-*.noarch.rpm
Attention
Kibana must be installed first please refer to the :ref: cast-kibana documentation.
Configuration¶
After installing the plugin the following steps must be taken to begin using the plugin.
- Select the Management tab from the sidebar:
- Select the Kibana Index Patterns:

3. If the cast-allocation index pattern is not present create a new index pattern. If the index pattern is present skip to Step Seven:
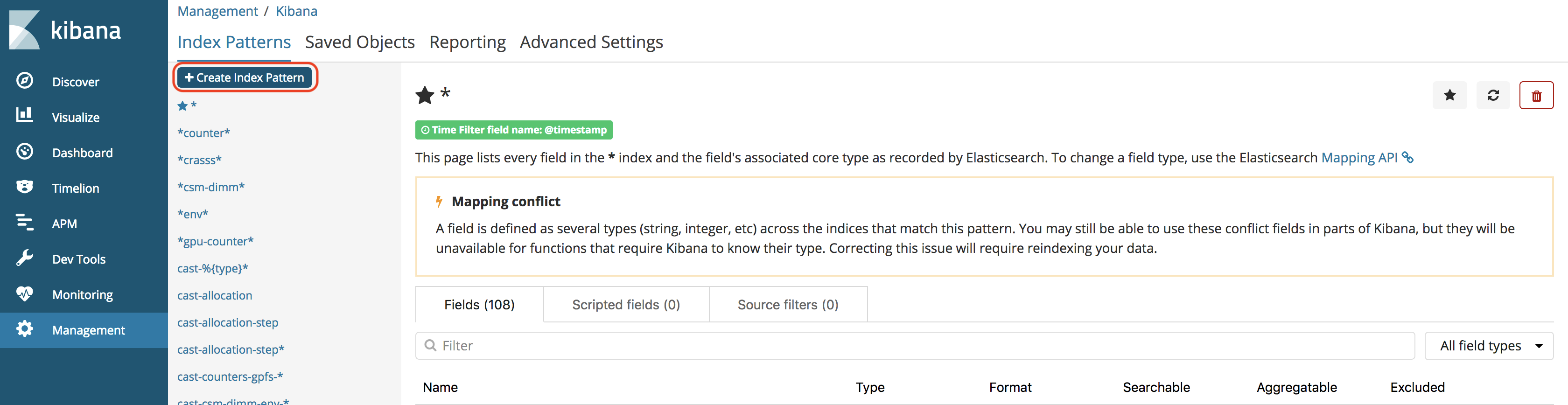
- Input cast-allocation in the index pattern name:
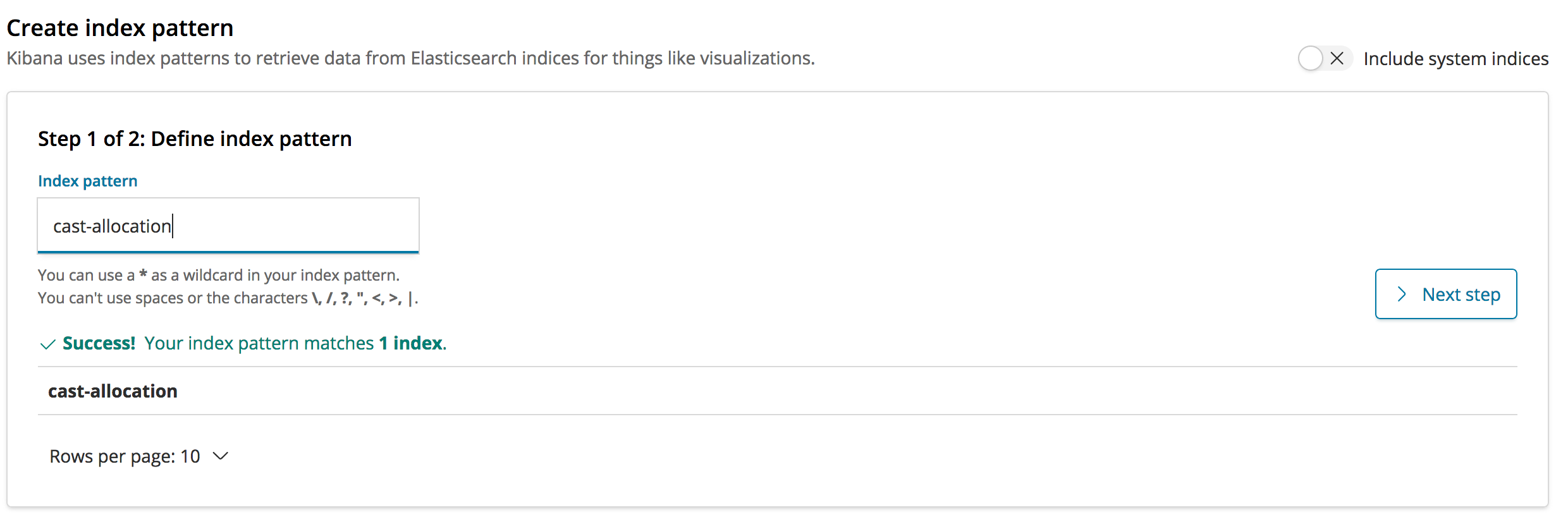
- Select @timestamp for the time filter (this will sort records by update date by default:

- Verify that the cast-allocation index pattern is now present:
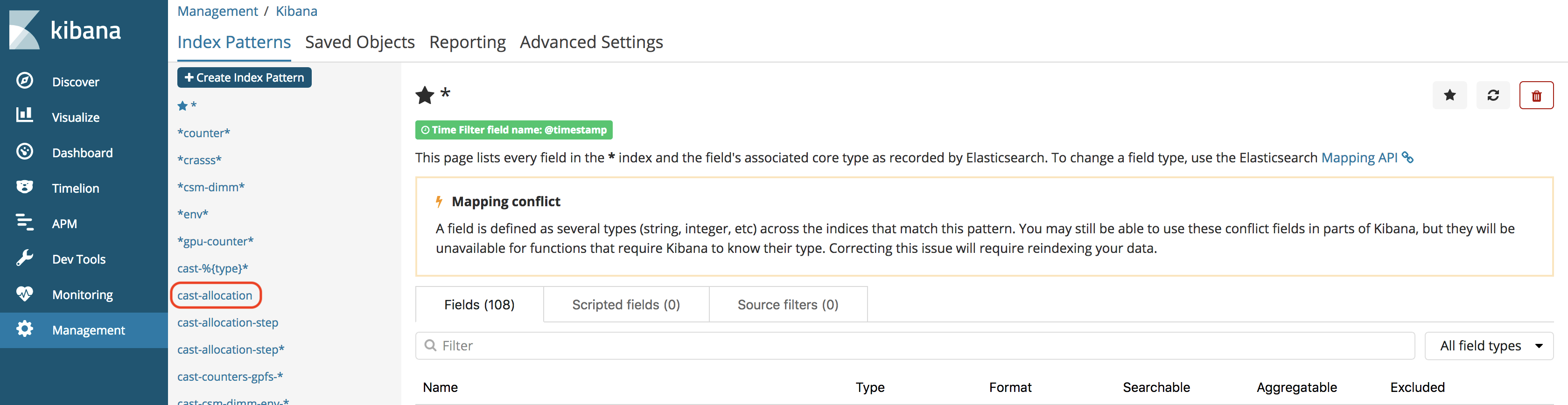
- Select the Visualize sidebar tab, then select the CAST Search option:
8. Select the add option, by default this will select the Allocation ID option. If the user wishes to search on Job IDs, select Job ID in the dropdown.

- A listing of fields should now be visible. Select the Apply changes button before saving the visualization:

- Save the Visualization so the plugin may be used from a dashboard:

- Select the Dashboard sidebar tab, then create a new dashboard:

- Select the Add option, then select the visualizer created in Step Ten and Add new Visualization:
- The plugin should now be usable:
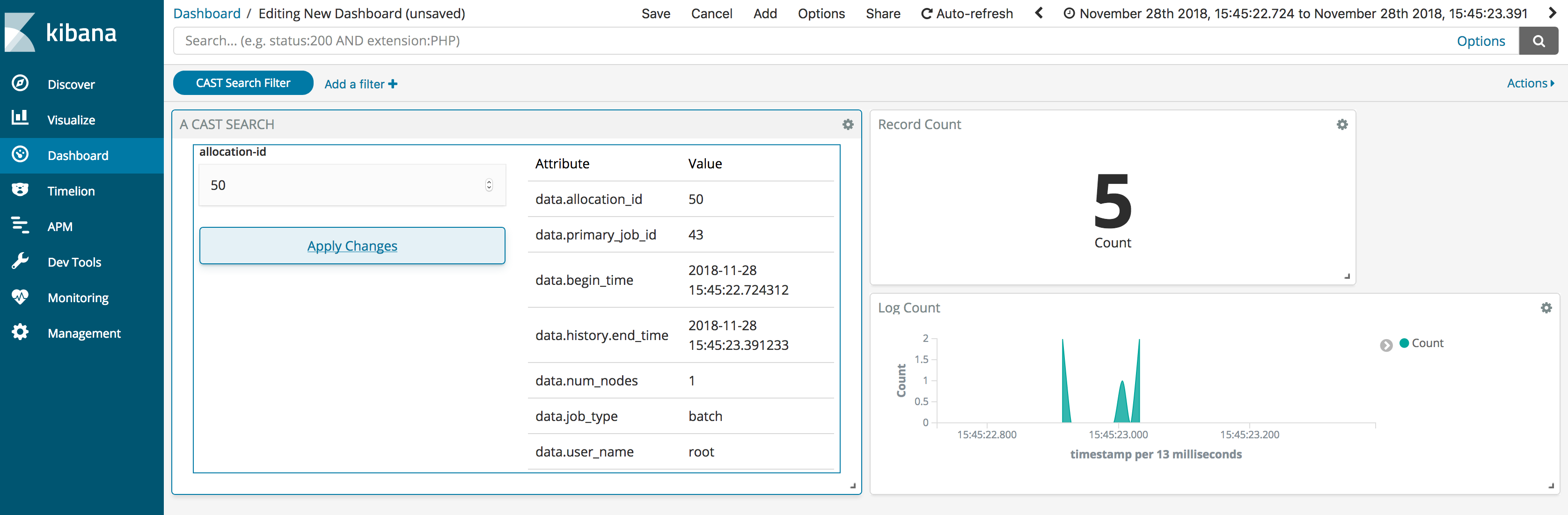
Releases¶
Release 1.6.0¶
| GitHub Tag: |
|---|
CSM APIs¶
- The API
csm_ib_cable_queryhas been updated to take on a search by filtering theme. It will now return all ib cables by default, and filter results based off of additional input the user provides. - UFM guids are now more uniformly represented across CSM. As a result some APIs were updated to conform to these new standards.
- Some updates to UFM restAPIs caused CSM APIs to crash inbetween CSM 1.5.0 and CSM 1.6.0. These issues were resolved in CSM 1.5.x patch updates and are included in the main release of CSM 1.6.0.
- UFM updates required changes to CSM Database tables. As such, some changes to CSM APIs related to these tables needed to be updated and now require CSM DB 18.0 to function correctly.
Release 1.5.0¶
| GitHub Tag: |
|---|
This release primarily targets Jitter Mitigation in the Allocation Create mechanism. Additional QOL fixes are included for BDS, Database, Infrastructure and other CSM systems.
CSM APIs¶
csmi_allocation_t: new fieldsmt_mode- Set in
csm_allocation_create, determines the SMT mode of the job for the allocation. - 0 sets the allocation to use the maximum SMT mode for the node.
- SMT mode values exceeding the node maximum are clamped on the compute node.
- Set in
csm_allocation_createandcsm_allocation_update_statenow only create onecsm_allocation_node_historyentry per allocation.
csm_allocation_query_detailsnow prints all metrics fields, regardless of population.Added a sample showing interface between CSM and xCAT.
CSM BDS¶
- New metric-transaction_140-150.py script in git repo for fixing historic transaction logs.
sourcefield moved todataformetric-transactionlogs.@timestampfields generated by CSM transitioned totimestamp.- Added RAS event triggering for UFM in default event correlation configuration.
csm_transaction.log- Now rolls over into multiple files with an auto incrementing number.
- Fixed CSM failure to report all allocated nodes.
- General fix for bad JSON.
dynamic_date_formatsbug now fixed, should repair some issues with timestamps.filebeat.prospectorsin sample config renamed tofilebeat.inputs.
CSM Daemon¶
- Added jitter mitigation block to csm compute configuration.
- For details on this mechanism see linked documentation.
libcsmpam.so- No longer prints during session module usage.
Activelistnow created if not found.
- Fix for client race condition: socket tear-down and pending send/recv.
- DB version mismatch exits more gracefully.
CSM Database¶
- Added new Migration script for 16.2 to 17.0.
smt_modeadded tocsm_allocationandcsm_allocation_history.num_readsandnum_writesadded tocsm_lv_history.
RPMS¶
- Added
csm-tools-*.noarch.rpmRPM. - Collects noarch tools for CSM utilities.
numpydependency.
- Added
- Added minimum version (2.5.1) to
python-psycopg2forcsm-db-*.rpm. - Added
python-psycopg2andpython-elasticsearchdependecies toibm-csm-bds-*.noarch.rpm. - Fixed
ibm-csm-bds-logstash-*.noarch.rpmandibm-csm-bds-kibana-*.noarch.rpmrpm scriptlets.